
Flink实战 - Binlog日志并对接Kafka实战
点击上方蓝色字体,选择“设为星标”





对于 Flink 数据流的处理,一般都是去直接监控 xxx.log 日志的数据,至于如何实现关系型数据库数据的同步的话网上基本没啥多少可用性的文章,基于项目的需求,经过一段时间的研究终于还是弄出来了,写这篇文章主要是以中介的方式记录下来,也希望能帮助到在做关系型数据库的实时计算处理流的初学者。
一、设计流程图

二、MySQL 的 Binlog 日志的设置
找到 MySQL 的配置文件并编辑:
[root@localhost etc]# vim /etc/my.cnf
[mysqld]
# 其它配置省略。。。。。。
lower_case_table_names=1
## Replication
server_id =2020041006 # 唯一
log_bin =mysql-bin-1 # 唯一
relay_log_recovery =1
binlog_format =row # 格式必须是 row,否则 ogg 监控有问题
master_info_repository =TABLE
relay_log_info_repository =TABLE
#rpl_semi_sync_master_enabled =1
rpl_semi_sync_master_timeout =1000
rpl_semi_sync_slave_enabled =1
binlog-do-db =dsout # 要生成binlog 的数据库
sql_mode=NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES
这里注意的是配置完 my.cnf 文件之后要重启 MySQL 服务器才能生效。查看配置的 状态 和 serverid 命令请参见这篇文章:
三、下载 OGG 并安装部署
下载地址:https://www.oracle.com/middleware/technologies/goldengate-downloads.html
1.下载下来的压缩包解压并放入指定的文件夹中去
mkdir -p /opt/module/ogg/oggservice
tar -xvf ggs_Linux_x64_MySQL_64bit.tar -C /opt/module/ogg/oggservice/
chown -R root:root oggservice/ # 授权成指定的用户及用户组2.进入ogg并启动
cd oggservice/
./ggsci3.源系统的操作步骤及配置信息如下:
GGSCI (localhost.localdomain) 1> create subdirs # 创建目录
GGSCI (localhost.localdomain) 3> dblogin sourcedb dsout@192.168.x.xxx:3306,userid 用户,password 密码; # 监控日志
GGSCI (localhost.localdomain) 3> edit params mgr
port 7015
AUTORESTART EXTRACT *,RETRIES 5,WAITMINUTES 3
PURGEOLDEXTRACTS ./dirdat/*,usecheckpoints, minkeepdays 3
GGSCI (localhost.localdomain) 4> edit params ext1 # 抽取进程
EXTRACT ext1
setenv (MYSQL_HOME="/usr/local/mysql")
dboptions host 192.168.x.xx:3306, connectionport 3306
tranlogoptions altlogdest /usr/local/mysql/data/mysql-bin-1.index
SOURCEDB dsout@192.168.x.xx:3306,userid 用户,password 密码
EXTTRAIL ./dirdat/et
dynamicresolution
GETUPDATEBEFORES
NOCOMPRESSDELETES
NOCOMPRESSUPDATES
table dsout.employees;
table dsout.departments;
GGSCI (localhost.localdomain) 5> edit params pump1 # 推送进程
EXTRACT pump1
SOURCEDB dsout@192.168.x.xx:3306,userid 用户,password 密码
RMTHOST 目标服务器的IP地址, MGRPORT 2021
RMTTRAIL ./dirdat/xd
table dsout.*; # 要推送的表
#为数据库的binlog添加监控和推送进程
GGSCI (localhost.localdomain DBLOGIN as dsout) 8> add extract ext1, tranlog,begin now
GGSCI (localhost.localdomain DBLOGIN as dsout) 9> add exttrail ./dirdat/et, extract ext1
GGSCI (localhost.localdomain DBLOGIN as dsout) 10> add extract pump1, exttrailsource ./dirdat/et
GGSCI (localhost.localdomain DBLOGIN as dsout) 11> add rmttrail ./dirdat/rt,extract pump1
# 配置 defgen 进程
GGSCI (localhost.localdomain) 6> edit param defgen
defsfile ./dirdef/defgen.def
sourcedb dsout@192.168.x.xx:3306,userid 用户,password 密码
table dsout.*;
# 生成 defgen.prm 文件
[mysql@localhost oggformysql]$ ./defgen paramfile ./dirprm/defgen.prm
4.进入 ogg 查看各个配置的服务进程:
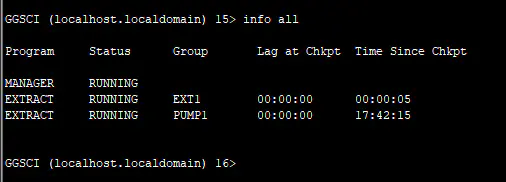
GGSCI (localhost.localdomain) 5> info all效果图如下:

到此为止源系统的ogg已经配置完成,接下来我们要在目标端配置接收到的数据将其以 json 的形式发送到 kafka。
5.解压并授权
mkdir -p /opt/module/ogg/oggservice
tar -xvf OGG_BigData_Linux_x64_19.1.0.0.1.tar -C /opt/module/ogg/oggservice/
chown -R root:root oggservice/6.配置依赖包
find / -name libjvm.so
vim ~/.bash_profile
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b03-1.el7.x86_64/jre/lib/amd64/server/
source ~/.bash_profile7.启动并配置相关进程
cd oggservice/
./ggsci
GGSCI (cdh102) 1> create subdirs
GGSCI (cdh102) 1> edit param mgr # 配置主进程
PORT 2021
ACCESSRULE, PROG *, IPADDR *, ALLOW
GGSCI (cdh102) 2> edit param rep2 # 配置复制进程
replicat rep2
sourcedefs ./dirdef/defgen.def
TARGETDB LIBFILE libggjava.so SET property=./dirprm/kafkaxd.props
MAP dsout.*, TARGET dsout.*;
# (注意,这里的exttrail必须和源端的dump配置一致)
GGSCI (cdh102) 5> add replicat rep2, exttrail ./dirdat/rt8.创建对接 kafka的配置文件
cd ./dirprm
[root@cdh102 dirprm]# vim kafkaxd.props # -> 配置文件内容如下
gg.handlerlist = kafkahandler
gg.handler.kafkahandler.type=kafka
gg.handler.kafkahandler.KafkaProducerConfigFile=xindai_kafka_producer.properties # kafka 生产者属性文件
#######The following resolves the topic name using the short table name
gg.handler.kafkahandler.topicMappingTemplate=xindai-topic # 主题
############The following selects the message key using the concatenated primary keys
############gg.handler.kafkahandler.keyMappingTemplate=${primaryKeys}
###########gg.handler.kafkahandler.format=avro_op
gg.handler.kafkahandler.SchemaTopicName=xindai-topic # 主题
gg.handler.kafkahandler.BlockingSend =false
gg.handler.kafkahandler.includeTokens=false
gg.handler.kafkahandler.mode=op
gg.handler.kafkahandler.format=json
#########gg.handler.kafkahandler.format.insertOpKey=I
#######gg.handler.kafkahandler.format.updateOpKey=U
#########gg.handler.kafkahandler.format.deleteOpKey=D
#######gg.handler.kafkahandler.format.truncateOpKey=T
goldengate.userexit.writers=javawriter
javawriter.stats.display=TRUE
javawriter.stats.full=TRUE
gg.log=log4j
gg.log.level=INFO
gg.report.time=30sec
##########Sample gg.classpath for Apache Kafka 这里一定要指定kafka依赖包的路径
gg.classpath=dirprm/:/opt/cloudera/parcels/CDH-6.3.1-1.cdh6.3.1.p0.1470567/lib/kafka/libs/*
##########Sample gg.classpath for HDP
#########gg.classpath=/etc/kafka/conf:/usr/hdp/current/kafka-broker/libs/*
javawriter.bootoptions=-Xmx512m -Xms32m -Djava.class.path=ggjava/ggjava.jar9.配置 KafkaProducerConfigFile属性文件
[root@cdh102 dirprm]# vim xindai_kafka_producer.properties
bootstrap.servers=cdh101:9092,cdh102:9092,cdh103:9092
acks=1
reconnect.backoff.ms=1000
value.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
key.serializer=org.apache.kafka.common.serialization.ByteArraySerializer
######## 100KB per partition
batch.size=16384
linger.ms=0
key.converter=org.apache.kafka.connect.json.JsonConverter
value.converter=org.apache.kafka.connect.json.JsonConverter
key.converter.schemas.enable=false
value.converter.schemas.enable=false10.启动进程
# 目标端
GGSCI (gpdata) 6> start mgr
GGSCI (gpdata) 7> start rep2
# 源端
GGSCI (localhost.localdomain) 1> start mgr
GGSCI (localhost.localdomain) 2> start ext1
GGSCI (localhost.localdomain) 3> start pump1 # (先起目标的 mgr 才不会报错)效果图如下:
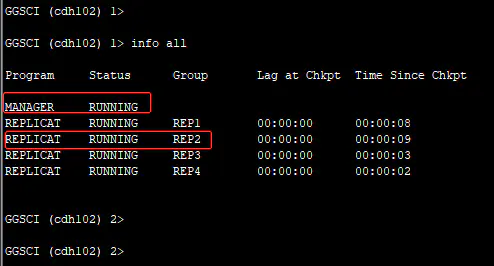
四、验证
1.启动kafka消费者
[root@cdh102 kafka]# bin/kafka-console-consumer.sh --bootstrap-server cdh101:9092,cdh102:9092,cdh103:9092 --topic xindai-topic --from-beginning2.向库的监控表中对数据进行增、删、改 操作
INSERT INTO employees VALUES('101','changyin',6666.66,'2020-05-05 16:12:20','syy01');
INSERT INTO employees VALUES('102','siling',1234.12,'2020-05-05 16:12:20','syy01');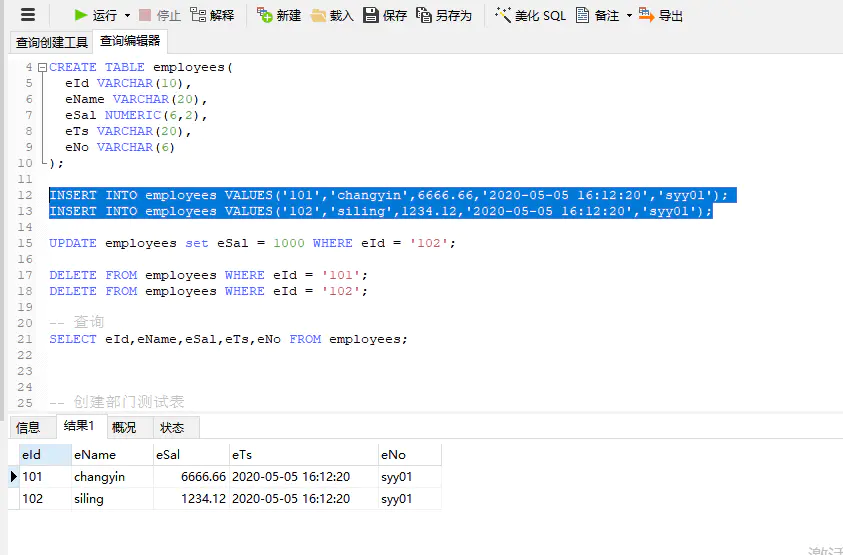
3.查看Kafka消费者的数据

到此,我们已经成功的配置好了 使用 Ogg 监控 MySQL - Binlog 日志,然后将数据以 Json 的形式传给 Kafka 的消费者的整个流程;这是项目实践中总结出来的,为了方便以后查询,在此做了下记录,希望也能帮到志同道合的同学们。


版权声明:
编辑 《大数据技术与架构》
插画 《大数据技术与架构》
文章链接 https://www.jianshu.com/u/b14730fd40bd
文章不错?点个【在看】吧! ?