
【NLP】ACL2020 | 词向量性别偏见
作者 | Salesforce Research 编译 | NewBeeNLP
ACL2020关于词嵌入性别偏见的蛮有意思的一项工作:
论文地址:https://arxiv.org/abs/2005.00965
代码地址:https://github.com/uvavision/Double-Hard-Debias
TL; DR
从人类生成的语料库中学习到的单词嵌入继承了强烈的「性别偏见(gender bias)」,并且会通过下游模型进一步放大。我们发现诸如单词频率之类的语料库规则会对现有的post-hoc debiasing算法产生负面影响,并建议在推断和删除性别子空间之前针对此类语料库规则来净化词向量。
词嵌入中的性别偏见
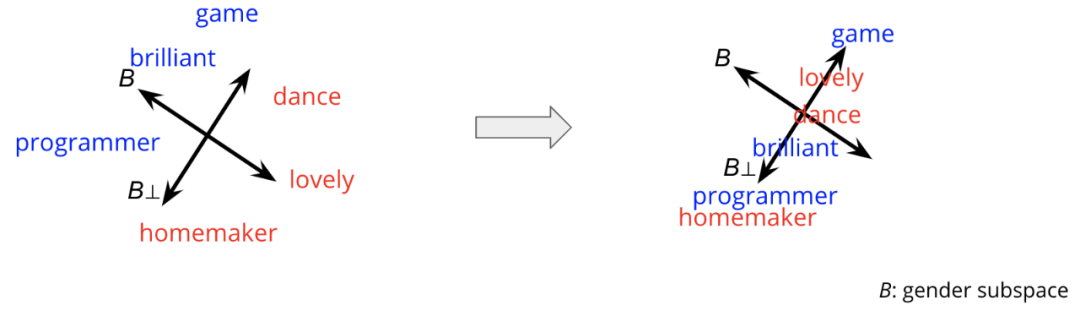
词嵌入是词汇表中单词的向量表示,它们能够捕获单词的语义和句法含义以及与其他单词的关系。尽管在自然语言处理(NLP)任务中广泛使用了词嵌入,但由于其从训练语料库中继承了意想不到的性别偏见,因此饱受批评。如论文中所讨论的(Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings[1]),我们认为一个单词在定义上与性别无关但其学习的嵌入更接近于某个性别时,这就产生了性别偏见。例如,在下图中, 轴是对「他(he)」 和 「她(she)」 两个词的嵌入之间差异的投影,而 轴是在嵌入过程中捕获性别中立性的方向,与性别无关的位于上半部分,而与性别有关的词位于下半部分。尽管从定义上说,brilliant和genius不分性别,但它们的embedding更加接近男性(he)。同样,homemaker和sewing与女性(her)联系更紧密。

为什么性别偏见如此重要?
词嵌入中的性别偏见是一个严重的问题。想象一下,人们基于有偏词嵌入开发了一个简历过滤模型。该模型可以潜在地过滤掉像程序员这样的职位的女性候选人,也可以排除像理发店这样的职位的男性候选人。同样,当QA模型被用于解析医学报告时,如果将医生全部默认为男性而护士全部默认为女性的则很大可能会提供错误的答案。
早期的硬Debias方法
先前的工作[1]通过后处理(post-processing)从词嵌入中减去与性别相关的成分,从而减少了性别偏见。具体而言,它需要一组特定于性别的单词对,并计算这些单词对的差异向量的第一个主成分作为嵌入空间中的性别方向。其次,它将有偏见的词嵌入投射到与推断的性别方向正交的子空间中,以消除性别偏见。虽然证明了这种方法可以缓解单词类比任务中的性别偏见,但这篇论文(Lipstick on a Pig: Debiasing Methods Cover up Systematic Gender Biases in Word Embeddings But do not Remove Them[2])认为这些努力的效果是有限的,因为性别偏见仍然可以从去偏后的嵌入几何图中恢复。
词频会扭曲性别倾向
在某种情况下,我们假设很难以现有的「Hard Debias」方法所采用的方式来识别单词嵌入的真实性别方向。参考资料[3]和[4]表明词频显著影响词嵌入的几何形状。例如,流行词和稀有词聚集在嵌入空间的不同子区域中,尽管事实上这些词在语义上并不相似。这可能会对识别性别方向的过程产生负面影响,并因此降低“硬性偏见”消除性别偏见的能力。我们通过经验证明,某些单词的频率变化会导致相应差异向量与其他差异向量之间的相似性发生重大变化,如下图所示。

双重硬性偏差:通过消除频率影响来改善硬性偏差
由于单词频率会扭曲性别方向,因此我们建议使用「Double-Hard Debias」消除单词频率的负面影响。关键思想是在应用Hard Debias之前将单词嵌入投影到intermediate subspace。回想一下,Hard Debias通过将嵌入空间转换为无性别的空间来减少性别偏见。同样,在Double-Hard Debias中,我们首先将所有单词嵌入转换为「无频率子空间」,在该子空间中,我们能够计算出更准确的性别方向。更具体地说,我们尝试找到对频率信息进行编码的维度,该频率信息分散了性别方向的计算。然后,我们沿着字词嵌入的这个特定维度投影组件,以获得修正的嵌入,并对修正的嵌入应用Hard Debias。
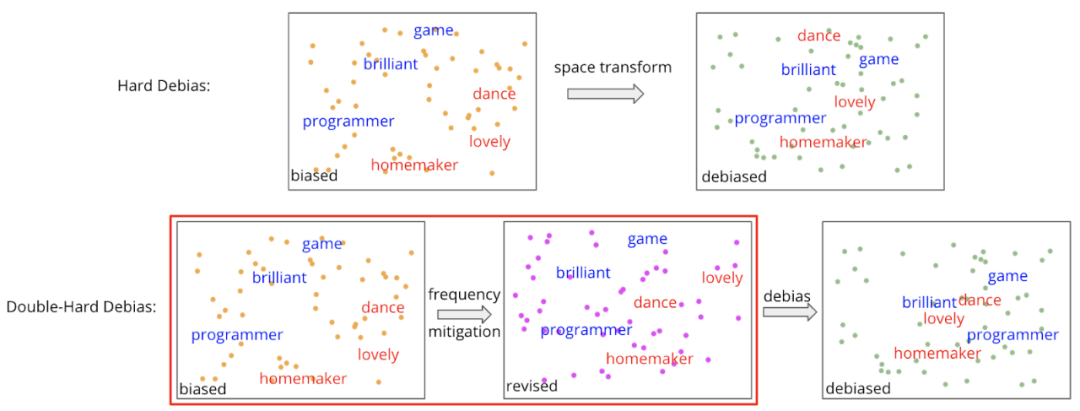
为了识别此维度,我们采用top biased words的聚类作为代理,并反复测试词嵌入的主成分。详细步骤如下:
计算所有单词嵌入的主成分作为频率维度候选; 选择一组最偏(top-biased)的男性和女性词汇(例如,程序员,家庭主妇,游戏,舞蹈等); 对没有候选维度 分别重读步骤4-6; 投影嵌入(embedding)到与 正交的中间空间中,从而获得经过修正的嵌入; 对修正的嵌入应用 Hard Debias; 对选定的top biased词的debiased embedding进行聚类,并计算聚类精度。
如果步骤6中的聚类算法仍将有偏见的词聚类为与性别对齐的两组,则意味着删除 不能改善去偏性。因此,我们选择导致有偏词聚类准确性下降幅度最大的 并将其删除。
Double-Hard Debias的表现如何?
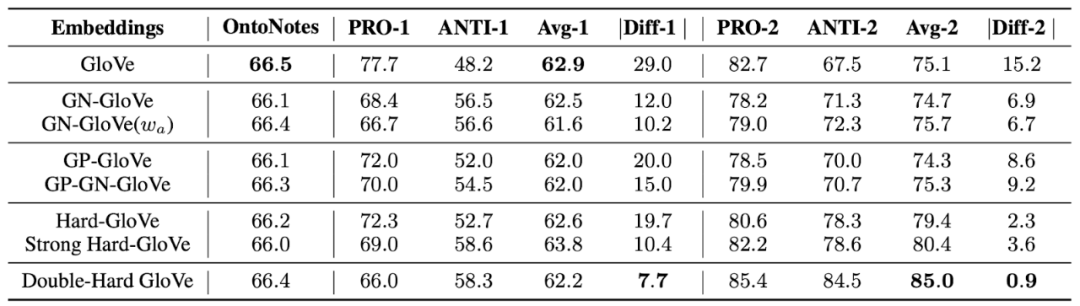
我们在几个bias mitigation基准上评估Double-Hard Debias,包括重要的下游任务--conference resolution。我们使用 WinoBias数据集来量化性别偏见。WinoBias由两种类型的句子组成。每种类型的句子可以分为pro-stereotype子集和anti stereotype子集,性别是这两个子集之间的唯一区别。类型1句子中的一个示例包含一个定型观念句子:「The physician hired the secretary because he was overwhelmed with clients」。还有一个反刻板印象的句子:「The physician hired the secretary because she was overwhelmed with clients」。前定型和反定型之间的性能差异反映了共指系统在男性和女性群体中的表现差异。因此,我们将此差距视为性别偏见得分。最初的GloVe嵌入带有明显的性别偏见,因为我们可以看到两种类型的句子的性能差距分别达到29点和15点。与Hard Debias和其他最新的debiasing方法相比,我们的方法在两种共指句子中都实现了最小的差异。同时,Double-Hard Debias还保留了词嵌入中有用的语义信息。在原始测试集上,我们仅观察到F1分数下降了0.1%。
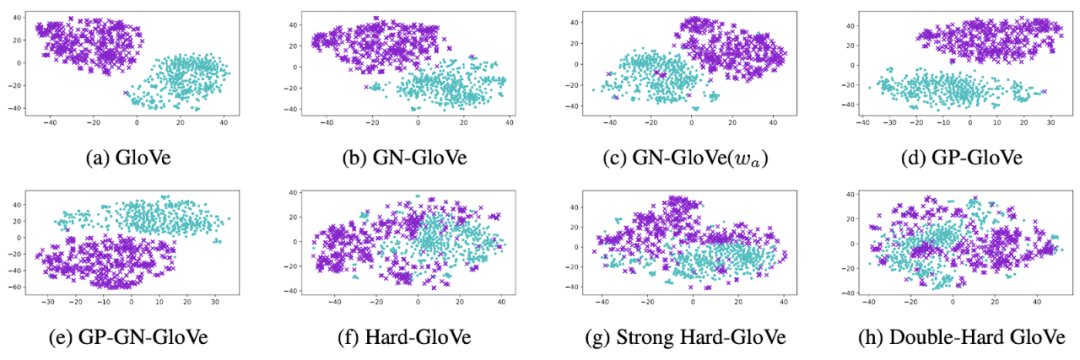
我们还对所有前500个有偏见的女性和男性嵌入进行tSNE预测。如下图所示,原始的GloVe嵌入明显投影到了不同的区域,表明强烈的性别偏见。与其他方法相比,Double-Hard GloVe最大程度地混合了男性和女性的嵌入,显示出在消除偏见后可以捕获到较少的性别信息。
结论
我们发现单词频率统计信息的简单变化可能会对用于消除单词嵌入中性别偏见的去偏方法产生不良影响。尽管迄今为止在以前的性别偏见减少工作中都忽略了词频统计,但是我们提出了Double-Hard Debias,它减轻了词频特征对去偏算法的负面影响。我们认为,提供公平实用的单词嵌入很重要,希望这项工作能够激发沿这个方向的进一步研究。
本文参考资料
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings: https://arxiv.org/abs/1607.06520
[2][Lipstick on a Pig: Debiasing Methods Cover up Systematic Gender Biases in Word Embeddings But do not Remove Them: https://arxiv.org/abs/1903.03862
- END -
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群请扫码进群: