
NLP系列之句子向量、语义匹配(二):BERT_avg/BERT_Whitening/SBERT/SimCSE—方法解读
作者简介
作者:ZHOU-JC (广州云迪科技有限公司 NLP算法工程师)
原文:https://zhuanlan.zhihu.com/p/387271169
转载者:杨夕
面筋地址:https://github.com/km1994/NLP-Interview-Notes
个人笔记:https://github.com/km1994/nlp_paper_study
前言
上一篇博客,讨论了语义匹配的语义场景,这篇博文跟大家讨论相关的技术,主要包括BERT-avg、BERT-Whitening、SBERT、SimCES四个。
为了方便,还是从狭义的语义匹配的场景出发,场景目标是输入一对句子,输出这对句子相似性(回归,0~1)。

BERT-avg
BERT-avg做法很简单,直接拿预训练后的模型来做相似度匹配,因为默认经过预训练后的模型含有知识,能够编码句子的语义。
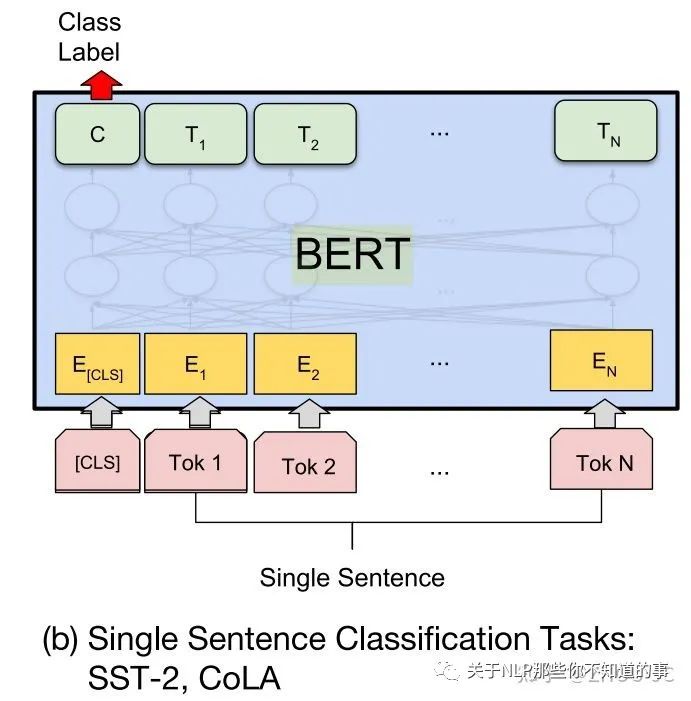
注意的是,不经过fine-tuning的模型,不能单纯把它们拼接起来作为输入,而是两个句子要分别输入BERT模型。具体的,选择句子的embedding有几种策略:
取CLS token的的最后一层输出作为embedding;
取序列最后一层的输出求平均(通常,做分类的时候求max效果会较好,做语义表征的时候求mean效果较好);
把第一层和最后一层的输出加起来后做平均(有研究表明头几层,主要蕴含词汇信息,靠任务的层主要蕴含语义信息,把它们拼接起来,让两种信息得到融合)。
得到两个句子的embedding后,再对embedding求余弦距离作为它们的相似度。
但实质上,这种效果并不好。原因在于各向异性。什么叫各向异性?这里引入知乎某答主的回答。

我理解的是输出的每个token是768维的(即向量空间的基向量由768个768维的向量组成),embedding的数值大小取决于当前选的坐标系,假如当前坐标系非标准正交基,则会出现空间上是正交的向量(空间正交不依赖于坐标系,无论你取哪个作为基底,在空间中它们就是正交),但在该坐标系下计算出的投影不为0。
BERT-Whitening
论文全称:《Whitening Sentence Representations for Better Semantics and Faster Retrieval》
项目代码:github.com/bojone/BERT-
解决各向异性有BERT-flow、BERT-Whitening等方法。其中BERT-Whitening尤为简单,目标就是对语料数据求特征值分解,然后把当前坐标系变换到标准正交基。
特征值分解还有个好处是能降维,大家想想PCA的原理,假如目前是768维的向量空间,经过正交标准变换后,有一些方向的特征值是很小的,可以把这些维度抛弃,达到节约存储空间,提高计算效率的目的。

上图为BERT-Whitening的实现步骤,首先把当前任务的语料,一句句地输入到预训练模型中得到各自的embedding,然后对embeddings做特征值分解,得到变换矩阵,存起来。应用时,把新的句子输入预训练模型,得到句子embedding,再用存起来的变换矩阵u和W做坐标变换,这时候变换后的embedding就是标准正交基表示的embedding。
SBERT
论文全称:《Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks》
项目代码:github.com/UKPLab/sente

SBERT是近年工业上应用很广泛的方法,思想很简单,就是如上图左边的双塔模型,有的地方称为Siamese network(孪生网络)和Bi-Encoder。
有的朋友会疑问,这几年句子相似度的算法竞赛,发现都没见到这种双塔模型的身影,常常是上图右边这种Cross-Encoder的结构。原因是,双塔模型相对Cross-Encoder结构效是稍差的,但落到工业应用上,它的优点就是快很多!
回想上一篇博客检索式机器人的场景,假设现在知识库中有500个候选问题,现在传来一个用户的问题,Cross-Encoder结构要把用户问题和500个候选问题,分别拼接后输入模型,相当于要做500次前向计算。而双塔模型则只需要把500个候选问题的embeddings提前算好存储起来,当有新问题时,只需要算这个问题的embedding,然后用新问题的embedding与500个embeddings做矩阵计算就OK了,相当于只进行了一次前向计算!所以检索的一种方法是,首先用SBERT做检索,然后用Cross-Encoder做精排。
论文中的一些一些细节:
预测时,SBERT是对BERT的输出做pooling来得到固定维度的句子embedding。作者实验了三种做法:包括使用CLS token的embedding、求句子序列的输出求mean、对句子序列的输出求max。实验发现,mean效果是最好的。
训练的损失函数
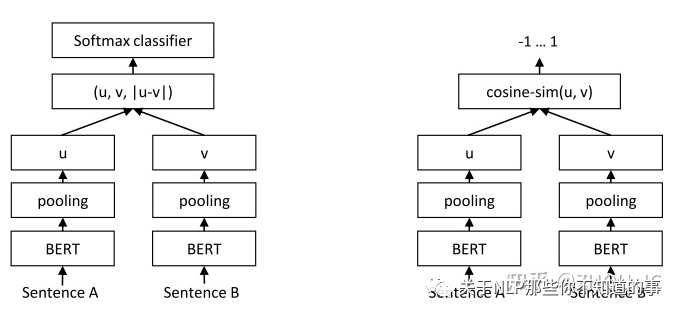
Classification Objective Function:如上图的左边,当训练集是分类数据集时,采用优化交叉熵损失。值得注意的是,这里的concatenation可以采用多种方式,如(u,v)、(|u-v|)及图中的(u, v, |u-v|)等等,论文实验证明,|u-v|是影响最大的因子。强调一下,concatenation只有在训练采用交叉熵损失才考虑,预测时,用的只有u和v。
Regression Objective Function:如上图右边,采用平方损失。
Triplet Objective Function:三元组损失,当训练的数据集是如NLI这种三元组数据集时(即包含原句、与原句语义相同的句子、与原句矛盾的句子组成一个三元组),就可以采用这种目标函数,损失计算如下
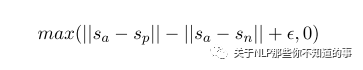
使用哪种损失函数依据手头数据集的形式,但无论采用哪种方式进行训练,预测时,用的都是两个句子分别输入encoder,得到输出后求pooling得到u和v,再求余弦相似度从而得到句子对的相似度。
SBERT-Semantic Textual Similarity库
库地址:sbert.net/examples/trai
该库发布了用不同数据训练的SBERT模型可供直接调用(不过没看到中文的,只看到个多语言的),也封装了用你自己数据训练SBERT模型、Cross-Encoder模型的代码,以及训练完后如何调用的API。
库里还列举了SBERT的使用场景,如下图,包括计算句子的embedding、计算语义相似度、语义搜索、检索重排、聚类等等应用,每个应用都有示例代码。

总而言之,这个库对工业应用十分友好,建议做工程的同学充分掌握,业务上就能快速实现闭环。
SimCSE
论文全称:《SimCSE: Simple Contrastive Learning of Sentence Embeddings》
项目代码:github.com/princeton-nl
上面提到的BERT-avg和BERT-whitening都是无监督的方法,SBERT是有监督的方法,这里提到的SimCSE有无监督和有监督两种模式,其中的无监督模式是当前无监督的SOTA方法。
SimCSE的核心思想是当前较火的对比学习,对比学习的目标是使语义相近的句子在向量空间中临近,语义不同的互相远离。
具体的过程如下图所示。


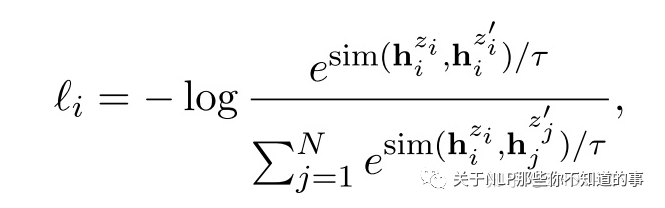
有监督学习:如上图右,不同于无监督学习通过dropout制作语义相同的句子对,论文中的有监督学习用的是NLI数据集,NLI数据集,针对推理前提(primise)与推理假设(hypothesis)之间是否存在逻辑关系,人工标注了三种标签entailment蕴含、contradiction矛盾、neutral中立,如下图为一些示例展示
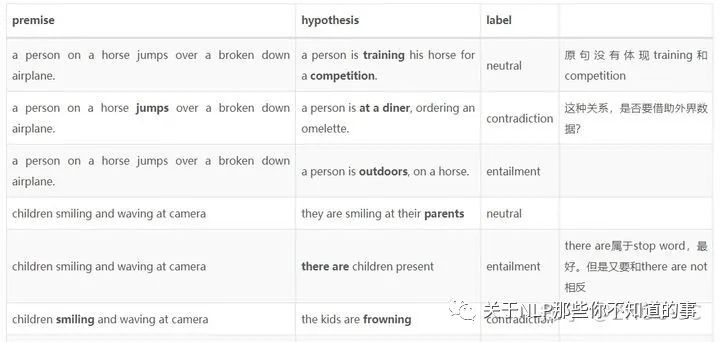
本来NLI的任务是输入一个句子对,输出它们的label是【entailment、contradiction、neutral】中的一个。SimCSE里作了点小改动,label为entailment的句子对作为语义相近的样本,目标拉近它们的余弦距离,而label为contradiction的句子对则作为语义不同的句子,要拉远它们的距离。损失函数如下
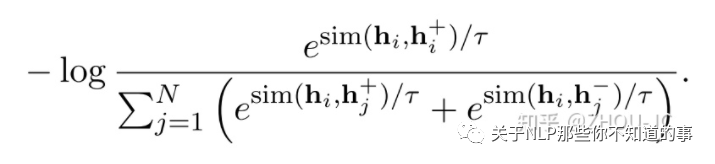
这里再介绍一下论文里重要的一些细节:
dropout效果是最好的:无监督训练时,除了用dropout生成语义相同的句子对,论文里还采用过如:
Crop:随机删掉一段span
Word deletion:随机删除词
MLM:用BERT预训练任务之一,用一些随机token或【MASK】token代替原序列的某些token
等等,最后发现dropout效果是最好的,而且最容易实现。
解决各向异性:论文里一章数据证明了对比学习的目标能有效平滑(论文里叫flatten)句子embedding矩阵的特征值分布。
从线性代数的角度讲,特征值分布不均匀,代表这个矩阵所表示的线性变换在某些方向上变化大,某些方向上变化小,导致各向异性,而平滑特征值可以使得这个线性变换在各个方向的变化均匀化,有效减缓各向异性。
Pooling策略:以往的经验,编码句子embedding时最好用最后一层的输出求平均,或第一层加最后一层的输出求平均,但论文里发现,用CLS token最后一层输出加全连接层后的输出作为embedding效果差不多,所以论文里采用这种CLS,毕竟较为简单;
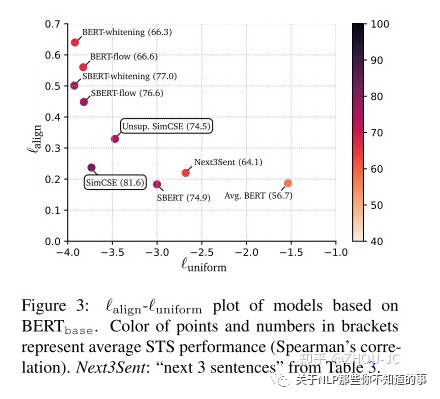
uniformity and alignment:
alignment表示对齐,则语义相同的句子在句子embedding的向量空间中方向相同
uniformity即均匀性,表示不同句子在句子embedding的向量空间中应该尽可能分布均匀。
从下图可以看出,训练完的SimCSE无论是uniformity和alignment都表现不俗,像BERT-flow、BERT-whitening能提高uniformity,但alignment的表现却很差。
总结
四种方法中,SBERT和SimCSE的效果应该是最好的,而且实现都十分简单,能快速应用到业务中,下一篇博文会用实验更加严谨对比不同方法的效果。
参考资料
Whitening Sentence Representations for Better Semantics and Faster Retrieval
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
SimCSE: Simple Contrastive Learning of Sentence Embeddings
张俊林:对比学习(Contrastive Learning):研究进展精要