
干货 | ELK 日志实时分析实战
0、问题来源
1、日志实时分析是 Elasticsearch 三大核心业务场景之一

Elasticsearch架构选型指南——不止是搜索引擎,还有......曾强调:Elasticsearch 三大核心业务场景:
搜索服务场景。
日志实时分析场景。
商业智能 BI 场景。
2、少啰嗦,先看东西
2.1 日志数据准备
以 Python 日志作为数据源,开搞。
在 Python 中,日志记录可以分为 5 种不同级别:
Info — 指定信息性消息,在粗粒度级别突出显示应用程序的进度。
Debug — 指定对调试应用程序最有用的细粒度信息事件。
Warning — 指定警告/告警事件。
Error — 指定已出错,但仍允许应用程序继续运行的事件。
Critical — 指定可能导致应用程序中止的非常严重的错误事件。
日志随机生成 Python 3.X 脚本如下:
import logging
import random
logging.basicConfig(filename="logFile.txt",
filemode='a',
format='%(asctime)s %(levelname)s-%(message)s',
datefmt='%Y-%m-%d %H:%M:%S')
for i in range(0,30):
x=random.randint(0,2)
if(x==0):
logging.warning('Log Message')
elif(x==1):
logging.critical('Log Message')
else:
logging.error('Log Message')
生成日志文件 logFile.txt 部分内容如下:
2021-07-10 21:57:29 ERROR-Log Message
2021-07-10 21:57:29 ERROR-Log Message
2021-07-10 21:57:29 CRITICAL-Log Message
2021-07-10 21:57:29 WARNING-Log Message
2021-07-10 21:57:29 CRITICAL-Log Message
2021-07-10 21:57:29 ERROR-Log Message
2.2 Logstash 数据处理
本文 Logstash、Elasticsearch、Kibana 版本均为:7.12.0。
Logstash 三段论核心:
Input:输入
filter:处理(最最核心)
Output:输出
结合本文日志场景:
input:日志。
filter:日志处理,获取各个细分字段核心内容。
output:输出到 Elasticsearch,以便于后续的 Kibana 数据分析。
input{
file{
path => "/home/elasticsearch/logstash-7.12.0/config/logFile.txt"
start_position => "beginning"
}
}
filter
{
grok{
match => {"message" => "%{TIMESTAMP_ISO8601:timestamp} %{LOGLEVEL:log-level}-%{GREEDYDATA:message}"}
}
date {
match => ["timestamp", "ISO8601"]
}
}
output{
elasticsearch{
hosts => ["172.21.0.14:19022"]
index => "my_log_index"}
stdout{codec => rubydebug}
}
input、output 基本结合字段含义都能看懂。
就中间部分的 grok、date 处理感觉有点云里雾里,我们下一小节拆解讲解。
2.3 数据同步到 Elasticsearch
Logstash 中的 output 环节已经设置输出的索引名称:my_log_index。
同步执行只需要在 logstash 路径下执行如下命令即可:
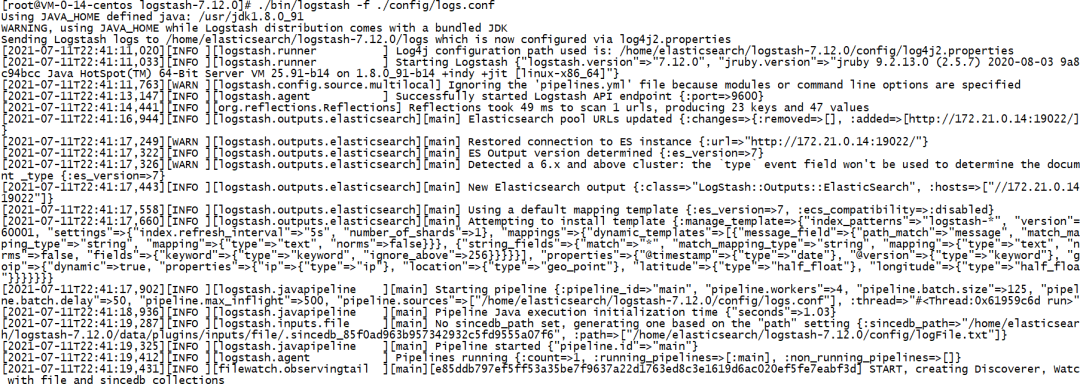
./bin/logstash -f ./config/logs.conf
执行成功截图如下:
导入 Elasticsearch 数据如下:
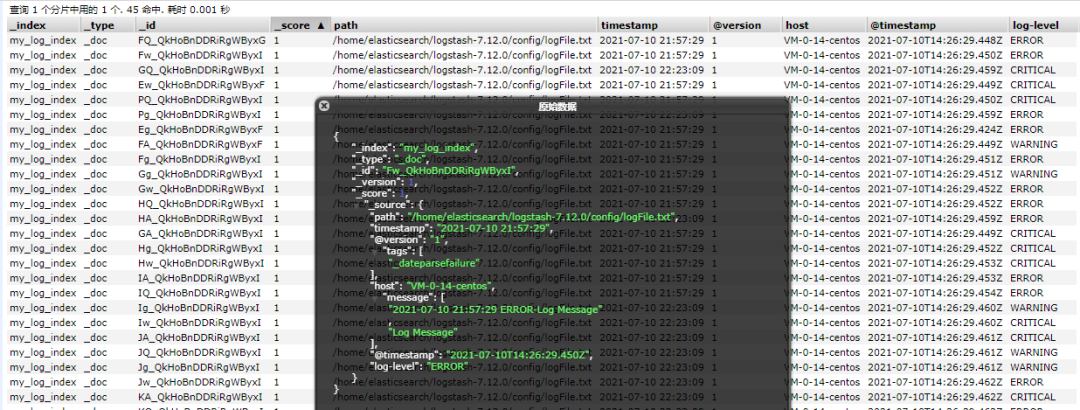
{
"_index" : "my_log_index",
"_type" : "_doc",
"_id" : "FQ_QkHoBnDDRiRgWByxG",
"_score" : 1.0,
"_source" : {
"path" : "/home/elasticsearch/logstash-7.12.0/config/logFile.txt",
"timestamp" : "2021-07-10 21:57:29",
"@version" : "1",
"tags" : [
"_dateparsefailure"
],
"host" : "VM-0-14-centos",
"message" : [
"2021-07-10 21:57:29 ERROR-Log Message",
"Log Message"
],
"@timestamp" : "2021-07-10T14:26:29.448Z",
"log-level" : "ERROR"
}
},
2.4 Kibana 可视化分析
Kibana 可视化分析就是基于日期维度的数据源做分析。
核心步骤如下:
步骤1:创建 index patterns(最关键一步)。
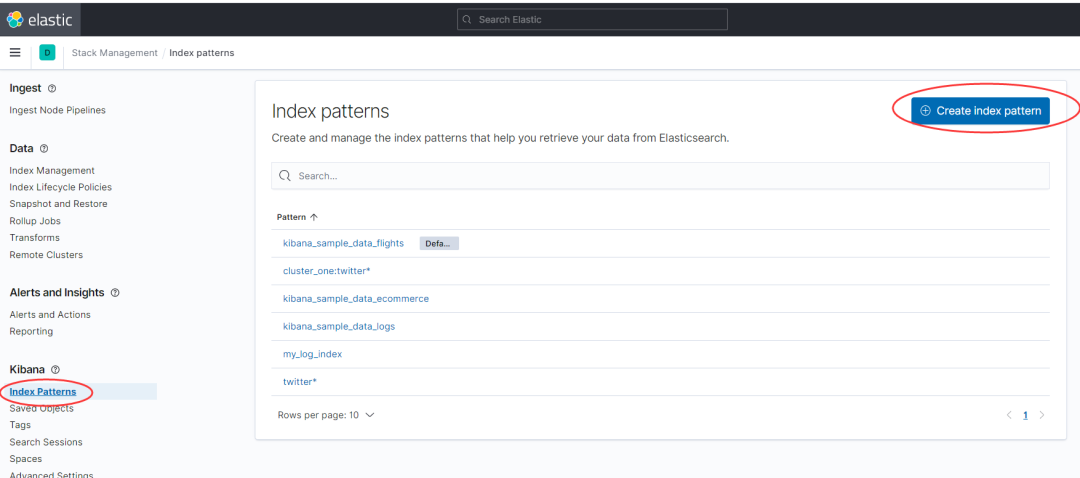
步骤2:Discover 查看数据流(非必须,可直接跳第三步)。
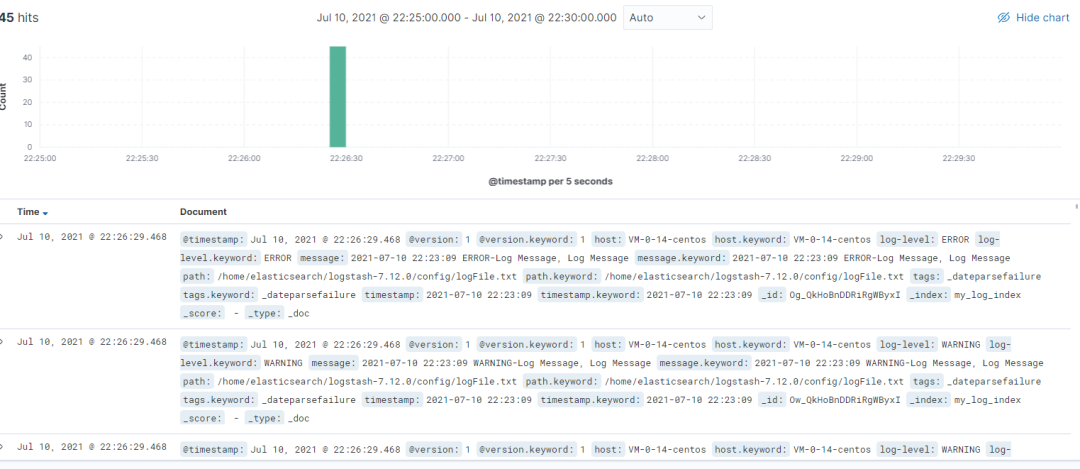
步骤3:日志聚合 Dashboard 分析。
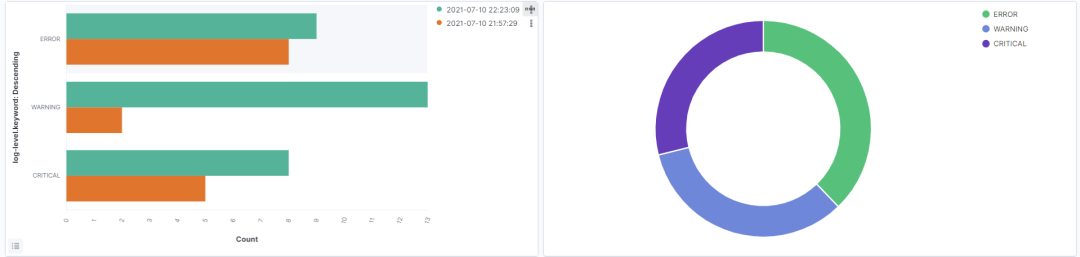
如上三个环节都“中规中矩”、几乎没有坑,不再拆解解读,有问题可以留言讨论。
3、filter 环节核心原理解读
filter 中间处理环节用到了两个核心插件:
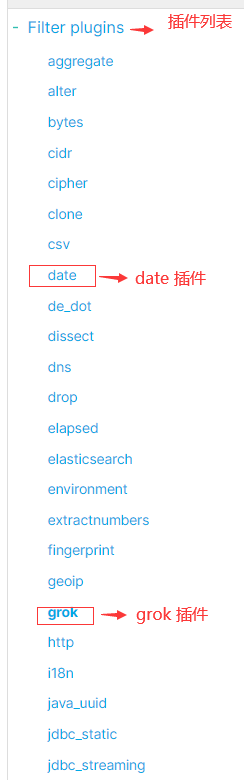
3.1 插件一:date 插件
3.1.1 date 插件定义
date 插件也可以称为:日期过滤器。
用途:用于解析字段中的日期,然后使用该日期或时间戳作为事件的日志记录时间戳。
如下代码代表将:timestamp 字段转换成 ISO8601 数据类型。
date {
match => ["timestamp", "ISO8601"]
}
3.1.2 date 插件适用场景
日期或时间戳类型转换。
3.1.3 date 插件核心参数解读
ISO8601 的本质含义:将日期字段解析为 “2011-04-19T03:44:01.103Z“ 类型。
还有其他类型,诸如:UNIX、UNIX_MS、TAI64N 等。
详细解释参考官方文档:
https://www.elastic.co/guide/en/logstash/current/plugins-filters-date.html
3.2 插件二:grok 插件
3.2.1 grok 插件定义
将非结构化日志数据解析为结构化和可查询的日志。
3.2.2 grok 插件适用场景
适合 syslog 日志、apache 日志和其他网络服务器日志、mysql 日志,以及通常为人类而非计算机使用编写的任何日志格式。
3.2.3 grok 插件附带的 120 + 匹配模式
第一次看 filter 处理环节,不理解:
%{TIMESTAMP_ISO8601:timestamp}
类似语法的含义。
实际上:
TIMESTAMP_ISO8601 就是匹配模式;
timestamp 解析后存储 TIMESTAMP_ISO8601 格式数据的变量,且该变量会作为 elasticsearch Mapping 中的一个字段。
匹配模式的本质其实是:正则表达式。
120 + 匹配模式对应的官方文档:
https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns
本文用到的匹配模式对应的正则表达式如下:
字段说明:
第一列:匹配类型名称。
第二列:匹配的正则表达式。
TIMESTAMP_ISO8601 %{YEAR}-%{MONTHNUM}-%{MONTHDAY}[T ]%{HOUR}:?%{MINUTE}(?::?%{SECOND})?%{ISO8601_TIMEZONE}?
LOGLEVEL ([Aa]lert|ALERT|[Tt]race|TRACE|[Dd]ebug|DEBUG|[Nn]otice|NOTICE|[Ii]nfo?(?:rmation)?|INFO?(?:RMATION)?|[Ww]arn?(?:ing)?|WARN?(?:ING)?|[Ee]rr?(?:or)?|ERR?(?:OR)?|[Cc]rit?(?:ical)?|CRIT?(?:ICAL)?|[Ff]atal|FATAL|[Ss]evere|SEVERE|EMERG(?:ENCY)?|[Ee]merg(?:ency)?)
GREEDYDATA .*
代码面前,了无秘密。
所以,再回头看 filter 语法会很通透。
3.2.4 grok 插件测试工具
为了更方便我们的提前测试,官方也提供了匹配工具,
工具一:一个网站 http://grokdebug.herokuapp.com/。
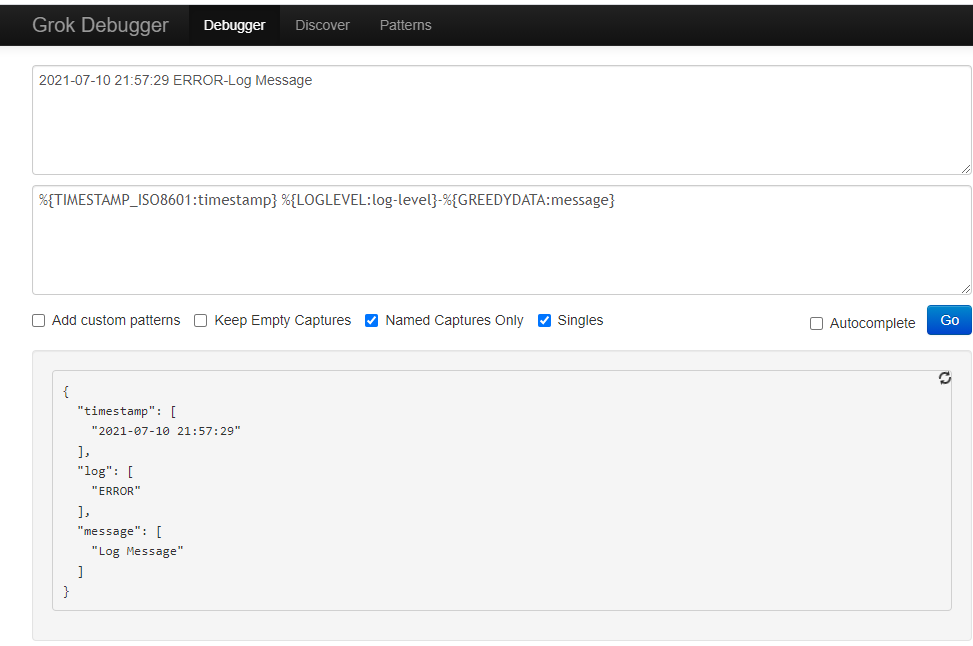
工具二:kibana 自带 Grok Debugger 工具。
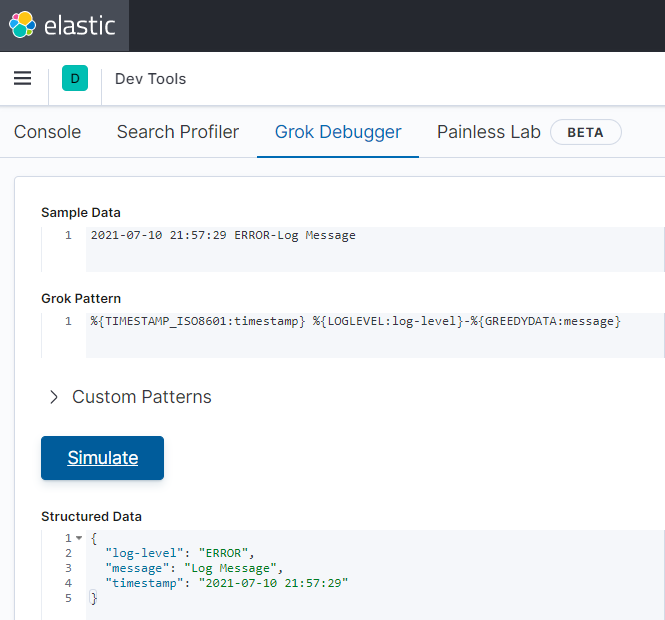
显然,Kibana 自带 Grok Debugger 更为清爽。
4、小结
日志实时分析是 ELK 组件的核心业务场景之一,而核心中的核心是 Logstash 中间处理 filter 环节。
掌握了 filter 环节,就掌握了 ELK 实时日志分析的精髓。
欢迎大家留言讨论自己的 ELK 实战遇到的问题。
参考
https://www.elastic.co/guide/en/logstash/current/filter-plugins.html
https://medium.com/free-code-camp/how-to-use-elasticsearch-logstash-and-kibana-to-visualise-logs-in-python-in-realtime-acaab281c9de