
kafka新老集群平滑迁移实战
前言
公司一直使用云上的kafka服务,随着业务规模和体量的增大,使用云上的服务成本相对比较高,所以考虑本地自建kafka集群对外提供服务。
因此,需要把正在运行的还在使用云上kafka的业务服务迁移到本地自建集群上。
要求
代码改动小
升级过程中的稳定性
升级后消息发送与消费的正确性
迁移方案
1、双写/双读
顾名思义,生产端:消息同时发送新、老集群,消费端:同时消费两个集群的消息。
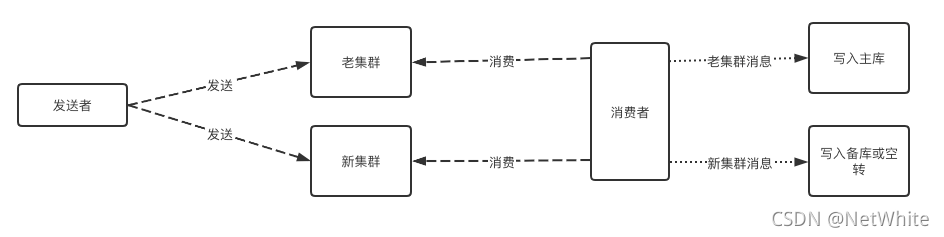
等到确认新集群的稳定和消息正确性后,逐渐下掉对老集群的依赖。
发送端双写还好做,难点在于消费端消费迁移实现上,主要可能有以下几种问题:
如果采用先消费到备库上,后续备库再切换为主库,很多业务在其目前场景下其实很难实现。
消费端对新集群消息的消费逻辑只是空转意义不大,如果期望检测消费的新、老集群的消息一致性,开发成本也是比较高。
消费端不采用双读方案,不消费新集群的消息。最后直接切换到新集群开始消费,这样需要保证消费的幂等性。但是很多场景下是无法保证的,比如使用了第三方大数据相关的组件。
采用双写/双读的方案,很多项目相关负责的同学,肯定也是无法接受的,毕竟代码改造太多了,开发成本太高。
所以,优先不考虑这种方案,采用了下面这种数据同步的方案。
2、数据同步
采用消息同步工具,将老集群的消息直接同步到新集群,客户端不再需要双读/双写,最后切换的时候直接修改为新集群的地址,重新发布即可。
整个过程如下:
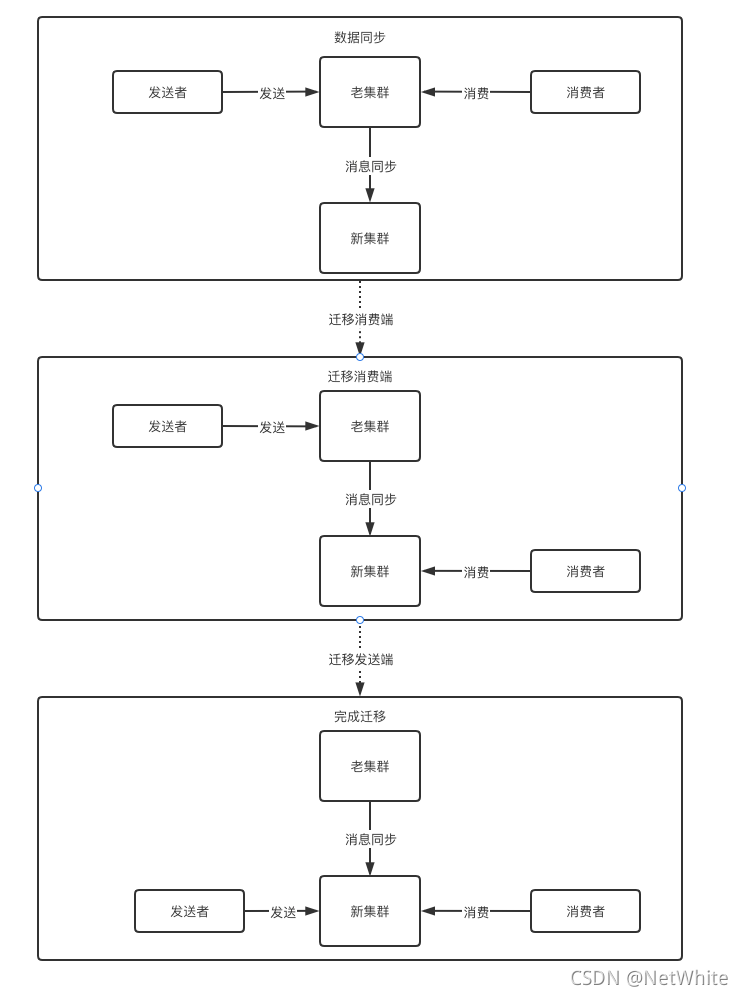
最后下掉老集群。
这样无论对发送端或消费端都是是极其友好,且“平滑”。
我最终考虑并采用的是这个方案,唯一的问题便是迁移过程中的所有问题和压力都从业务侧的同学转移到我们这边,比如:发送的消息如何同步,如何避免消费端切换后,重复消费或者漏掉消息未消费。
迁移过程
迁移基本流程正如前面流程图展示的:数据同步->迁移生产端/消费端。
生产端和消费端没有先后切换新集群上的顺序要求,但是如果先把生产端切换到新集群,消费端就无法从老集群继续消费消息了,需要在消息的过期时间内,赶紧也切换到新集群。
但是如果消费端先切,则发送端可以在之后的任何时间。
1、消息同步
消息同步是第一步,kafka的消息同步工具在业内有做的比较好的商业版提供,同时也有开源版本供使用。
我选取的是官方自带的kafka-mirror-maker工具。
但是不能直接拿来用,否则同步过来的消息无法继续我下面的方案。
kafka-mirror-maker的默认实现就是消费老集群指定topic的消息并重新发送到新集群,且发送的时候未指定分区。但是我需要保证新老集群上每条消息在每个分区上的顺序保持一致,不能出现消息在老集群的分区0上,同步后被发送到新集群的分区1上。
因此进行适当改造,如下,构造消息的时候指定发送的分区:
private[tools] object defaultMirrorMakerMessageHandler extends MirrorMakerMessageHandler {override def handle(record: BaseConsumerRecord): util.List[ProducerRecord[Array[Byte], Array[Byte]]] = {val timestamp: java.lang.Long = if (record.timestamp == RecordBatch.NO_TIMESTAMP) null else record.timestampCollections.singletonList(new ProducerRecord(record.topic, record.partition, timestamp, record.key, record.value, record.headers))}}
重新编译打包。
其实执行同步前,确保要同步的topic,已经在新集群创建并且新、老集群的分区数保持一致。
最后,同步的时候,我们并不需要一次性把所有的topic消息都向新集群同步。有针对性的处理,要迁移哪个服务,同步对应该topic的消息,迁移完成,停掉对应的同步进程,然后继续下个服务。
当然为了方便,我同时开发了对应的启停脚本,尽可能方便、规范的进行。
下面是我计划的协作流程:
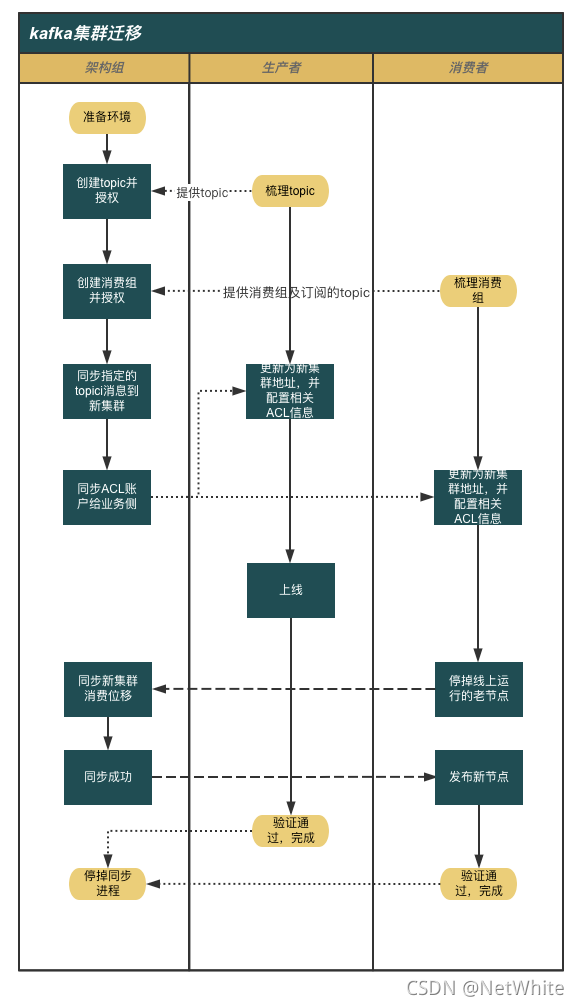
因为我们自建集群开启了ACL,老集群并没有,所以中间涉及到ACL相关的处理。
2、消费位点同步
消费端切换集群这一步问题也是最多最复杂的。
对于生产者来说,因为作了消息同步,新老集群消息及消息在分区的位置都是一致的,所以直接修改地址切换新集群继续发送即可。
对于消费端来说,如何在切换到新集群后,还能继续相对于老集群中原来的消费位点继续消费是一个问题,需要保证消息不会重复消费,也不会丢失消费。所以计算在新集群中的消费位点是很重要的。
正常情况下,kafka是没有创建消费组的功能,我们现在要做的就是,如果消费端切换新集群后,就已经知道现在要做的这个消费组要从这个位点继续消费了。
对于这个问题,我开发了一个功能,可以新增订阅:
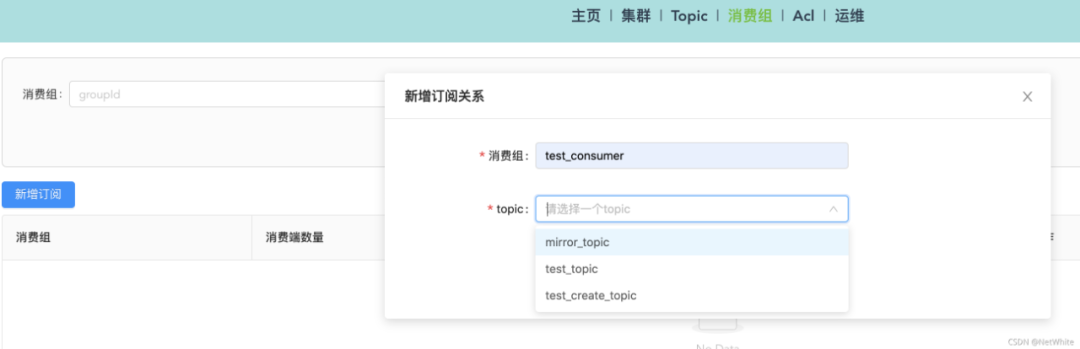
输入一个消费组,并选择集群已经存在topic,创建订阅关系,示例如下,我创建一个订阅test_topic的消费组:
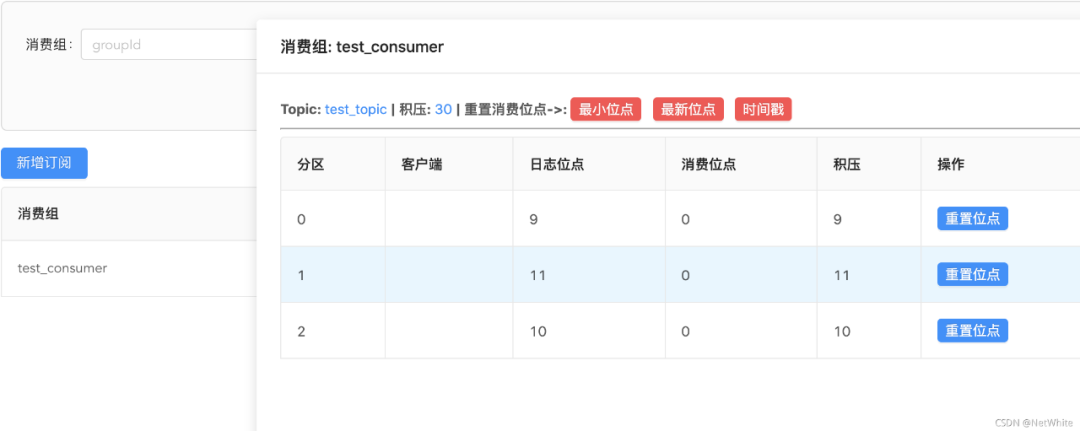
如果现在消费组为test_consumer的消费端,现在要从老集群切换到新集群继续消费,我们只要保证它不会出现重复消费,也不会漏掉消息即可。
所以这里解决方案的关键点就是需要将每个分区的消费位点,进行重置,重置的位置就是想当于在老集群中消费到的消息位点。
这个位点计算还是比较麻烦的,因为新老集群中各分区位点是一定不一致的。比如对于test_topic,可能此时的最小位点是1001(1001以前的消息过期删除了),日志最大位点是1300,所以现在实际某个分区有300条消息。但是同步到新集群,位点是从0开始,该分区在新集群最大位点就是300。
如果同步进程运行了好久,消费端才迁移新集群,新老集群的消息留存时间又不太一致,都删过几次过期消息,则老集群可能日志的最小位点是3001,最大位点是3300,新集群的最小位点是1000,最大位点是2300,两个集群现在留存的消息数都不一致了。
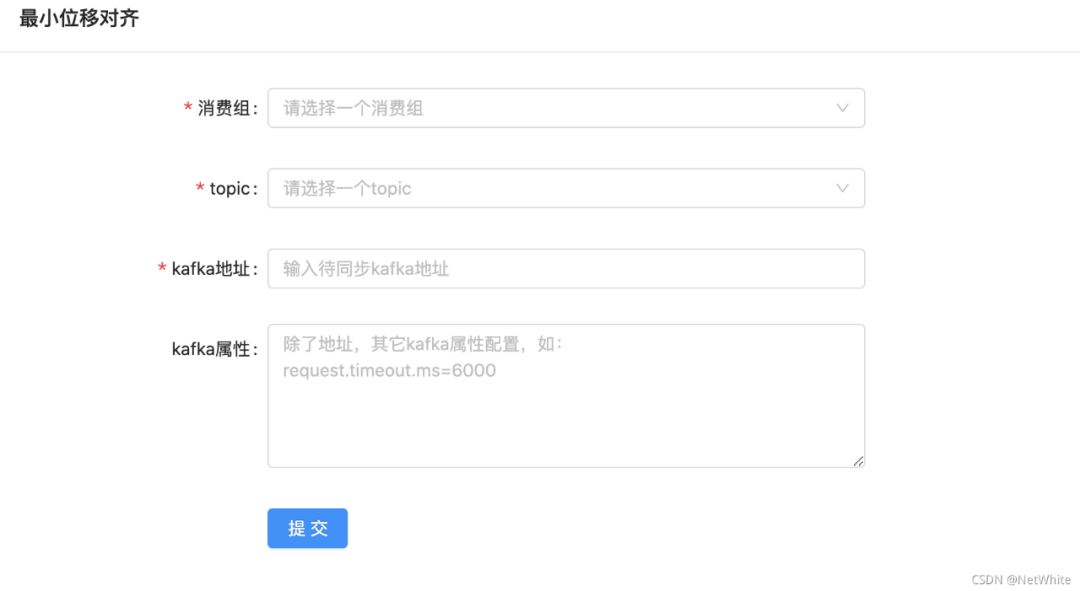
所以我这里采用了两阶段的同步方案:
准备同步消息的时候,进行位点标记
准备迁移消费端的时候,进行消费位点同步

大概就是上面说明的,通过相关的标记和计算确保新老集群消费的相对位点在各处场景下都是一致的,同步功能做了必要的效验,会保证同步的时候环境是预期的否则同步不了。如果最后同步阶段失败,则清除新集群中该topic相关数据,重新同步,重新执行这个流程即可(兜底解决方案)。
数据同步问题
数据同步过程中也是可能出现问题的,有些难以预料且致命的,如果消费端还没迁移,我们可以清除数据,重新同步,影响不大。
如果在同步过程中,同步进程挂掉,重启可能导致新老集群数据不一致。因为同步也是一边消费老集群一边发送到新集群,所以无法保证在挂掉重启的时候,是否会重复同步那一批次消息。
这个时候也是有解决方案的:
上面说过,在同步前进行了相关位移对齐,这时候可以查看相关对齐信息,人工重置用来同步的消费组的消费位点来保证消息一致。
最后,如何确认新老集群的消息是一致。这个时候假定同步过程,消息体没有出问题(这个出问题确实不好校验,认命了),只要查看对齐记录里的位移信息进行计算,确认从同步一来,新老集群每个分区的消息数都是一样,就可以确认消息一致的(不保证消息体的内容也没问题,比如丢包导致的)。
推荐阅读: