杀疯了!通过游戏“元宇宙”,Deepmind让AI学会玩各种没玩过的游戏,骚操作不断

大数据文摘出品
对于AI来说,完成一个单一任务或许相对简单,但是涉及到合作和博弈时,AI往往显得有些愚蠢。
AI研究机构一直致力于通过一些涉及到合作和博弈的游戏来开发AI在这方面的能力。
在2019年,文摘菌就报道过,OpenAI开发的“捉迷藏AI”通过5亿轮次的训练成功学会了在游戏中相互合作和与对手博弈。
近期,Deepmind将这方面的研究又向前推进了一步。
根据7月27日Deepmind官方博客的介绍,Deepmind最新的AI智能体可以在没有玩过一款游戏的时候,而这一切的背后居然是Deepmind搭建的一款游戏“元宇宙”。
我们来看看怎么回事。
为了驾驭各种小游戏,Deepmind的AI骚操作不断
论文总是枯燥的,所以文摘菌先带大家看一看Deepmind的演示,看看这些AI在没玩过这些游戏的情况下,是如何通过各种骚操作赢的游戏的。
先来一个OpenAI之前探索过的捉迷藏游戏,下面这张图中正在追赶的是蓝色的AI小人,左上角是它的第一视角,而躲藏的是红色AI小人。

为了躲避蓝色小人的追捕,红色小人果断进入了一个从未探索果过的陌生地域,还顺手将一块板子横在身后。要注意的是,双方AI都没有玩过这款游戏。
不过,蓝色AI小人也不是吃素的,在另一个地图上,蓝色AI小人丢失了自己的目标,但是他结合地形发现了更好的追捕方法——登上制高点。最终,红色AI小人被抓到了。

上面是一款博弈的游戏,下面我们来看一款相互合作的游戏。游戏的目标很简单,两个AI只要有一个到达一个高台上的紫色塔尖就行,于是当其中一个AI成功将一款板子搭到了高台上,任务便成功完成了。

不过这远没有结束,目标是接触到塔尖,而不是非得爬上去,所以AI又成功发现了另一个更简单的方法,直接用一款板子将紫色塔尖砸下来不久行了。

下一个游戏也是合作类的,目标是阻止紫色的球滚落到红色的地面。这次游戏两个AI一共探索了三种方法,第一种是用自己的身体挡住小球,显然,这个方法比较低效;
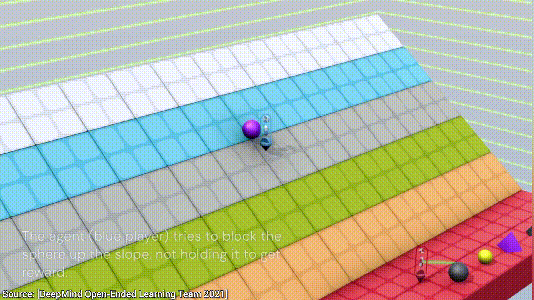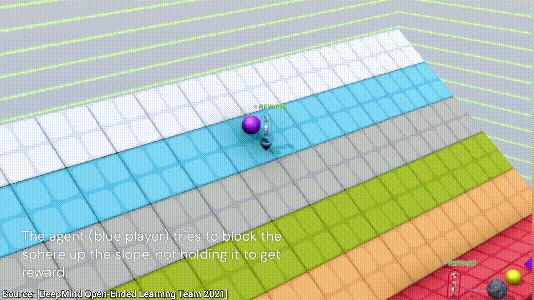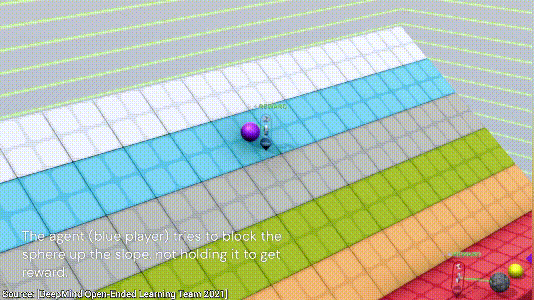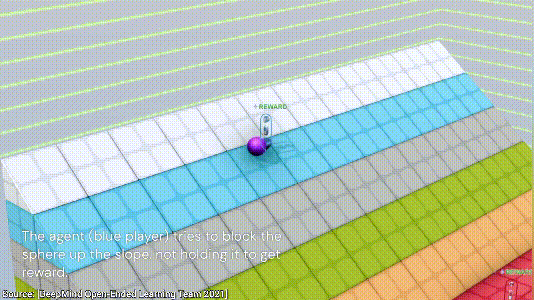
第二种方法是借助两侧的墙面,将小球挤到墙角不动就行;
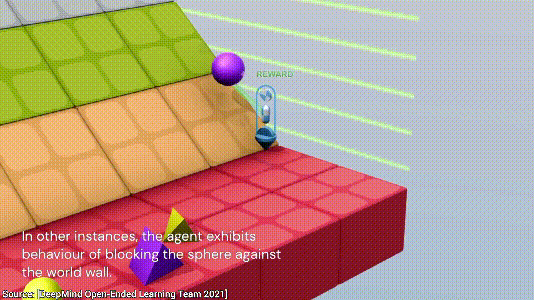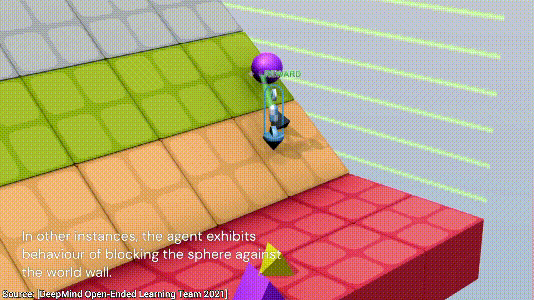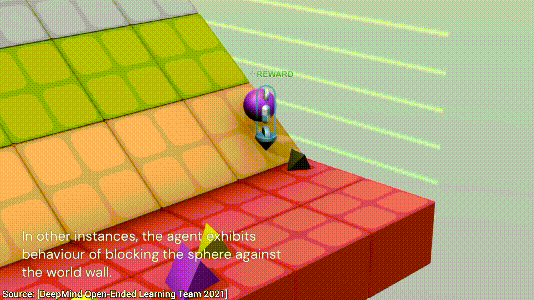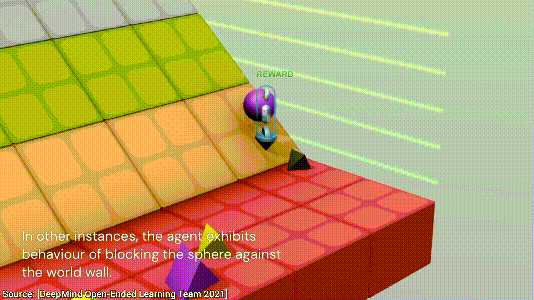
最后,AI发现了一个最简单的方法,直接将小球放到一块板子上,小球不就永远不会跟地板接触了,nice~

最后再来看一个登顶小游戏,两个AI比赛,成功站立在白色高台上的获胜,首先是蓝色AI小人先找到了白色高台并且登了上去,在它以为自己已经获胜的时候,红色AI小人直接过来,将蓝色AI小人干掉,自己留在了白色高台上。

上面几款游戏都是AI从未玩过的,但显然AI在接触一会之后,都会成功找到获胜的方法,这中间有的是依靠合作,有的则需要博弈。
Deepmind的这个成就让大家似乎见到了通用人工智能的曙光,也许在人类看来这些AI或许还很笨,但是最起码,他们不再每玩一个游戏就要训练上亿次了。
这一切,都要归功于Deepmind打造的游戏“元宇宙”。
为了让AI智能体学会举一反三,Deepmind打造包含数十亿任务的游戏“元宇宙”
为了达到轻易上手各种游戏的效果,Deepmind为这些AI智能体打造了一个包含数十亿游戏任务的“元宇宙”,名为XLand。

在这个游戏“元宇宙”中,无数的“游戏星球”组成了“游戏星系”,每个星球上的游戏按竞争性、平衡性、可选则性、探索难度四个纬度进行区分。
比如左上角那个例子,游戏双方需要将小球赶到自己的区域才算获胜,“不是你死就是我亡”,一点合作的机会都没有,所以它的竞争性指标直接被拉满了。

而右上角那个游戏,则是要求将几何体按颜色归类到一起,多个智能体合作完成任意一组配对就可以,所以竞争性很低,但是可选择性很强。

在学习的过程中,Deepmind让这些智能体AI由易到难开始学习,不断补齐在竞争性、平衡性、可选则性、探索难度这是个方面的短板,每成功解锁一个游戏,AI都会获得奖励,从而一步一步变成游戏大师。
除了由易到难的训练顺序,Deepmind的研究人员的训练方法也很符合人类的习惯,通过估计游戏的子目标,要想达到胜利,需要先完成什么,后完成什么,这样一步步持续引导智能体的注意力。
同时,为了让智能体更加多才多艺,获得更加泛化的能力,研究人员设定在学习时,每个新任务都要基于通关的旧任务生成,保持学习的连续性。
最终,通过四次迭代,产生出的第五代就可以更好的适合各种环境,各种合作和博弈任务。最后的第五代智能体在XLand 4000多个“星球”中共玩了70万个游戏,经历了2000亿次训练,完成了340万个独特任务。
这样的开放式训练让一些基于强化学习的智能体甚至可以达到零样本学习。
这种面对任务一看就会的AI,离我们心里的通用人工智能还有多远?
论文链接:
相关报道:
https://deepmind.com/research/publications/2021/open-ended-learning-leads-to-generally-capable-agents