
超越AlphaZero!DeepMind让AI制霸「元宇宙」,玩转70万个独立游戏

新智元报道
新智元报道
来源:deepmind
编辑:yaxin
【新智元导读】五年前,AlphaGo打败李世石那一刻,全世界为之惊呼!直到AlphaZero面世,象棋、将棋一战而胜。现在,DeepMind 为AI打造了一个「元宇宙」,宣称能玩全宇宙的游戏。
AlphaGo打败李世石那一刻,全世界惊呼!
50天不到,进化版的最强围棋 AI AlphaGo Zero 面世,却成为了 AlphaZero 的手下败将。
从一开始只知道下围棋的基本规则,到后来「跨界」击败国际象棋、日本将棋、和围棋世界冠军。
AlphaZero 再次打破了人们的对AI玩游戏的认知。

AlphaZero登上Science封面
别急,还有更重磅的!
刚刚,DeepMind 说自家通过强化学习训练的AI能够玩儿遍「全宇宙的游戏」!

还有多人3D游戏也不在话下。
在最新发布的预印本 「Open-Ended Learning Leads to General Capable Agents」中,详细介绍了,在不需要人类交互数据的情况下,训练能够玩不同游戏的智能体。

别看是AI,「打怪」也需成长时间
通过强化学习,AlphaZero在不断重复试错的过程中学会了一个又一个游戏。
问题在于,AlphaZero若想能够在不同游戏中「单打独斗」,还得在每个游戏「从头训练」后才能够实现。

包括 Atari,Capture The Flag,StarCraft II,Dota 2,和 Hide-and-Seek在内的游戏也是如此。
由于「苦于」泛化能力差,强化学习只能针对单个任务来从头开始学习。

要知道,泛化能力并不是一蹴而就。
我们玩游戏的时候,也是先从简单任务起步,逐渐变为复杂。
为此,DeepMind 研究人员创建了一个巨大的游戏环境,称之为 XLand。
让AI玩转「元宇宙」
XLand这样的环境,更形象地来说,便是最近我们常谈的「元宇宙」。

这个「元宇宙」的创建是为了让智能体在不断扩展、升级的开放世界中学习,AI的新任务(训练数据)是基于旧任务不断生成的。
XLand 包含数十亿个任务,跨越不同的游戏、世界和玩家。
从简单到复杂的游戏,AI智能体在学习过程中不断完善训练任务。
简单的比如「靠近紫色立方体」,复杂一点的比如「靠近紫色立方体或将黄色球体放在红色地板上」。
这些智能体甚至还可以和其他智能体玩耍,比如捉迷藏和夺取旗帜。

每个小游戏正如宇宙中颗颗繁星,拼成了一个庞大的物理模拟世界。
这个世界的任务由3个要素构成:任务=游戏+世界+玩家。
根据3个要素的不同关系,来决定任务的复杂度。那么,如何判断任务的复杂度?

有以下4个纬度:竞争性,平衡性,可选项,探索难度。
基于这4个维度,一个任务空间的、超大规模的「元宇宙」XLand 就诞生了,而几何地球也只是这个元宇宙的一个小角落,只是这4纬空间的一个点。
终身学习
「元宇宙」XLand 解决了AI训练的数据问题,那么,接下来,用什么样的算法是合适的呢?
研究人员发现,目标注意网络 (GOAT) 可以学习更通用的策略。
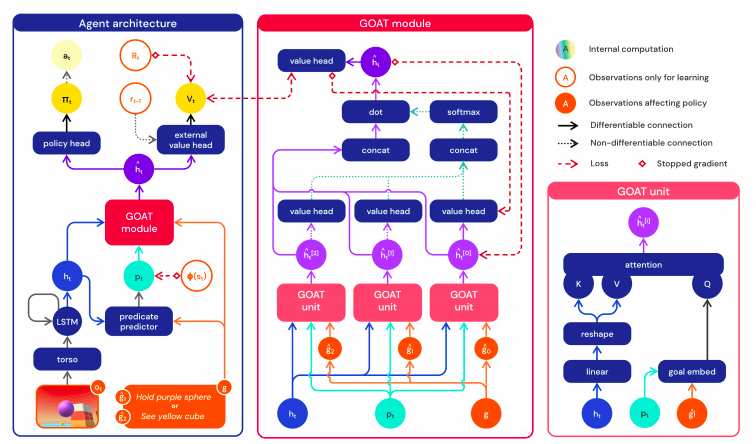
还有,在如此广阔的环境下,什么样的训练任务分配能够产生最好的AI「特工」?
动态任务生成允许智能体的训练任务的分布不断变化:
生成的每个任务既不太难也不太容易,但正好适合训练。
然后利用基于PBT来调整基于动态任务生成参数,以提高智能体的综合能力。
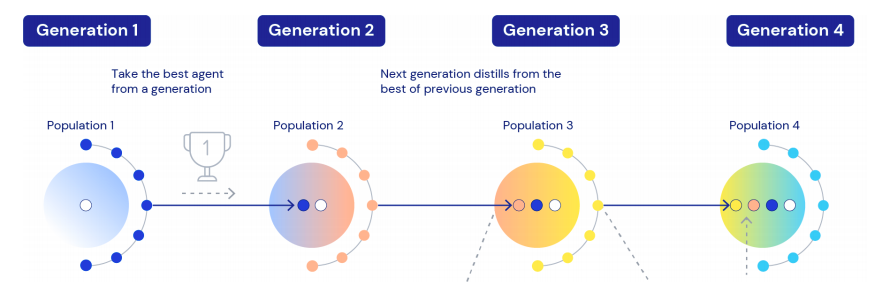
最后,我们将多个训练运行链接在一起,这样每一代代理都可以引导上一代代理。
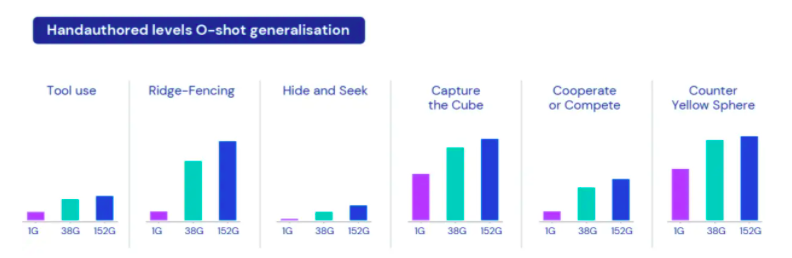
结果显示,智能体在泛化能力上有很好的表现,只需对一些新的复杂任务进行 30 分钟的集中训练,智能体就可以快速适应。
经过5代训练,智能体在 XLand 的 4000 个独立世界中玩大约 70万个独立游戏,涉及340 万个独立任务的结果,最后一代的每个智能体都经历了 2000 亿次训练步骤。
目前,智能体已经能够顺利参与几乎每个评估任务,除了少数即使是人类也无法完成的任务。
未来一天,当AI也能够在「元宇宙」中自己学习演化,《西部世界》那样的场景是否会在我们身边降临?

参考资料:
https://deepmind.com/blog/article/generally-capable-agents-emerge-from-open-ended-play
