
你所需要知道的关于AutoML和NAS的知识点
【GiantPandaCV导读】本文是笔者第一次进行翻译国外博客,第一次尝试,由于水平的限制,可能有的地方翻译表达的不够准确,在翻译过程中尽量还原作者的意思,如果需要解释的部分会在括号中添加,如有问题欢迎指正。本文翻译的是《Everything you need to know about AutoML and Neural Architecture Search》获得了4.8k的高赞。
作者:George Seif
翻译:pprp
日期:2018/8/21
AutoML和NAS是深度学习领域的新秀。不需要过多的工作量,他们可以使用最暴力的方式让你的机器学习任务达到非常高的准确率。既简单又有效率。
那么AutoML和NAS是如何起作用的呢?如何使用这种工具?
Neural Architecture Search
神经网络架构搜索,简称NAS。开发一个神经网络模型往往需要大量的工程架构方面的设计。有时候可以通过迁移学习完成一个任务,但是如果想要有更好的性能,最好设计自己的网络。
为自己的任务设计网络架构需要非常专业的技能,并且非常有挑战性。我们很可能不知道当前最新技术的局限在哪里(SOTA技术的瓶颈我们并不清楚),所以会进行很多试错,这样的话非常浪费时间和金钱。
为了解决这个问题,NAS被提出来了,这是一种可以搜索最好的神经网络结构的算法。大多数算法都是按照以下方式进行的:
首先定义一个Building Blocks的集合,集合中元素代表的是可能用于神经网络搜索的基本单元。比如说NASNet中提出了以下Building Block。

在NAS算法中,控制器RNN会从这些Building Blocks中采样,将他们拼接起来构建一个端到端的网络架构。这种结构通常与SOTA网络的架构相同,如ResNet、DenseNet,但是使用的模块组合和配置有较大的区别。
对新产生的网络架构进行训练,使其收敛,并在验证集上进行测试得到准确率。产生的准确率可以用于更新控制器,以便于控制器能够生成更好的网络结构。控制器的权重使用的是策略梯度进行更新的。整个端到端的设置如下图所示:
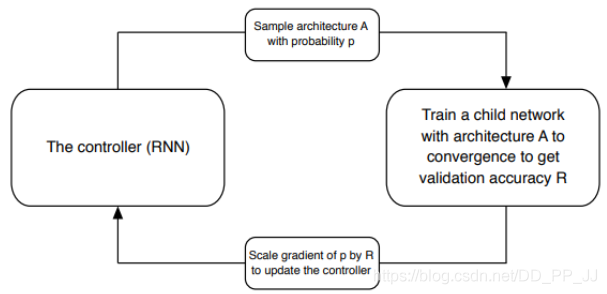
整个过程非常符合直觉。简单来说,让算法从不同的block之中采样,然后将这些模块组合起来构建新的网络。然后训练并测试该网络,根据获得的结果,调整使用的block模块以及各个block之间的连接方式。
这篇文章(Learning Transferable Architectures for Scalable Image Recognition)展示了这种方法获得的出色的结果是因为他受到了限制和假设。NAS设计的网络一般都是在远远比真实世界数据集上训练和测试的。这是因为在类似ImageNet这样比较大型的数据集上训练花费时间代价过大。但是在深度学习时代中,在比较小,但是结构相似的数据集上表现较好的网络,在更大更复杂的数据集上也应该表现更好。
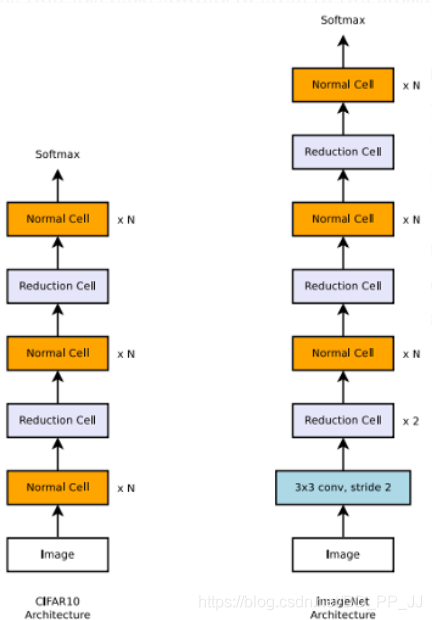
第二点就是搜索空间非常局限。NAS被设计用来构建与SOTA相似的网络架构。对于图像分类任务来说,网络构建需要重复的模块,然后逐步进行下采样,如左图所示。NAS设计的网络的主要新颖部分是这些块的连接方式。
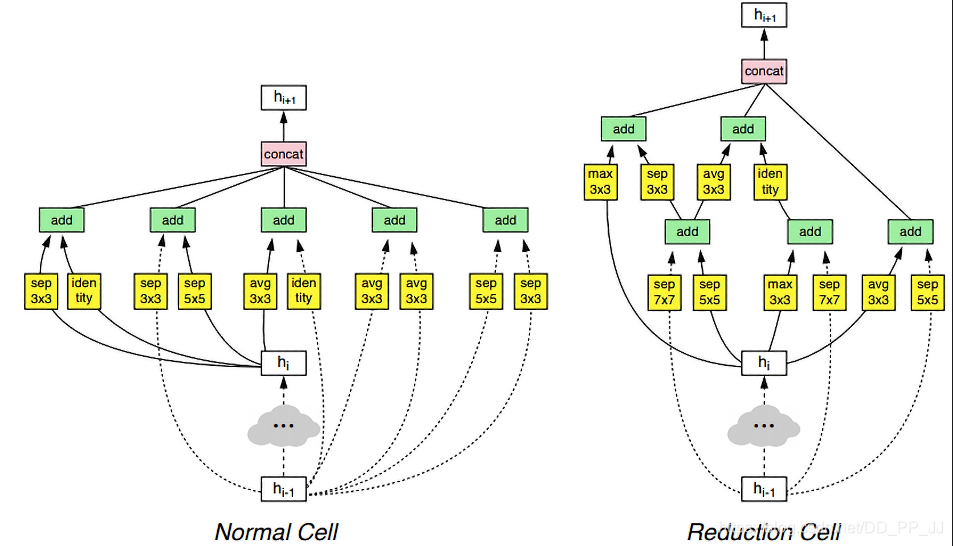
下图是在ImageNet中搜索得到的最好的block结构。可以发现这几个都包含了相当随机的混合操作,包括许多可分离卷积。
架构搜索方面的进步
NASNet论文取得了惊人的进步,因为其提供了深度学习研究的新方向。不幸的是,他对于除Google以外的普通人来说效率很低,很难实现。使用了450个GPU,并花费了3-4天时间的训练才找到一个出色的网络架构。因此,NAS方面很多的研究都集中于如何提高搜索过程的效率上。
Progressive Neural Architecture Search(PNAS)渐进式神经架构搜索提出使用一种叫做基于顺序模型的优化策略(SMBO: Sequiential Model-Based Optimisation)。与NASNet使用的强化学习方法不同,SMBO不是随机的从Block集合中抓取和尝试,而是对block进行测试,并按照复杂性增加的顺序搜索网络架构。这种方法虽然不会缩小搜索空间,但是能让搜索以更智能的方式完成。
SMBO的基本意思是:从简单开始,而不是立即尝试所有可能。PNAS这种方法的效率是NAS的8倍。
Efficient Nerual Architecture Search(ENAS)是另外一种试图提高通用网络架构搜索效率的方式。ENAS的提出能让更多没有充足GPU资源的人也能使用神经网络搜索。作者的假设是NAS的计算瓶颈在于对每个模型进行收敛的训练,然后测试其准确率,然后就丢弃训练过的权重。
在研究和实践中已经反复证明,由于接受过类似训练任务的网络具有相似的权重,迁移学习有助于在短时间内实现更高的精度。ENAS算法强制让所有模型共享权重,而不是去从头训练从头收敛。 因此,每次训练新的模型的时候,实际上都进行了迁移学习,这样收敛速度会非常快。
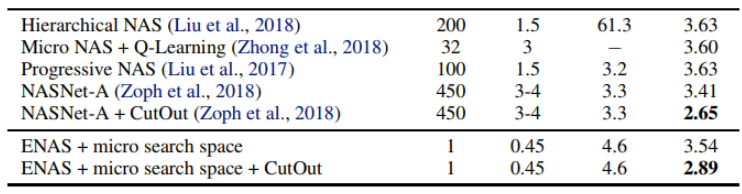
下表显示了使用单个1080Ti GPU进行半天的训练后ENAS的效率要高得多。
深度学习新范式:AutoML
许多人将AutoML称为深度学习的新方法,无需设计复杂的深度网络,只需运行预设的NAS算法。Google通过提供Gloud AutoML将这一点发挥到了极致。只需上传数据,Google的NAS算法即可为你提供快速简便的网络架构。
AutoML的想法是简单地抽象出深度学习的所有复杂部分。需要提供的只有数据。剩下的让AutoML设计最困难的部分。这样一来,深度学习就会像其他工具一样,成为插件工具。
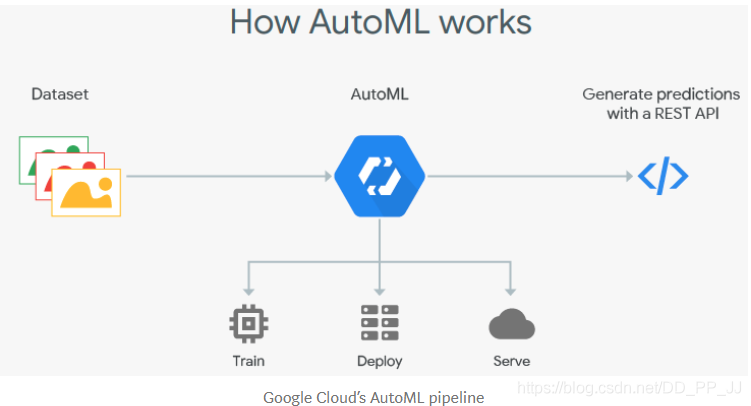
Cloud AutoML的价格确实高达2000美元,很遗憾,训练好以后也无法导出模型;将不得不使用他们的API在云上运行你的网络。还有其他一些完全免费的替代方法,但确实需要更多工作。
AutoKeras是一个使用ENAS算法的GitHub项目。可以使用pip进行安装。由于它是用Keras编写的,因此非常易于控制和使用,因此可以深入研究ENAS算法并尝试进行一些修改。如果你更喜欢TensorFlow或Pytorch,可以参考以下项目:
https://github.com/melodyguan/enas
https://github.com/carpedm20/ENAS-pytorch
对NAS和AutoML未来的预测
很高兴看到过去几年在自动化深度学习方面取得了长足的进步。它使用户和企业更易于获取;总体来看,深度学习的力量将变得更加易于公众使用。但是,依然有一些改进的空间。
网络架构搜索变得更加高效;使用ENAS找到一个网络在一个GPU上,经过一天的训练就可以得到相当不错的结果。然而,我们的搜索空间仍然非常有限。目前的NAS算法仍然使用手工设计的结构和构建块,只是将它们以不同的方式组合在一起而已。
一个强大的和潜在的突破性的未来方向将是更广泛的搜索,真正寻找新的架构。这种算法可能会揭示出在这些庞大而复杂的网络中隐藏的更深层次的学习秘密。当然,这样的搜索空间需要高效的算法设计。
NAS和AutoML的这个新方向为人工智能社区提供了令人兴奋的挑战,并为科学上的另一个突破提供了真正的机会。
英文原文
链接:https://towardsdatascience.com/everything-you-need-to-know-about-automl-and-neural-architecture-search-8db1863682bf
后记
英文翻译过来有点拗口,感谢阅读。笔近期将研究这个方向,欢迎相似方向的同学添加我的微信,多多沟通。