
腾讯AI Lab联合清华、港中文,万字解读图深度学习历史、最新进展与应用

极市导读
本文从图神经网络的发展历史、最新研究和应用进展三大方面出发,总结了课程Theme II: Advances and Applications的内容。>>加入极市CV技术交流群,走在计算机视觉的最前沿
一、图与图神经网络
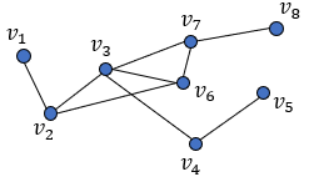
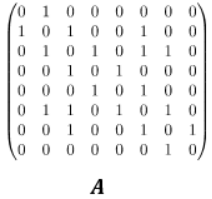
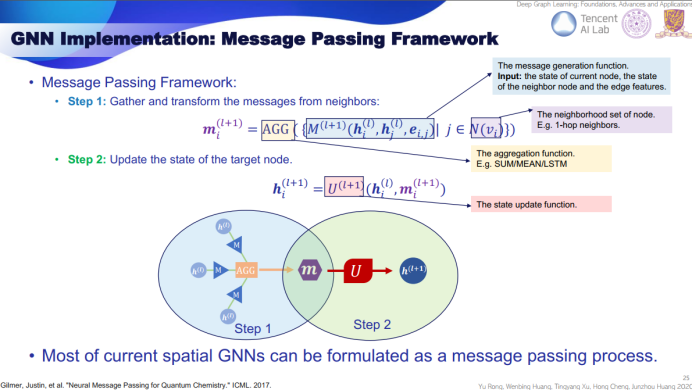
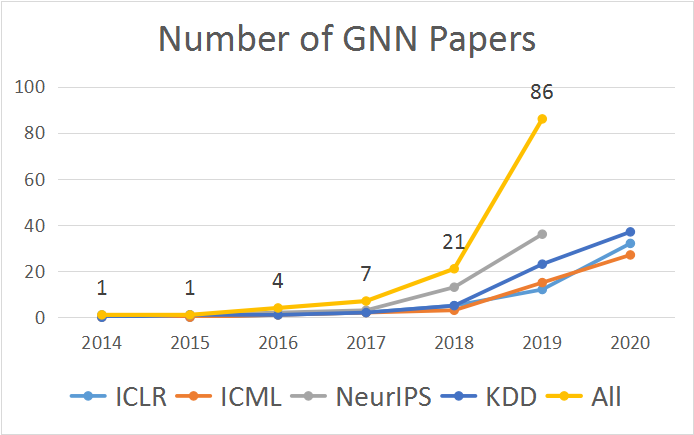
变体卷积:Lanczos 网络(使用 Lanczos 算法来获取图拉普拉斯的低秩近似)、图小波神经网络(使用小波变换替代傅里叶变换)、双曲 GCN(将 GCN 构建到双曲空间中)。 注意力机制:图注意力网络(使用可学习的自注意力替换固定的聚合权重)、门控注意力网络(加入了可学习的门来建模每个头的重要度)、谱式图注意力网络(将注意力应用于谱域中的高 / 低频组件)。 图池化:SAGE(自注意图嵌入,在池化时使用自注意力来建模节点重要度)、通过图剪切实现图池化(通过图剪切算法得到的预训练子图实现图池化)、可微分图池化(DIFFPOOL,通过学习聚类分配矩阵以分层方式来聚合节点表征)、特征池化(EigenPooling,通过整合节点特征和局部结构来获得更好的分配矩阵)。 高阶 GNN:高阶 GNN 是指通过扩展感受野来将高阶相近度(high-order proximities)编码到图中。高阶相近度描述的是距离更多样的节点之间的关系,而不仅是近邻节点之间的关系。这方面的研究工作包括 DCNN(通过把转移矩阵的幂级数堆叠起来而将邻接矩阵扩展为张量,然后相互独立地输出节点嵌入和图嵌入)、MixHop(使用了归一化的多阶邻接矩阵,然后汇集各阶的输出,从而同时得到高阶和低阶的相近度)、APPNP(使用了个性化 PageRank 来为目标节点构建更好的近邻关系)。
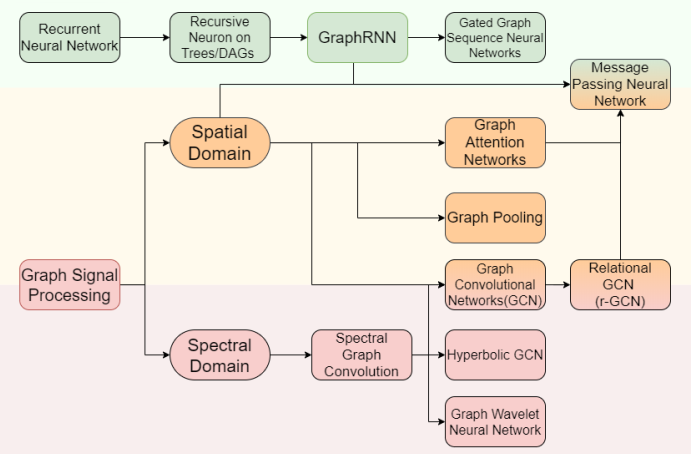
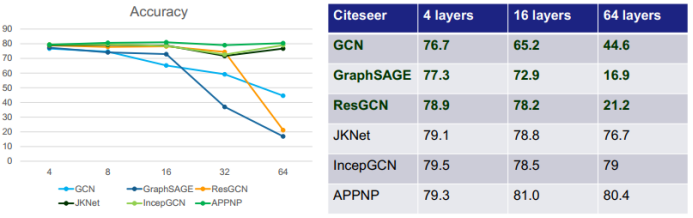
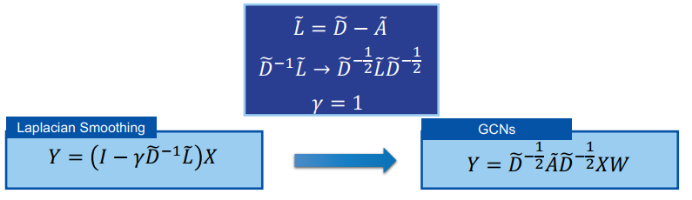
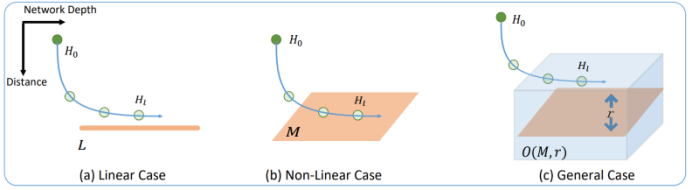
二、图神经网络的研究进展
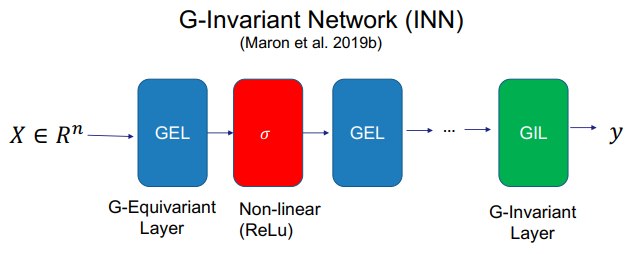
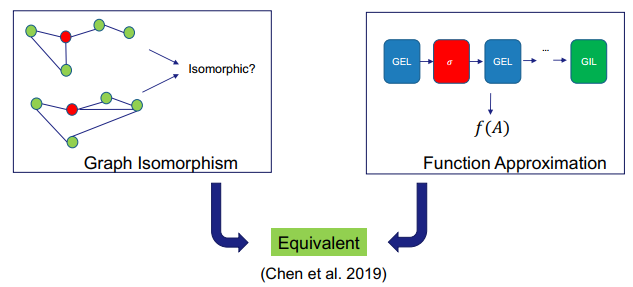
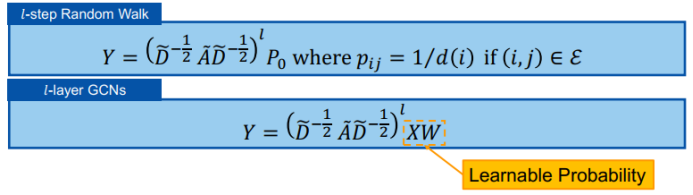
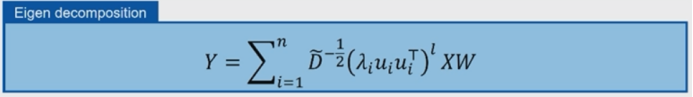
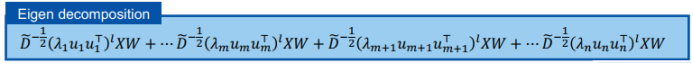
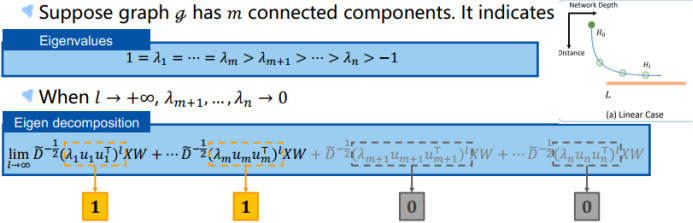
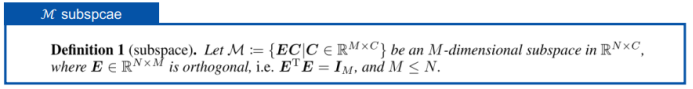
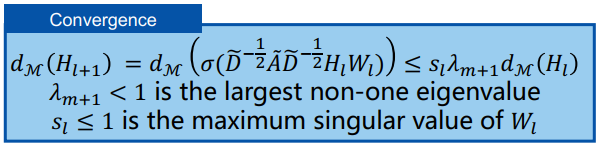
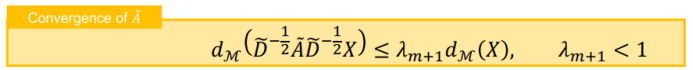
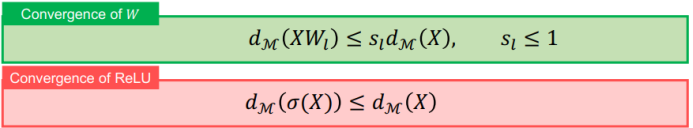
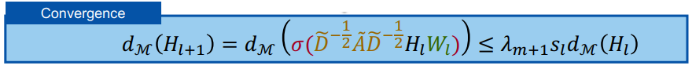
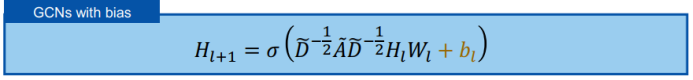
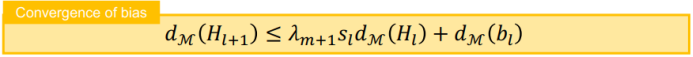
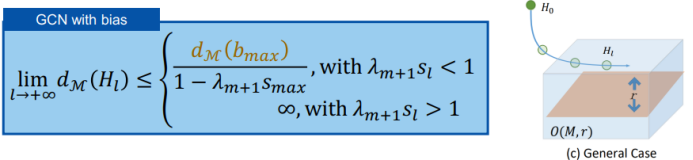
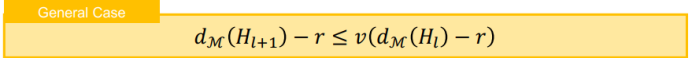

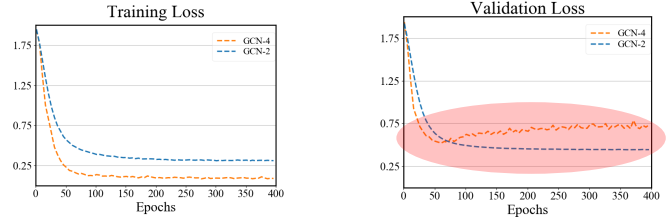
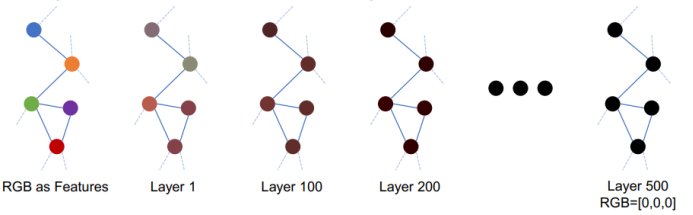
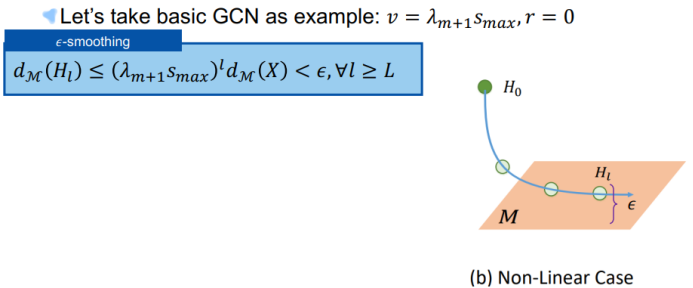
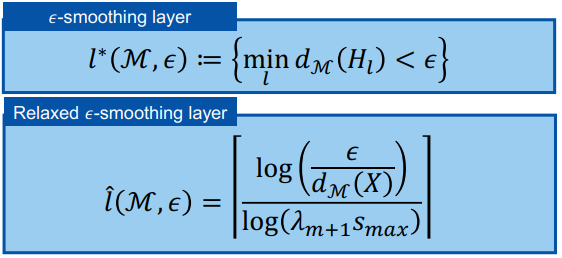
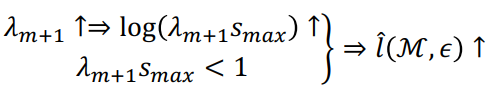
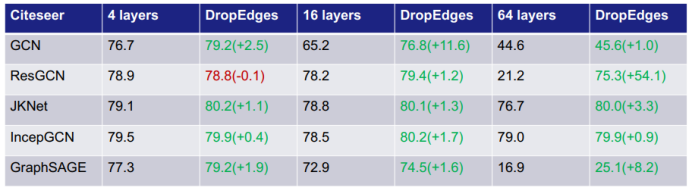
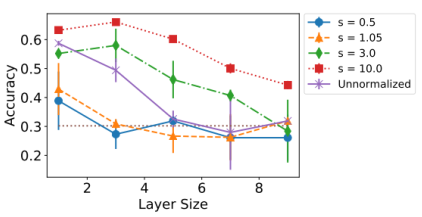
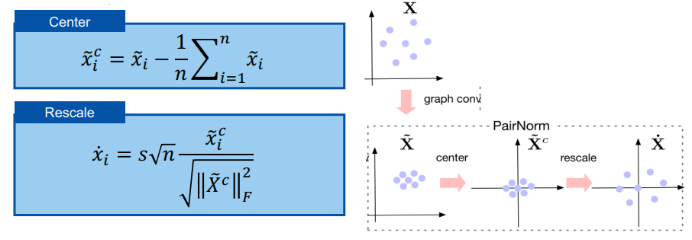
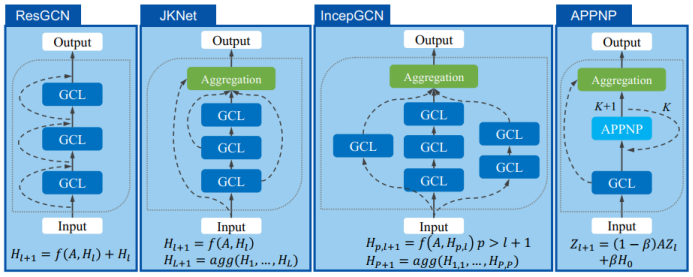
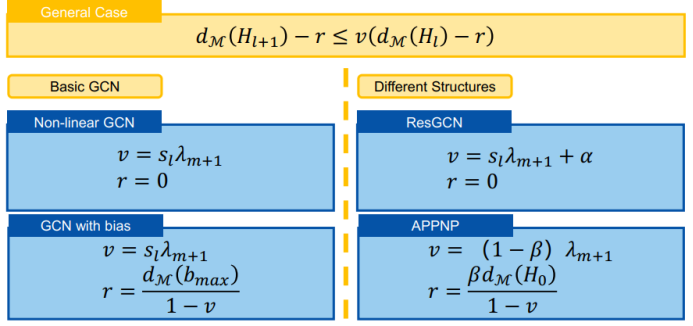
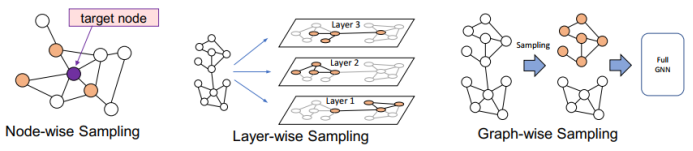
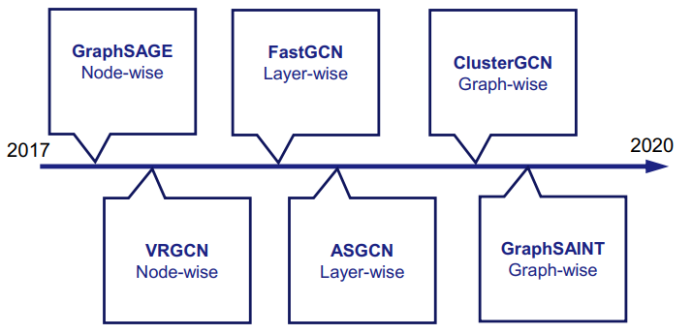
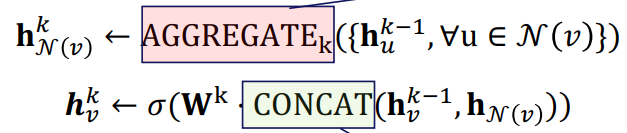
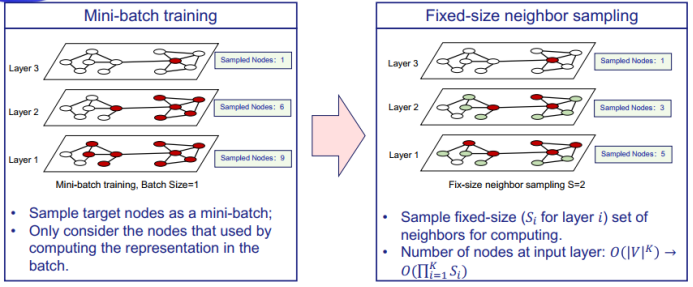
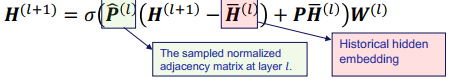

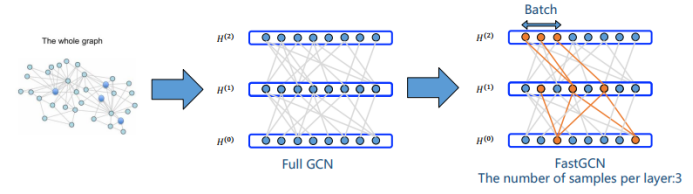
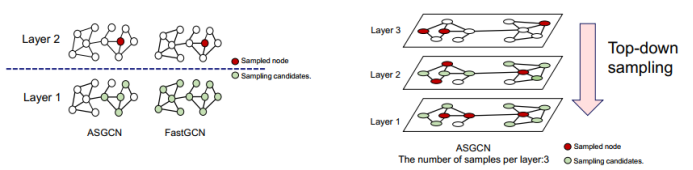

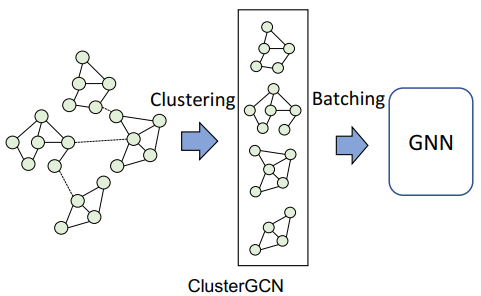
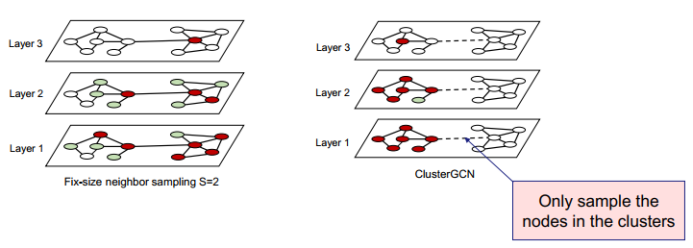
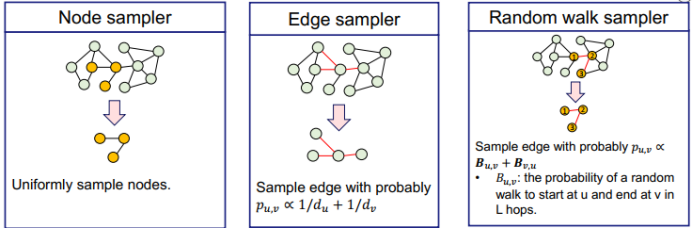
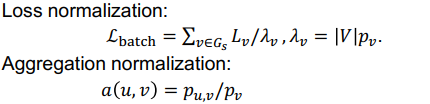
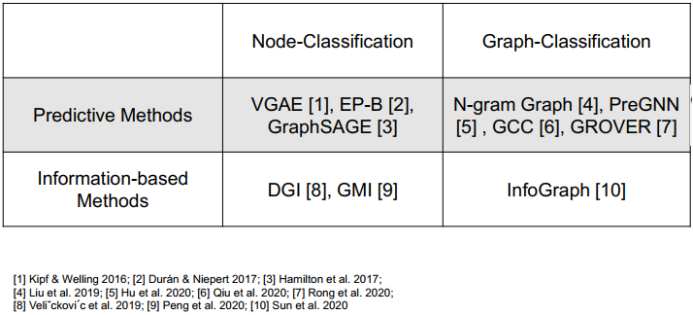
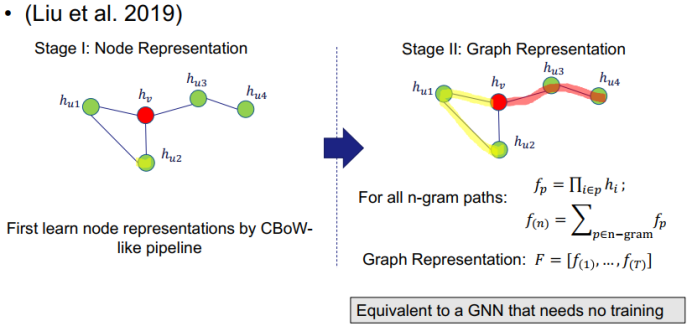
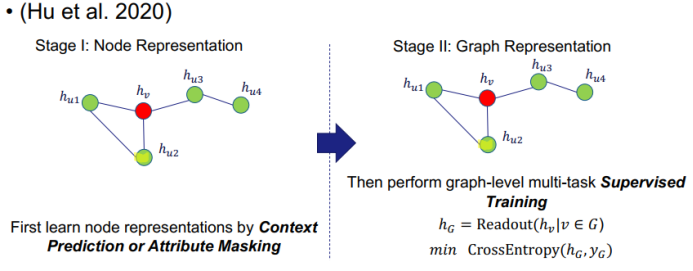
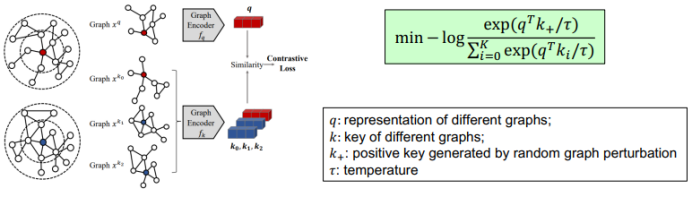
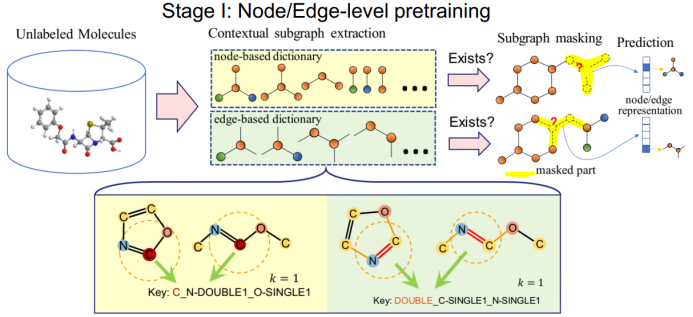
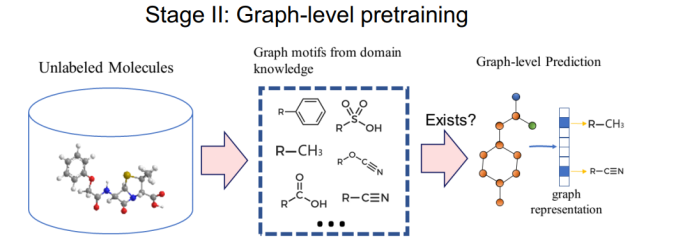
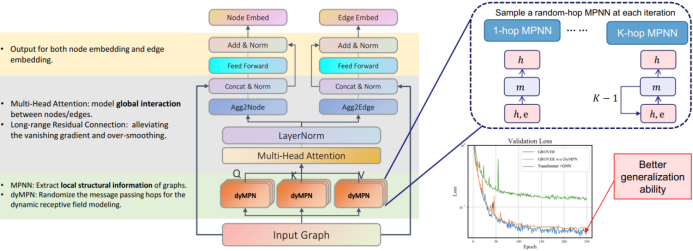

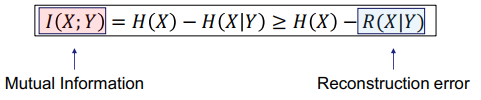

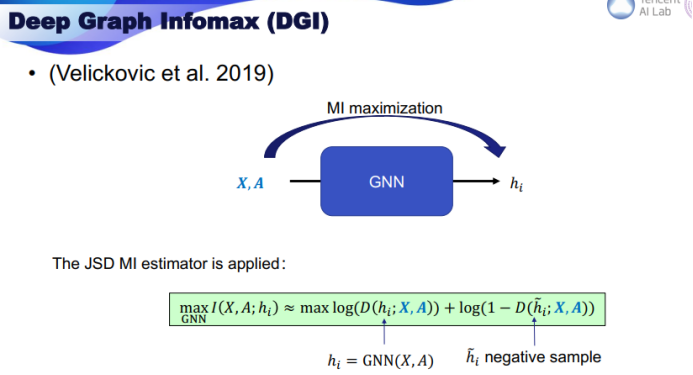
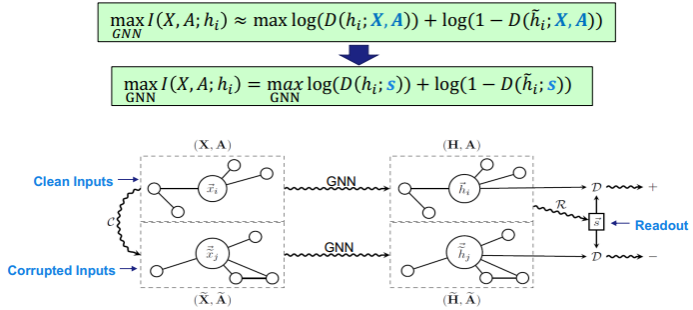
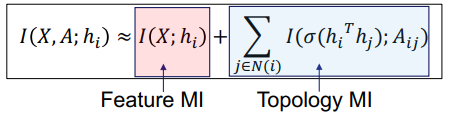

三、图神经网络的应用进展
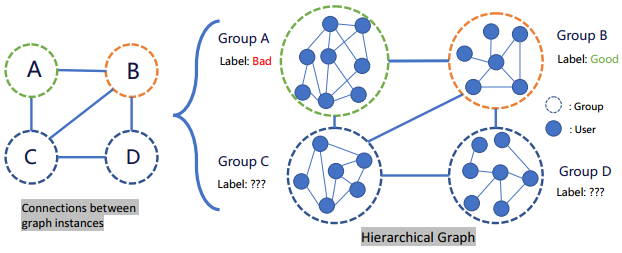
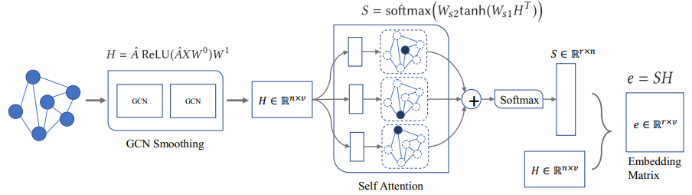
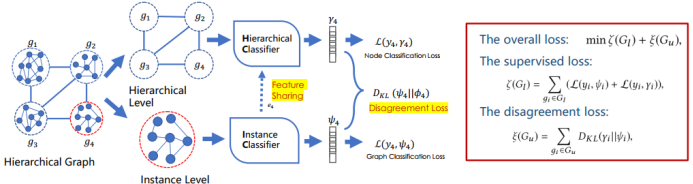
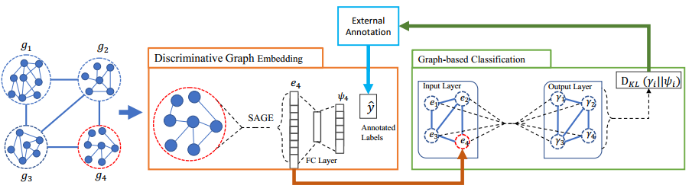
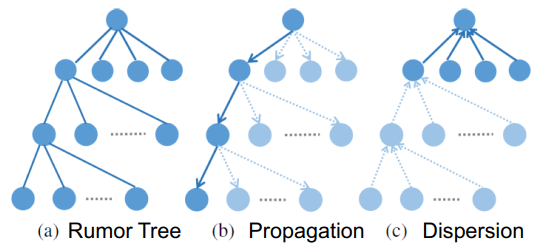
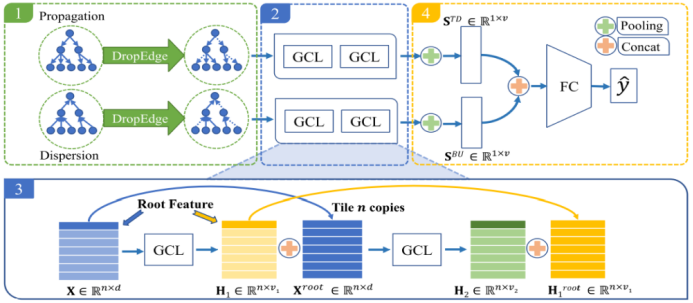
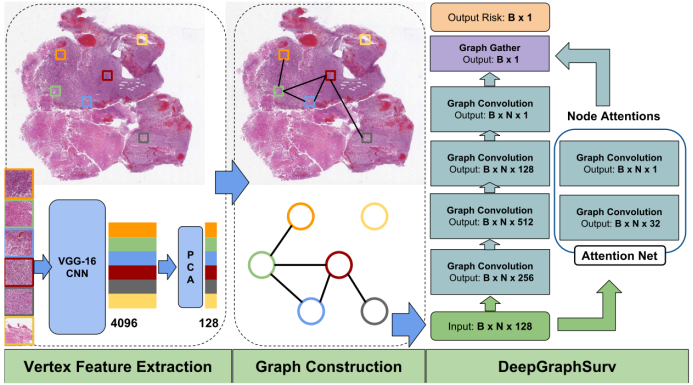
四、总结和展望
推荐阅读

评论