
时隔一年,盘点CVPR 2019影响力最大的20篇论文
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~


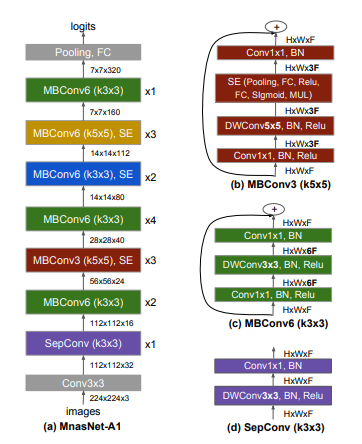

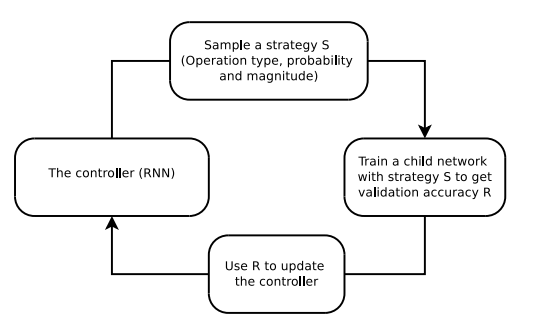
No.5 AutoAugment 数据增广


Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation

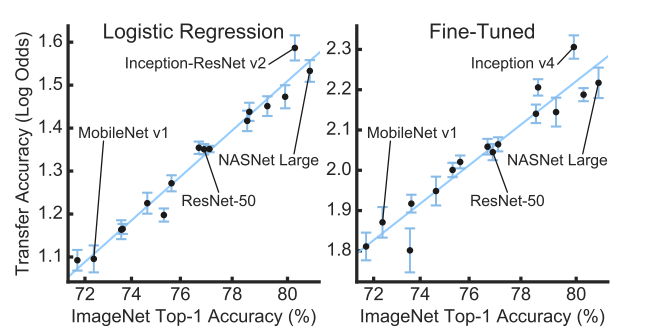
Do better imagenet models transfer better?
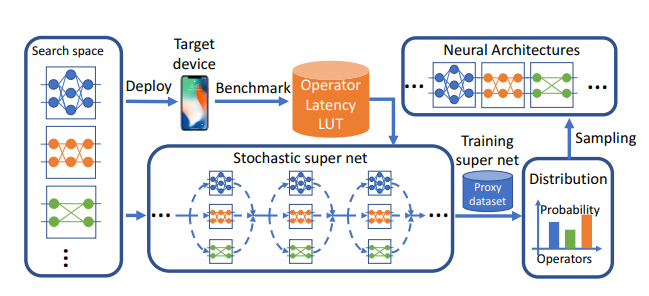
FBnet: Hardware-aware efficient convnet design via differentiable neural architecture search
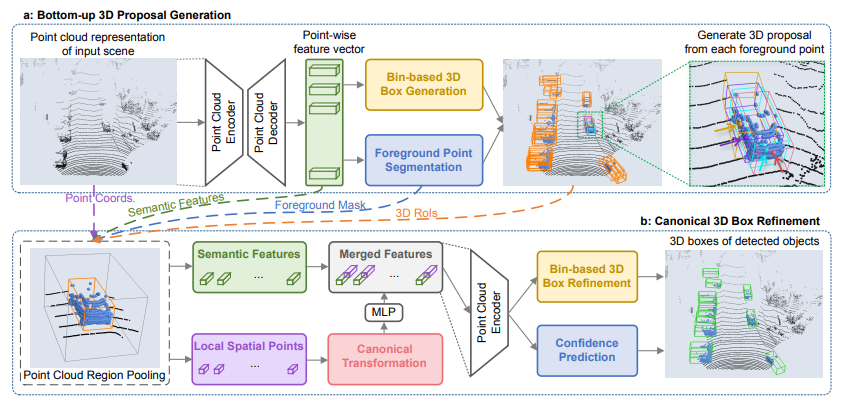
Pointrcnn: 3d object proposal generation and detection from point cloud
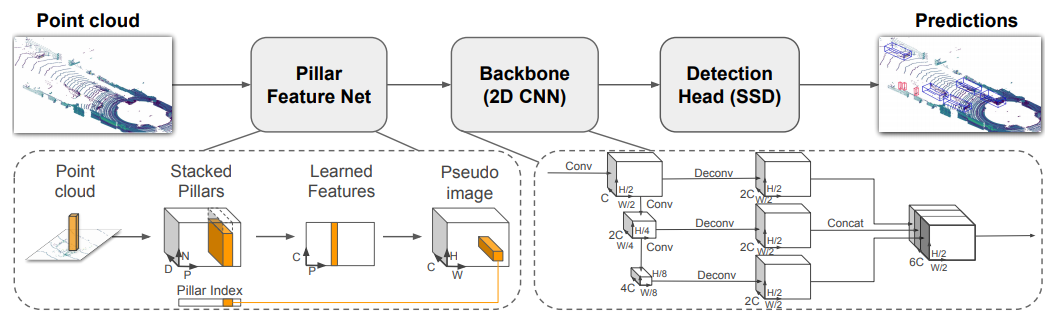
Pointpillars: Fast encoders for object detection from point clouds

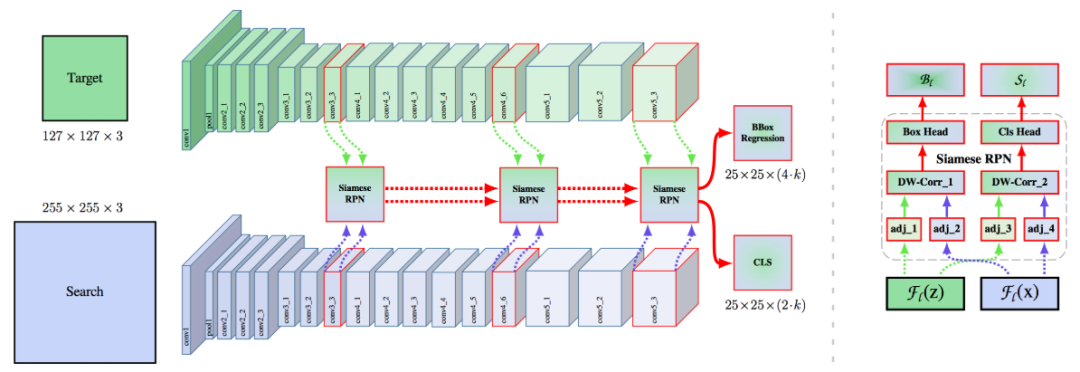
No.14 Siamrpn++ 目标跟踪

No.15 SiamMask 目标跟踪

Bag of tricks for image classification with convolutional neural networks

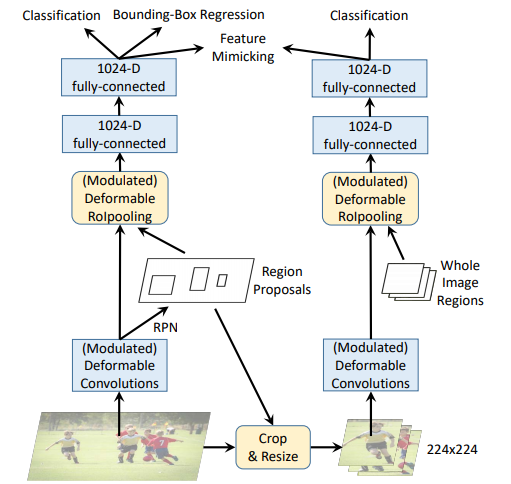
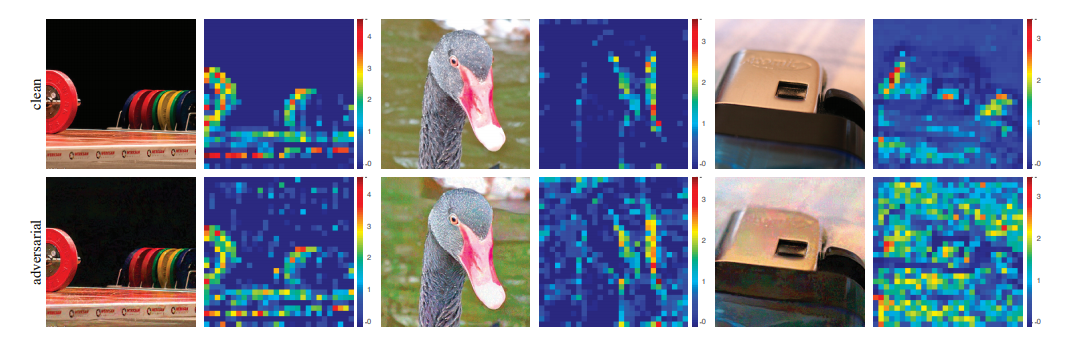
No.18 对抗学习
Feature denoising for improving adversarial robustness
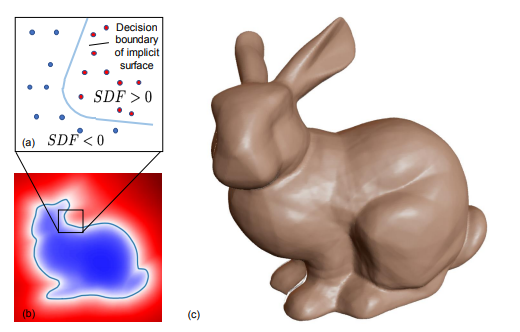
No. 19 DeepSDF 三维模型表示(三维重建)
Deepsdf: Learning continuous signed distance functions for shape representation
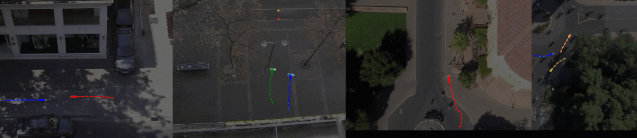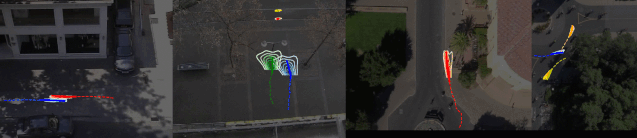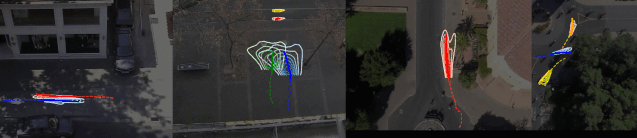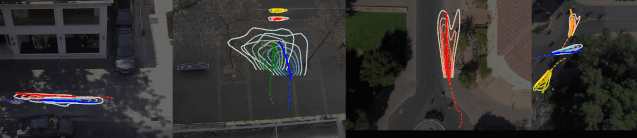
No. 20 Sophie 行人路径预测(自动驾驶领域)
推荐阅读
54篇最新CV领域综述论文速递!涵盖14个方向:目标检测/图像分割/医学影像/人脸识别等方向
25篇最新CV领域综述性论文速递!涵盖15个方向:目标检测/图像处理/姿态估计/医学影像/人脸识别等方向
全面综述:图像特征提取与匹配技术

评论