
SparkSQL用UDAF实现Bitmap函数
创建测试表
使用phoenix在HBase中创建测试表,字段使用VARBINARY类型
CREATE TABLE IF NOT EXISTS test_binary (date VARCHAR NOT NULL,dist_mem VARBINARYCONSTRAINT test_binary_pk PRIMARY KEY (date)) SALT_BUCKETS=6;
创建完成后使用RoaringBitmap序列化数据存入数据库:
实现自定义聚合函数bitmap
import org.apache.spark.sql.Row;import org.apache.spark.sql.expressions.MutableAggregationBuffer;import org.apache.spark.sql.expressions.UserDefinedAggregateFunction;import org.apache.spark.sql.types.DataType;import org.apache.spark.sql.types.DataTypes;import org.apache.spark.sql.types.StructField;import org.apache.spark.sql.types.StructType;import org.roaringbitmap.RoaringBitmap;import java.io.*;import java.util.ArrayList;import java.util.List;/*** 实现自定义聚合函数Bitmap*/public class UdafBitMap extends UserDefinedAggregateFunction {public StructType inputSchema() {List<StructField> structFields = new ArrayList<>();structFields.add(DataTypes.createStructField("field", DataTypes.BinaryType, true));return DataTypes.createStructType(structFields);}public StructType bufferSchema() {List<StructField> structFields = new ArrayList<>();structFields.add(DataTypes.createStructField("field", DataTypes.BinaryType, true));return DataTypes.createStructType(structFields);}public DataType dataType() {return DataTypes.LongType;}public boolean deterministic() {//是否强制每次执行的结果相同return false;}public void initialize(MutableAggregationBuffer buffer) {//初始化buffer.update(0, null);}public void update(MutableAggregationBuffer buffer, Row input) {// 相同的executor间的数据合并// 1. 输入为空直接返回不更新Object in = input.get(0);if(in == null){return ;}// 2. 源为空则直接更新值为输入byte[] inBytes = (byte[]) in;Object out = buffer.get(0);if(out == null){buffer.update(0, inBytes);return ;}// 3. 源和输入都不为空使用bitmap去重合并byte[] outBytes = (byte[]) out;byte[] result = outBytes;RoaringBitmap outRR = new RoaringBitmap();RoaringBitmap inRR = new RoaringBitmap();try {outRR.deserialize(new DataInputStream(new ByteArrayInputStream(outBytes)));inRR.deserialize(new DataInputStream(new ByteArrayInputStream(inBytes)));outRR.or(inRR);ByteArrayOutputStream bos = new ByteArrayOutputStream();outRR.serialize(new DataOutputStream(bos));result = bos.toByteArray();} catch (IOException e) {e.printStackTrace();}buffer.update(0, result);}public void merge(MutableAggregationBuffer buffer1, Row buffer2) {//不同excutor间的数据合并update(buffer1, buffer2);}public Object evaluate(Row buffer) {//根据Buffer计算结果long r = 0l;Object val = buffer.get(0);if (val != null) {RoaringBitmap rr = new RoaringBitmap();try {rr.deserialize(new DataInputStream(new ByteArrayInputStream((byte[]) val)));r = rr.getLongCardinality();} catch (IOException e) {e.printStackTrace();}}return r;}}
调用示例
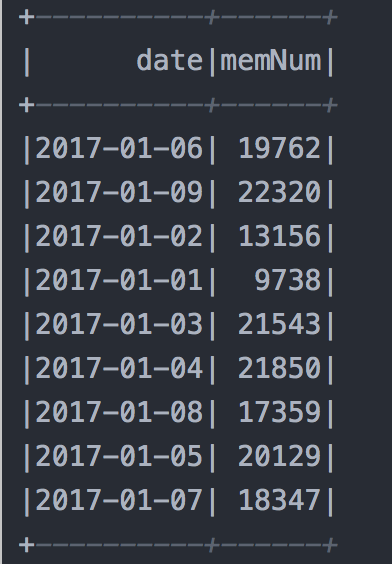
/*** 使用自定义函数解析bitmap** @param sparkSession* @return*/private static void udafBitmap(SparkSession sparkSession) {try {Properties prop = PropUtil.loadProp(DB_PHOENIX_CONF_FILE);// JDBC连接属性Properties connProp = new Properties();connProp.put("driver", prop.getProperty(DB_PHOENIX_DRIVER));connProp.put("user", prop.getProperty(DB_PHOENIX_USER));connProp.put("password", prop.getProperty(DB_PHOENIX_PASS));connProp.put("fetchsize", prop.getProperty(DB_PHOENIX_FETCHSIZE));// 注册自定义聚合函数sparkSession.udf().register("bitmap",new UdafBitMap());sparkSession.read().jdbc(prop.getProperty(DB_PHOENIX_URL), "test_binary", connProp)// sql中必须使用global_temp.表名,否则找不到.createOrReplaceGlobalTempView("test_binary");//sparkSession.sql("select YEAR(TO_DATE(date)) year,bitmap(dist_mem) memNum from global_temp.test_binary group by YEAR(TO_DATE(date))").show();sparkSession.sql("select date,bitmap(dist_mem) memNum from global_temp.test_binary group by date").show();} catch (Exception e) {e.printStackTrace();}}
结果:
评论