
Kafka 万亿级消息实战
作者:vivo互联网服务器团队-Yang Yijun
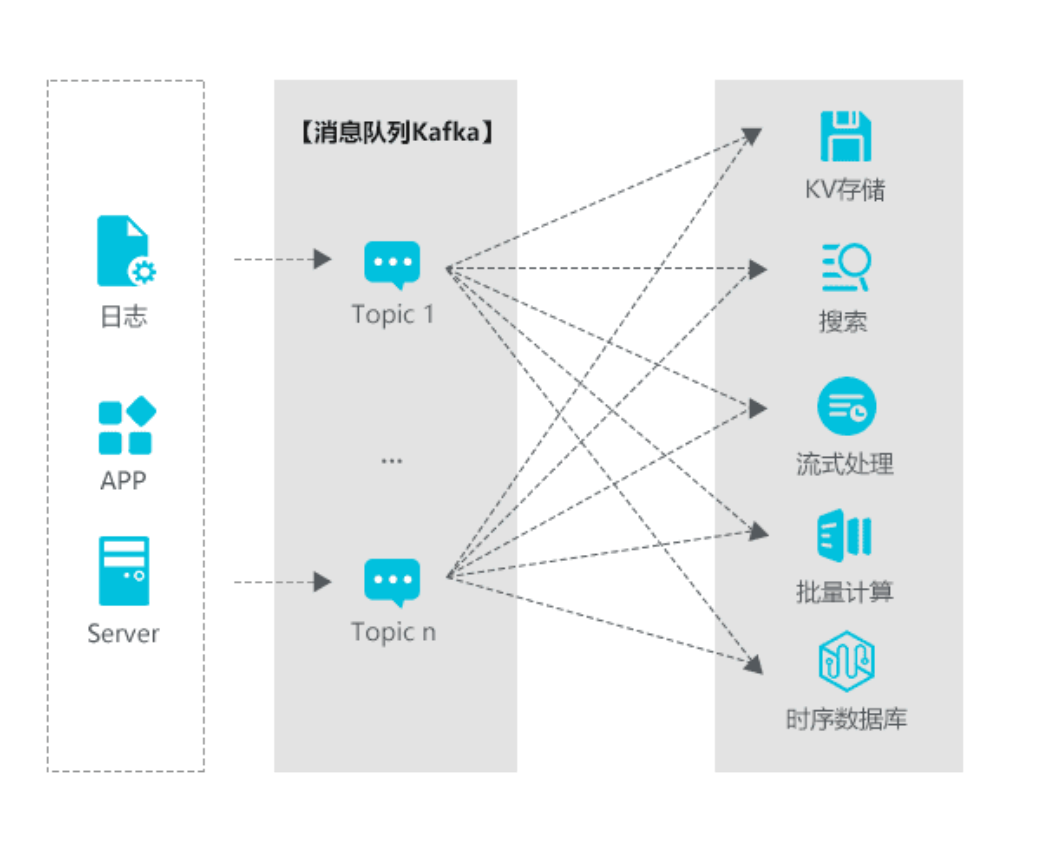
一、Kafka应用
//未指定迁移目录的迁移计划{"version":1,"partitions":[{"topic":"yyj4","partition":0,"replicas":[1000003,1000004]},{"topic":"yyj4","partition":1,"replicas":[1000003,1000004]},{"topic":"yyj4","partition":2,"replicas":[1000003,1000004]}]}
//指定迁移目录的迁移计划{"version":1,"partitions":[{"topic":"yyj1","partition":0,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},{"topic":"yyj1","partition":1,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]},{"topic":"yyj1","partition":2,"replicas":[1000006,1000005],"log_dirs":["/data1/bigdata/mydata1","/data1/bigdata/mydata3"]}]}
/config/users/<user>/clients/<client-id> //根据用户和客户端ID组合限流/config/users/<user>/clients/<default>/config/users/<user>//根据用户限流 这种限流方式是我们最常用的方式/config/users/<default>/clients/<client-id>/config/users/<default>/clients/<default>/config/users/<default>/config/clients/<client-id>/config/clients/<default>
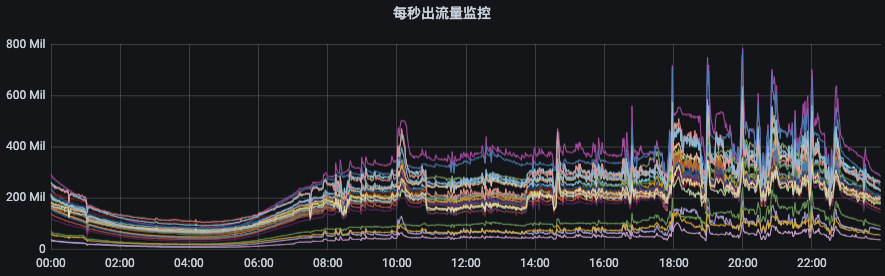
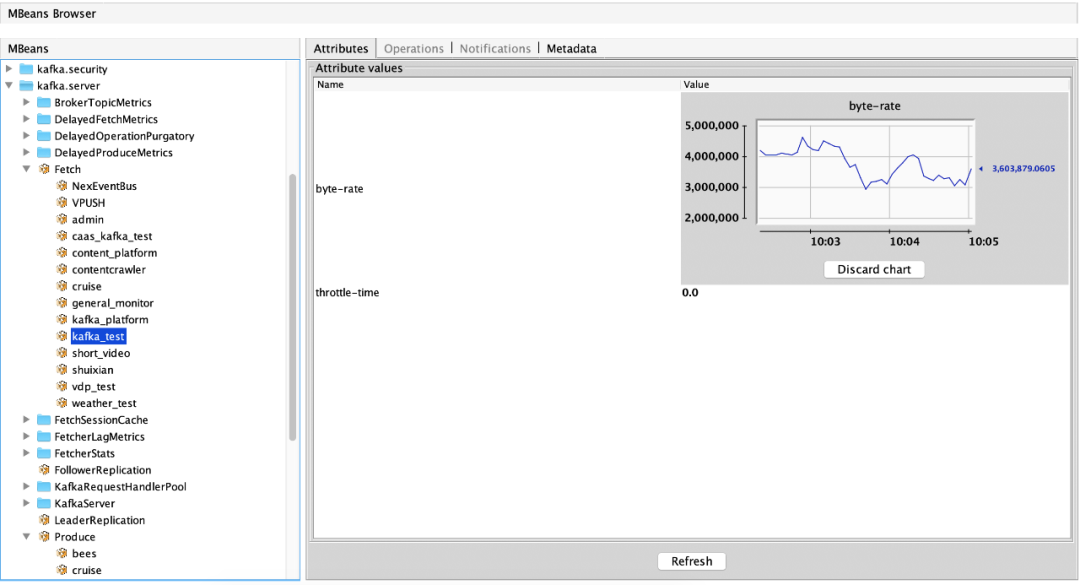
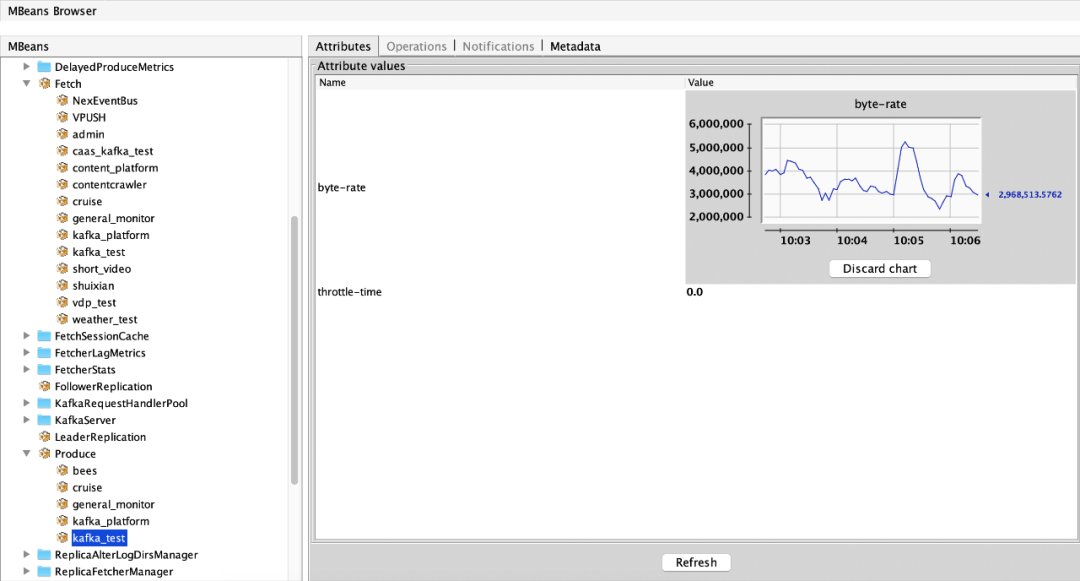
(1)消费流量指标:ObjectName:kafka.server:type=Fetch,user=acl认证用户名称 属性:byte-rate(用户在当前broker的出流量)、throttle-time(用户在当前broker的出流量被限制时间)(2)生产流量指标:ObjectName:kafka.server:type=Produce,user=acl认证用户名称 属性:byte-rate(用户在当前broker的入流量)、throttle-time(用户在当前broker的入流量被限制时间)
//副本同步限流配置共涉及以下4个参数leader.replication.throttled.ratefollower.replication.throttled.rateleader.replication.throttled.replicasfollower.replication.throttled.replicas
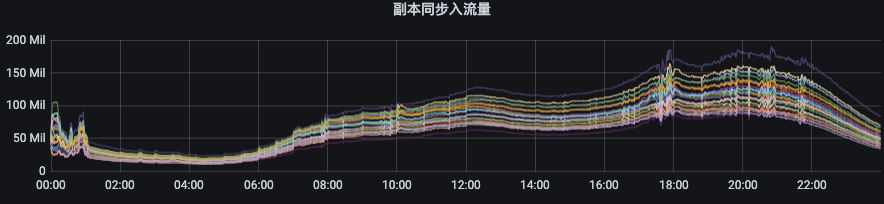
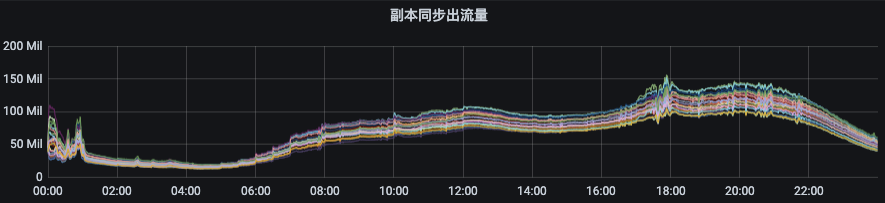
(1)副本同步出流量指标:ObjectName:kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesOutPerSec(2)副本同步入流量指标:ObjectName:kafka.server:type=BrokerTopicMetrics,name=ReplicationBytesInPerSec
Kafka Manager;
Kafka Eagle;
Kafka Monitor;
KafkaOffsetMonitor;
Properties props = new Properties();props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "");props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, IntegerSerializer.class.getName());props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());//ClientMetricsReporter类实现org.apache.kafka.common.metrics.MetricsReporter接口props.put(ProducerConfig.METRIC_REPORTER_CLASSES_CONFIG, ClientMetricsReporter.class.getName());...
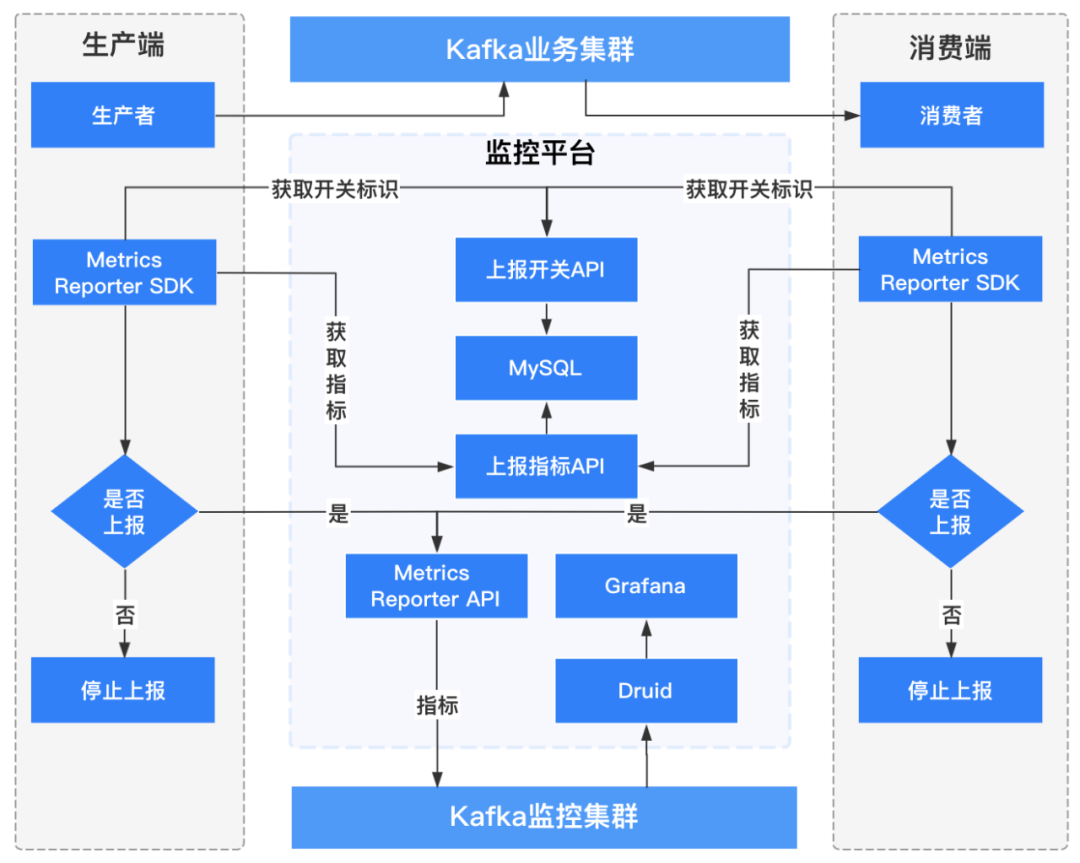
维度:用户名称、客户端ID、客户端IP、topic名称、集群名称、brokerIP; 指标:连接数、IO等待时间、生产流量大小、生产记录数、请求次数、请求延时、发送错误/重试次数等。
维度:用户名称、客户端ID、客户端IP、topic名称、集群名称、消费组、brokerIP、topic分区; 指标:连接数、io等待时间、消费流量大小、消费记录数、消费延时、topic分区消费延迟记录等。
1) Zookeeper进程监控;
2) Zookeeper的leader切换监控;
3) Zookeeper服务的错误日志监控;
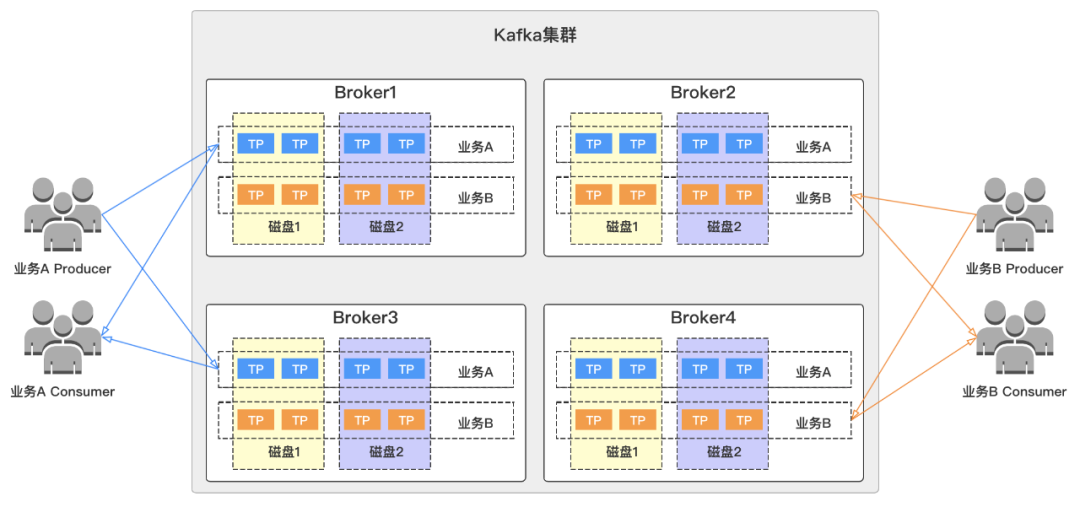
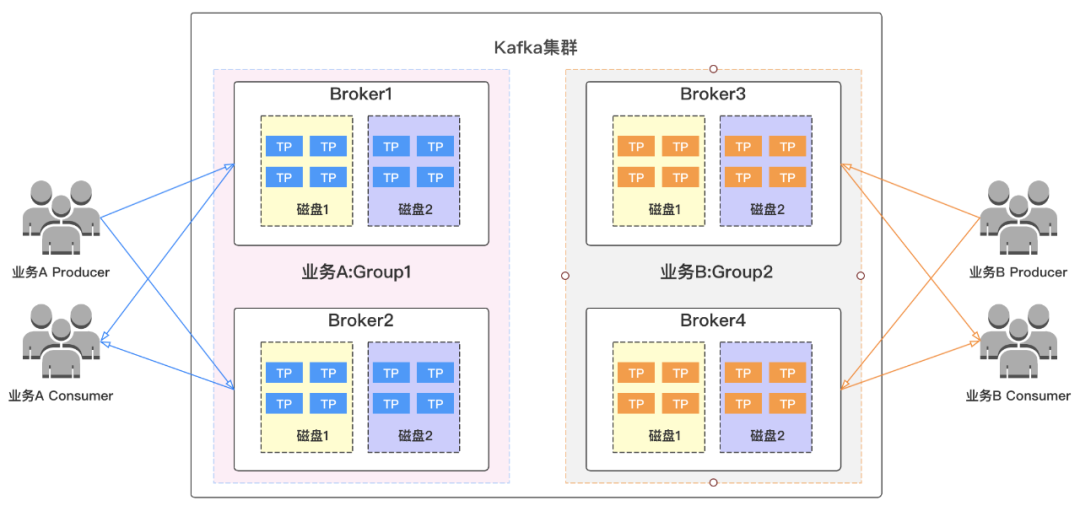
必须保证topic分区leader与follower轮询的分布在资源组内所有broker上,让流量分布更加均衡,同时需要考虑相同分区不同副本跨机架分布以提高容灾能力;
当topic分区leader个数除以资源组节点个数有余数时,需要把余数分区leader优先考虑放入流量较低的broker。
扩容智能评估:根据集群负载,把是否需要扩容评估程序化、智能化;
智能扩容:当评估需要扩容后,把扩容流程以及流量均衡平台化。
一些老化的服务器需要下线,实现节点下线平台化;
服务器故障,broker故障无法恢复,我们需要下线故障服务器,实现节点下线平台化;
有更优配置的服务器替换已有broker节点,实现下线节点平台化。
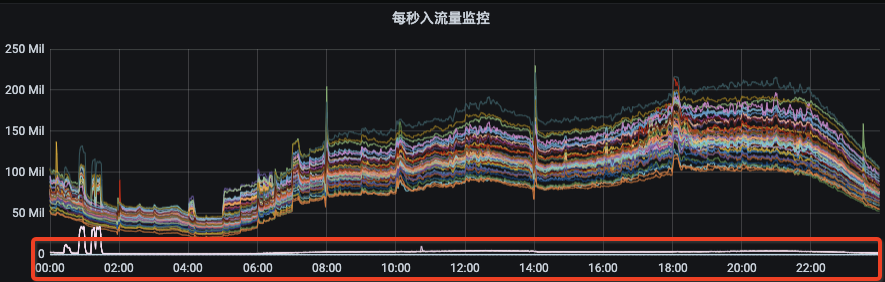
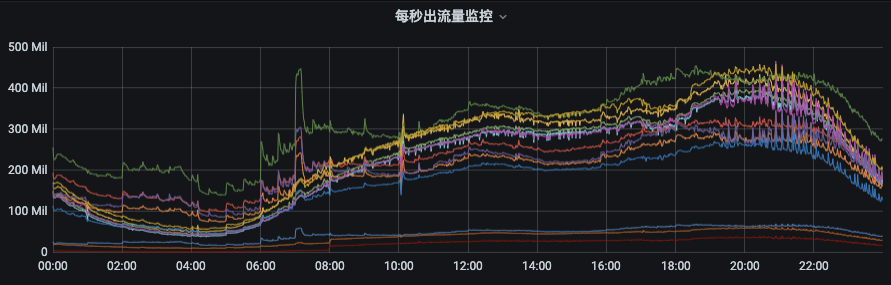
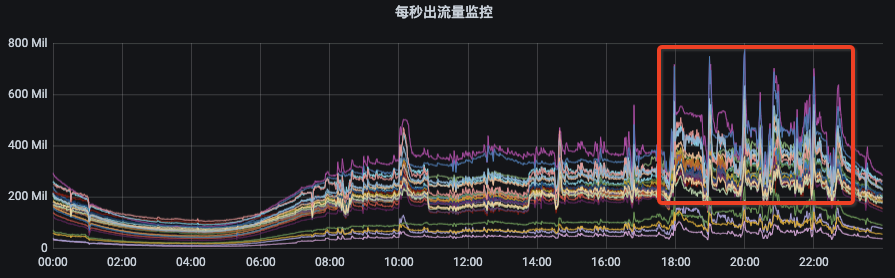
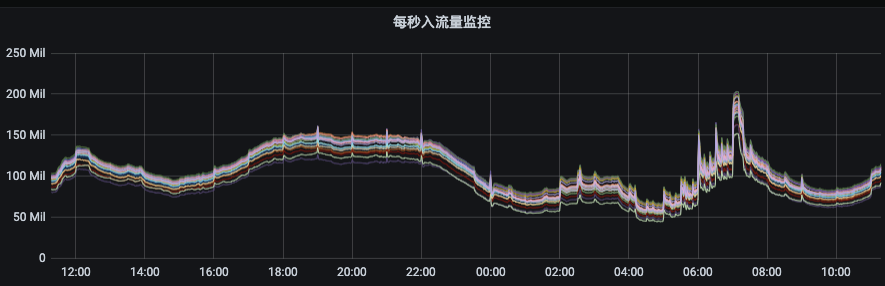
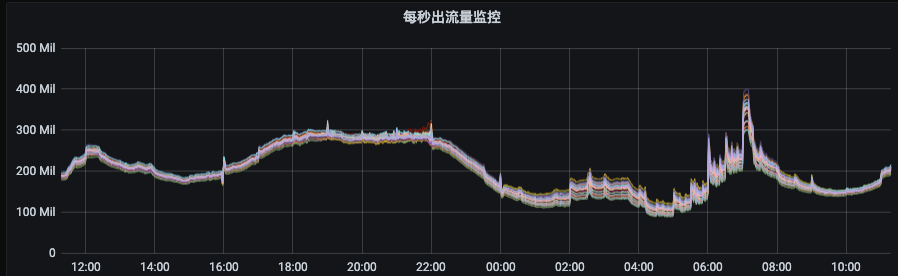
1)生成副本迁移计划以及执行迁移任务平台化、自动化、智能化; 2)执行均衡后broker间流量比较均匀,且单个topic分区均匀分布在所有broker节点上;
3)执行均衡后broker内部多块磁盘间流量比较均衡;
2. Introduction to Kafka Cruise Control
3. Cloudera Cruise Control REST API Reference
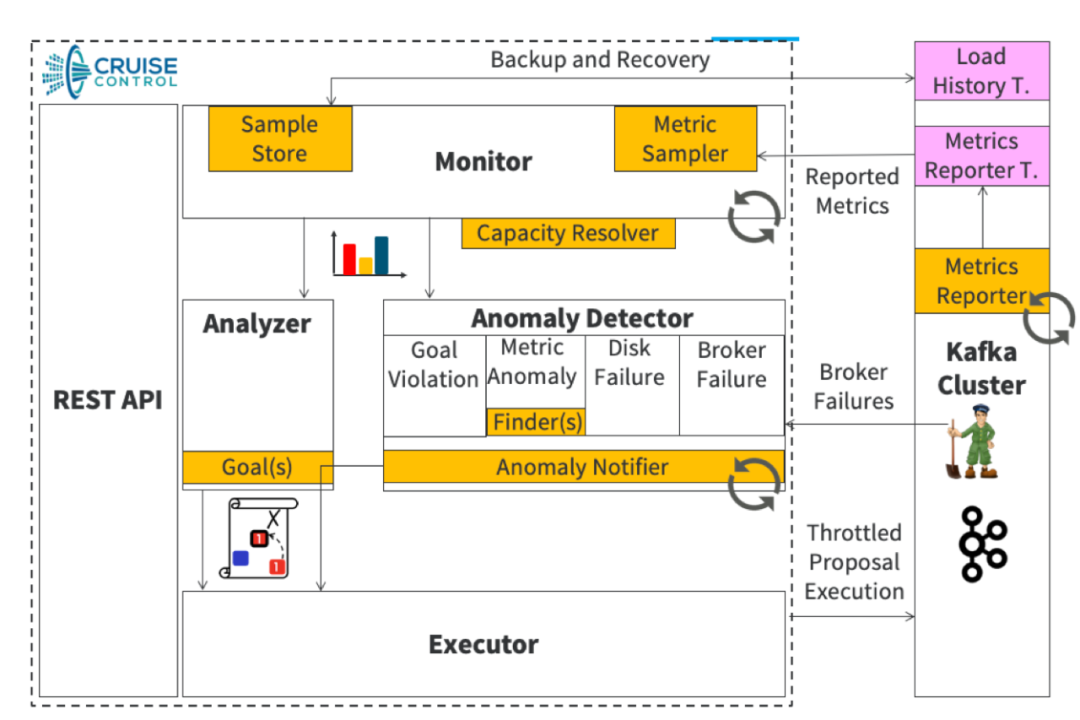
1)选择核心指标作为生成迁移计划的依据,比如出流量、入流量、机架、单topic分区分散性等;
2)优化用来生成迁移计划的指标样本,比如过滤流量突增/突降/掉零等异常样本;
3)各资源组的迁移计划需要使用的样本全部为资源组内部样本,不涉及其他资源组,无交叉;
4)治理单分区过大topic,让topic分区分布更分散,流量不集中在部分broker,让topic单分区数据量更小,这样可以减少迁移的数据量,提升迁移速度;
5)已经均匀分散在资源组内的topic,加入迁移黑名单,不做迁移,这样可以减少迁移的数据量,提升迁移速度;
6)做topic治理,排除长期无流量topic对均衡的干扰;
7)新建topic或者topic分区扩容时,应让所有分区轮询分布在所有broker节点,轮询后余数分区优先分布流量较低的broker;
8)扩容broker节点后开启负载均衡时,优先把同一broker分配了同一大流量(流量大而不是存储空间大,这里可以认为是每秒的吞吐量)topic多个分区leader的,迁移一部分到新broker节点;
9)提交迁移任务时,同一批迁移计划中的分区数据大小偏差应该尽可能小,这样可以避免迁移任务中小分区迁移完成后长时间等待大分区的迁移,造成任务倾斜;
(1)生产者权限认证;
(2)消费者权限认证;
(3)指定数据目录迁移安全认证;
GitHub地址:https://github.com 精确KIP地址 :https://cwiki.apache.org
num.network.threads创建Processor处理网络请求线程个数,建议设置为broker当CPU核心数*2,这个值太低经常出现网络空闲太低而缺失副本。num.io.threads创建KafkaRequestHandler处理具体请求线程个数,建议设置为broker磁盘个数*2num.replica.fetchers建议设置为CPU核心数/4,适当提高可以提升CPU利用率及follower同步leader数据当并行度。compression.type建议采用lz4压缩类型,压缩可以提升CPU利用率同时可以减少网络传输数据量。queued.max.requests如果是生产环境,建议配置最少500以上,默认为500。log.flush.scheduler.interval.mslog.flush.interval.mslog.flush.interval.messages这几个参数表示日志数据刷新到磁盘的策略,应该保持默认配置,刷盘策略让操作系统去完成,由操作系统来决定什么时候把数据刷盘;如果设置来这个参数,可能对吞吐量影响非常大;auto.leader.rebalance.enable表示是否开启leader自动负载均衡,默认true;我们应该把这个参数设置为false,因为自动负载均衡不可控,可能影响集群性能和稳定;
linger.ms#客户端生产消息等待多久时间才发送到服务端,单位:毫秒。和batch.size参数配合使用;适当调大可以提升吞吐量,但是如果客户端如果down机有丢失数据风险;batch.size#客户端发送到服务端消息批次大小,和linger.ms参数配合使用;适当调大可以提升吞吐量,但是如果客户端如果down机有丢失数据风险;compression.type#建议采用lz4压缩类型,具备较高的压缩比及吞吐量;由于Kafka对CPU的要求并不高,所以,可以通过压缩,充分利用CPU资源以提升网络吞吐量;buffer.memory#客户端缓冲区大小,如果topic比较大,且内存比较充足,可以适当调高这个参数,默认只为33554432(32MB)retries#生产失败后的重试次数,默认0,可以适当增加。当重试超过一定次数后,如果业务要求数据准确性较高,建议做容错处理。retry.backoff.ms#生产失败后,重试时间间隔,默认100ms,建议不要设置太大或者太小。
1)topic分区集中落在某几个broker节点上,导致流量副本失衡;
2)导致broker节点内部某几块磁盘读写超负载,存储被写爆;
当topic数据量非常大时,建议一个分区开启一个线程去消费; 对topic消费延时添加监控告警,及时发现处理; 当topic数据可以丢弃时,遇到超大延时,比如单个分区延迟记录超过千万甚至数亿,那么可以重置topic的消费点位进行紧急处理;【此方案一般在极端场景才使用】 避免重置topic的分区offset到很早的位置,这可能造成拉取大量历史数据;
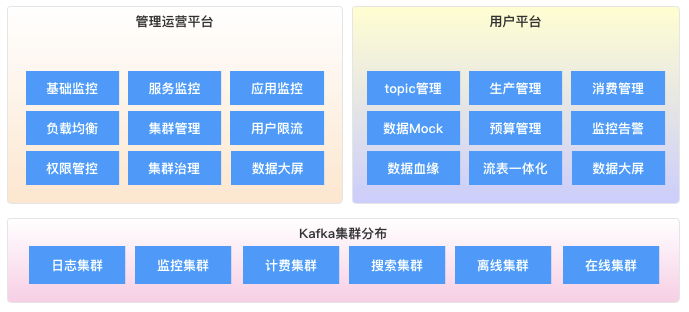
提升操作效率; 操作出错概率更小,集群更安全; 所有操作有迹可循,可以追溯;
在平台上为用户的topic提供生产样例数据与消费抽样的功能,用户可以不用自己写代码也可以测试topic是否可以使用,权限是否正常;
在平台上为用户的topic提供生产/消费权限验证功能,让用户可以明确自己的账号对某个topic有没有读写权限;
1)无流量topic的治理,对集群中无流量topic进行清理,减少过多无用元数据对集群造成的压力;
2)topic分区数据大小治理,把topic分区数据量过大的topic(如单分区数据量超过100GB/天)进行梳理,看看是否需要扩容,避免数据集中在集群部分节点上;
3)topic分区数据倾斜治理,避免客户端在生产消息的时候,指定消息的key,但是key过于集中,消息只集中分布在部分分区,导致数据倾斜;
4)topic分区分散性治理,让topic分区分布在集群尽可能多的broker上,这样可以避免因topic流量突增,流量只集中到少数节点上的风险,也可以避免某个broker异常对topic影响非常大;
5)topic分区消费延时治理;一般有延时消费较多的时候有两种情况,一种是集群性能下降,另外一种是业务方的消费并发度不够,如果是消费者并发不够的化应该与业务联系增加消费并发。
1)把所有指标采集做成平台可配置,提供统一的指标采集和指标展示及告警平台,实现一体化监控; 2)把上下游业务进行关联,做成全链路监控; 3)用户可以配置topic或者分区流量延时、突变等监控告警;
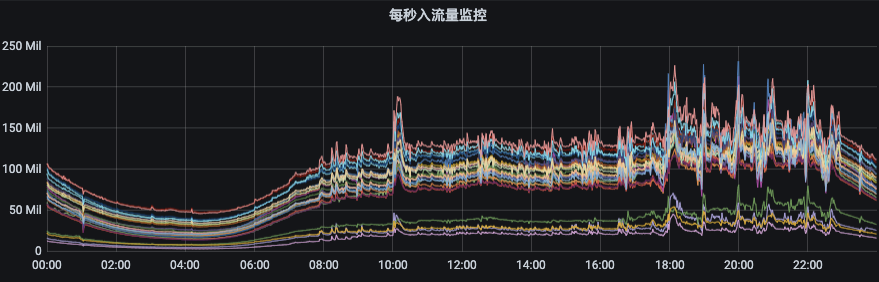
1)为我们进行资源申请评估提供依据; 2)让我们更了解集群的读写能力及瓶颈在哪里,针对瓶颈进行优化; 3)为我们限流阈值设置提供依据; 4)为我们评估什么时候应该扩容提供依据;
1)为我们创建topic时,评估应该指定多少分区合理提供依据; 2)为我们topic的分区扩容评估提供依据;
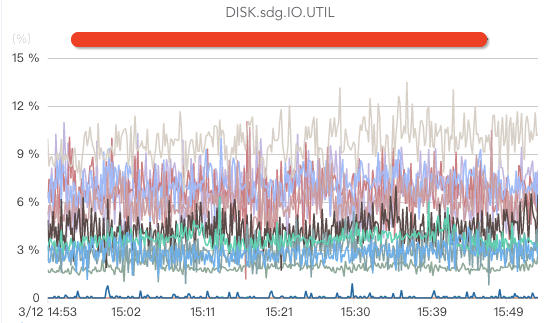
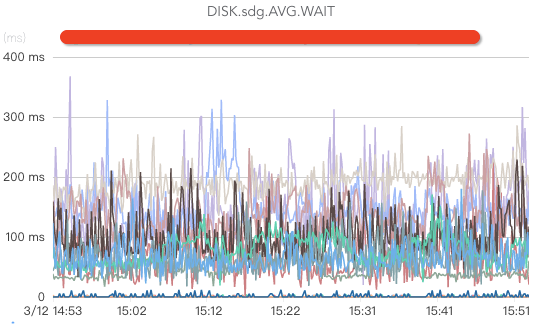
1)为我们了解磁盘的真正读写能力,为我们选择更合适Kafka的磁盘类型提供依据; 2)为我们做磁盘流量告警阈值设置提供依据;
1)我们需要了解单个集群规模的上限或者是元数据规模的上限,探索相关信息对集群性能和稳定性的影响; 2)根据摸底情况,评估集群节点规模的合理范围,及时预测风险,进行超大集群的拆分等工作;
二、开源版本功能缺陷
无法实现增量迁移;【我们已经基于2.1.1版本源码改造,实现了增量迁移】
无法实现并发迁移;【开源版本直到2.6.0才实现了并发迁移】
无法实现终止迁移;【我们已经基于2.1.1版本源码改造,实现了终止副本迁移】【开源版本直到2.6.0才实现了暂停迁移,和终止迁移有些不一样,不会回滚元数据】
当指定迁移数据目录时,迁移过程中,如果把topic保留时间改短,topic保留时间针对正在迁移topic分区不生效,topic分区过期数据无法删除;【开源版本bug,目前还没有修复】
当指定迁移数据目录时,当迁移计划为以下场景时,整个迁移任务无法完成迁移,一直处于卡死状态;【开源版本bug,目前还没有修复】
迁移过程中,如果有重启broker节点,那个broker节点上的所有leader分区无法切换回来,导致节点流量全部转移到其他节点,直到所有副本被迁移完毕后leader才会切换回来;【开源版本bug,目前还没有修复】。
在原生的Kafka版本中存在以下指定数据目录场景无法迁移完毕的情况,此版本我们也不决定修复次bug:1.针对同一个topic分区,如果部分目标副本相比原副本是所属broker发生变化,部分目标副本相比原副本是broker内部所属数据目录发生变化;那么副本所属broker发生变化的那个目标副本可以正常迁移完毕,目标副本是在broker内部数据目录发生变化的无法正常完成迁移;但是旧副本依然可以正常提供生产、消费服务,并且不影响下一次迁移任务的提交,下一次迁移任务只需要把此topic分区的副本列表所属broker列表变更后提交依然可以正常完成迁移,并且可以清理掉之前未完成的目标副本;这里假设topic yyj1的初始化副本分布情况如下:{"version":1,"partitions":[{"topic":"yyj","partition":0,"replicas":[1000003,1000001],"log_dirs":["/kfk211data/data31","/kfk211data/data13"]}]}//迁移场景1:{"version":1,"partitions":[{"topic":"yyj","partition":0,"replicas":[1000003,1000002],"log_dirs":["/kfk211data/data32","/kfk211data/data23"]}]}//迁移场景2:{"version":1,"partitions":[{"topic":"yyj","partition":0,"replicas":[1000002,1000001],"log_dirs":["/kfk211data/data22","/kfk211data/data13"]}]}针对上述的topic yyj1的分布分布情况,此时如果我们的迁移计划为“迁移场景1”或迁移场景2“,那么都将出现有副本无法迁移完毕的情况。但是这并不影响旧副本处理生产、消费请求,并且我们可以正常提交其他的迁移任务。为了清理旧的未迁移完成的副本,我们只需要修改一次迁移计划【新的目标副本列表和当前分区已分配副本列表完全不同即可】,再次提交迁移即可。这里,我们依然以上述的例子做迁移计划修改如下:{"version":1,"partitions":[{"topic":"yyj","partition":0,"replicas":[1000004,1000005],"log_dirs":["/kfk211data/data42","/kfk211data/data53"]}]}这样我们就可以正常完成迁移。
/config/users/<user>/clients/<client-id>/config/users/<user>/clients/<default>/config/users/<user>/config/users/<default>/clients/<client-id>/config/users/<default>/clients/<default>/config/users/<default>/config/clients/<client-id>/config/clients/<default>
(1)改造源码,实现单个broker流量上限限制,只要流量达到broker上限立即进行限流处理,所有往这个broker写的用户都可以被限制住;或者对用户进行优先级处理,放过高优先级的,限制低优先级的;
(2)改造源码,实现broker上单块磁盘流量上限限制(很多时候都是流量集中到某几块磁盘上,导致没有达到broker流量上限却超过了单磁盘读写能力上限),只要磁盘流量达到上限,立即进行限流处理,所有往这个磁盘写的用户都可以被限制住;或者对用户进行优先级处理,放过高优先级的,限制低优先级的;
(3)改造源码,实现topic维度限流以及对topic分区的禁写功能;
(4)改造源码,实现用户、broker、磁盘、topic等维度组合精准限流;
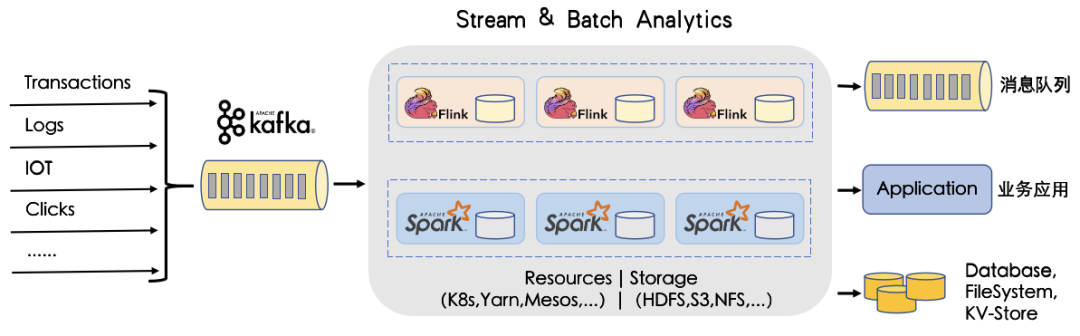
三、kafka发展趋势
3.8 Kafka所有KIP地址
四、如何贡献社区
2)https://issues.apache.org/jira/secure/BrowseProjects.jspa?selectedCategory=all
评论