
ACL 2021 | 腾讯AI Lab、港中文杰出论文:用单语记忆实现高性能NMT

来源:机器之心 本文约3200字,建议阅读7分钟 在 ACL 2021 的一篇杰出论文中,研究者提出了一种基于单语数据的模型,性能却优于使用双语 TM 的「TM-augmented NMT」基线方法。

首先,跨语言记忆检索器允许大量的单语数据作为 TM; 其次,记忆检索器和 NMT 模型可以联合优化以达到最终的翻译目标。
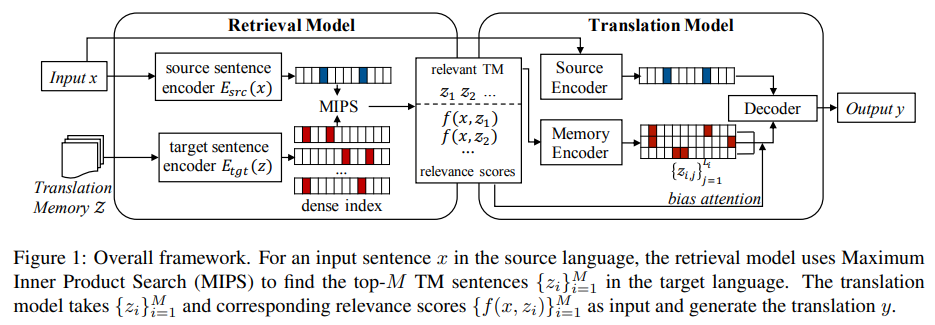
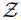 中句子的集合。给定源语言中的输入 x,检索模型首先会根据相关函数
中句子的集合。给定源语言中的输入 x,检索模型首先会根据相关函数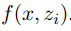 ,选择一些来自 Z 的可能有用的句子
,选择一些来自 Z 的可能有用的句子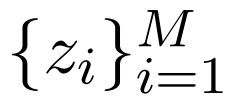 ,其中
,其中 。然后,翻译模型以检索到的集合
。然后,翻译模型以检索到的集合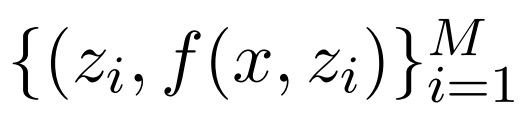 和原始输入 x 为条件,使用概率模型
和原始输入 x 为条件,使用概率模型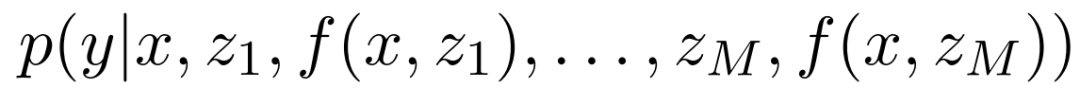 来生成输出 y。
来生成输出 y。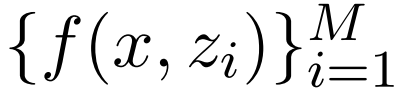 也是翻译模型输入的一部分,它能够鼓励翻译模型更多地关注更相关的句子。在训练期间,该研究借助翻译参考的最大似然改进了翻译模型和检索模型。
也是翻译模型输入的一部分,它能够鼓励翻译模型更多地关注更相关的句子。在训练期间,该研究借助翻译参考的最大似然改进了翻译模型和检索模型。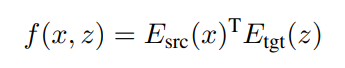
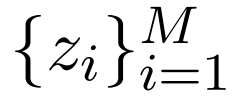 、相关性分数
、相关性分数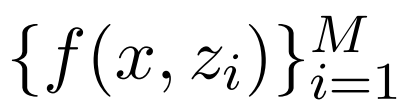 ,翻译模型会定义一个如下形式的条件概率
,翻译模型会定义一个如下形式的条件概率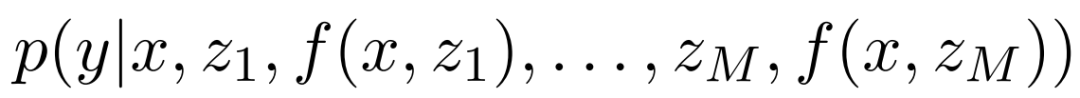
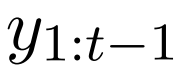 和源编码器的输出,生成隐藏状态 h_t。然后隐藏状态 h_t 通过线性投影转换为 next-token 概率,接着会有一个 softmax 函数操作,即
和源编码器的输出,生成隐藏状态 h_t。然后隐藏状态 h_t 通过线性投影转换为 next-token 概率,接着会有一个 softmax 函数操作,即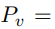
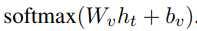
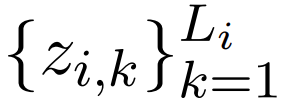 ,其中 L_i 是 token 序列 z_i 的长度。研究者计算了所有 TM 语句的交叉注意力:
,其中 L_i 是 token 序列 z_i 的长度。研究者计算了所有 TM 语句的交叉注意力: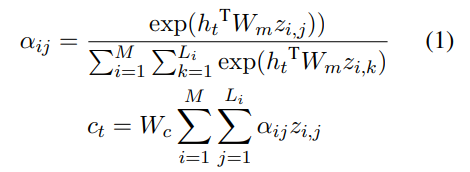
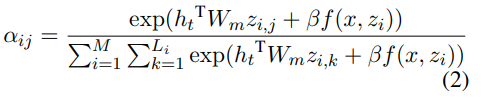
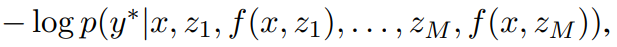 中使用随机梯度下降来优化模型参数 θ 和 φ,其中
中使用随机梯度下降来优化模型参数 θ 和 φ,其中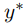 指参考翻译。
指参考翻译。 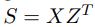 是一个相关性分数的 (B×B) 矩阵 ,其中每一行对应一个源语句,每列对应一个目标语句。当 i = j 时,任何
是一个相关性分数的 (B×B) 矩阵 ,其中每一行对应一个源语句,每列对应一个目标语句。当 i = j 时,任何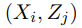 对都应该对齐。目标是最大化矩阵对角线上的分数,然后减小矩阵中其他元素的值。损失函数可以写成:
对都应该对齐。目标是最大化矩阵对角线上的分数,然后减小矩阵中其他元素的值。损失函数可以写成: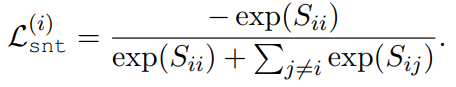
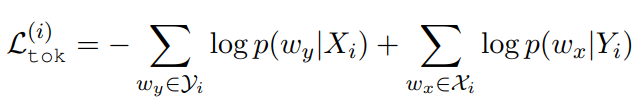
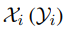 表示第 i 个源(目标)语句中的 token 集,token 概率由线性投影和 softmax 函数计算。
表示第 i 个源(目标)语句中的 token 集,token 概率由线性投影和 softmax 函数计算。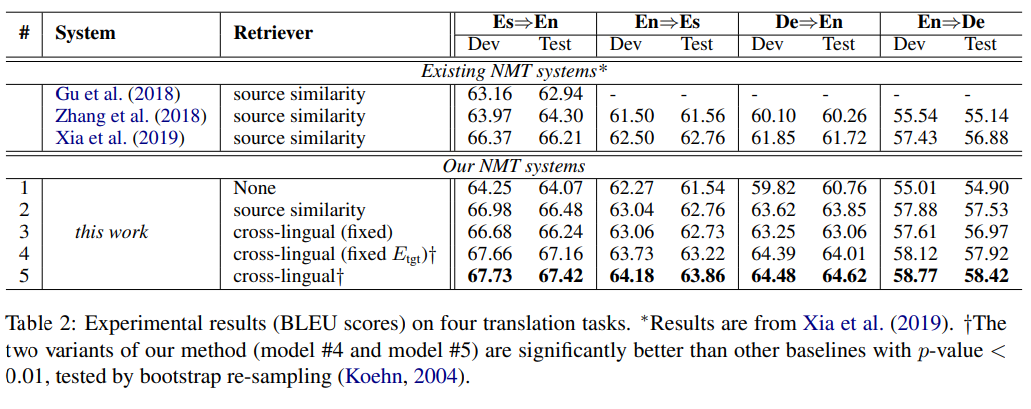
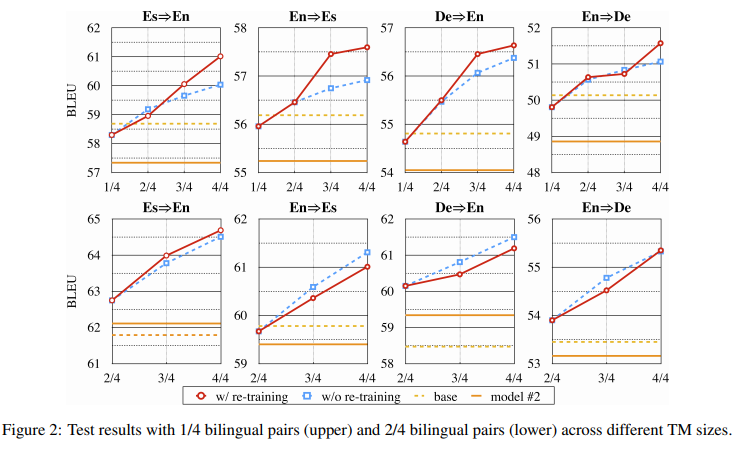
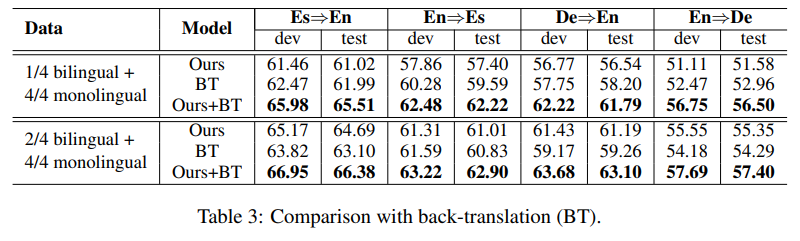
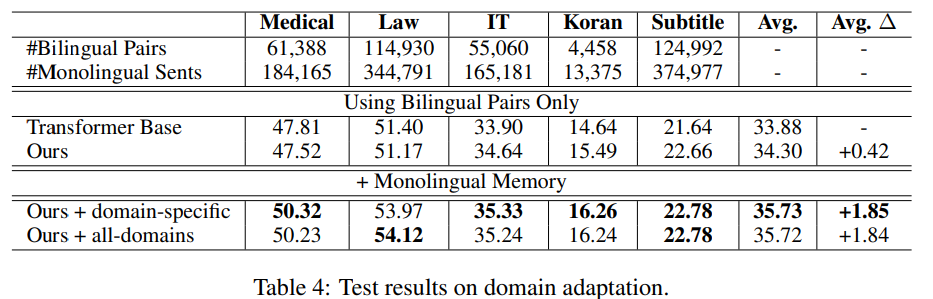
原文链接:
https://mp.weixin.qq.com/s/sFGm8m5Sb-bZeJTop8i0hA
编辑:王菁
校对:林亦霖
评论