
Uber:大规模、半自动化 Go GC 调优
Uber 是国外大规模使用 Go 的公司之一,在 GitHub 上,他们开源了不少 Go 相关项目。最出名的有以下几个:
zap fx、dig guide
其中 guide 是他们内部的 Go 编码规范,目前已经被翻译成了多国语言,其中包括简体中文版本:https://github.com/xxjwxc/uber_go_guide_cn。
Uber 更多内容开源项目可以访问他们的 GitHub 首页:https://github.com/uber-go。
此外,https://github.com/jaegertracing/jaeger 也是 Uber 开发的,之后捐赠给 CNCF,这是一个分布式追踪平台,用于监控基于微服务的分布式系统。
因此他们在 Go 上有很多经验。本文介绍 Uber 如何在 30 个关键任务服务中节省 7 万个内核。
本文作者是 Cristian Velazquez,他是 Uber Maps Production Engineering 团队的 Sr Production Engineer II。他负责跨多个组织的多个效率计划,其中最相关的是 Java 和 Go 的垃圾收集调优。
1、介绍
实现盈利的方式有开源和节流,对于 Uber 技术团队(其他公司技术团队其实也类似)来说,提升资源利用率,进而减少服务器数量,这是减少成本的一种方式。有些公司通过换语言实现,比如 Python 换为 Go 等。而对 Go 服务来说,可能最有效的工作是针对 GOGC 的优化。在本文中,我们将分享在高效、低风险、大规模、半自动化的 Go GC 调优机制方面的经验。
Uber 有数千个微服务,并由基于云原生和基于调度程序的基础设施提供支持,这些服务大部分是用 Go 编写的。我们的 Maps Production Engineering 团队之前在 Java 微服务 GC 调优方面有很多经验,也取得了很好的效果,现在这些经验在 Go GC 方面也发挥了重要的作用。
2021 年初,我们探索了对 Go 服务进行 GC 调优的可能性。我们运行了几个 CPU 配置文件来评估当前的事务状态,我们发现 GC 是绝大多数关键任务服务的 CPU 最大消耗者。以下是一些 CPU 配置文件的表示,其中 GC(由 runtime.scanobject 方法标识)消耗了分配的计算资源的很大一部分。
示例服务 #1:

示例服务 #2

受到这一发现的启发,我们开始为相关服务调整 GC。令我们高兴的是,Go 的 GC 实现和调整的简单性使我们能够自动化大部分检测和调整机制。我们将在以下部分详细介绍我们的方法及其效果。
2、GOGC Tuner
除了触发事件,Go 运行时会定期调用并发垃圾收集器,其中触发事件是基于内存值的。因此, 更多内存对 Go 服务来说更有利,因为它减少了 GC 必须运行的时间。此外,我们意识到我们的主机 CPU 与内存的比例是 1:5(1 核:5 GB RAM),而大多数 Go 服务的配置比例是 1:1 ~ 1:2。因此,我们有信心可以利用更多内存来减少 GC 的 CPU 影响。这是一种与服务无关的机制,如果应用得当,会产生很大的影响。
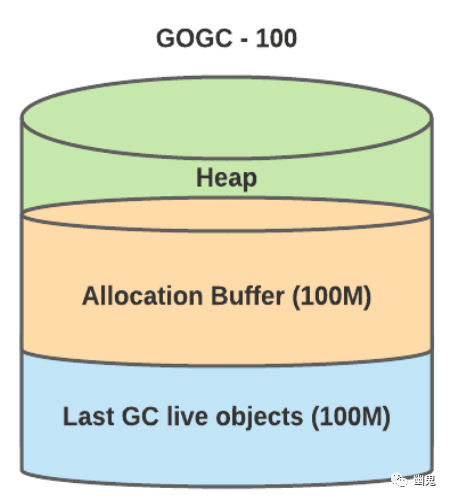
深入研究 Go 的垃圾收集超出了本文的范围,但以下是这项工作的相关部分:Go 中的垃圾收集是并发的,涉及分析所有对象以确定哪些对象仍然可以访问。我们将可到达对象称为“实时数据集”。Go 仅提供一个选项:GOGC, 以实时数据集的百分比表示,用于控制垃圾收集。GOGC 值充当数据集的乘数。GOGC 的默认值为 100%,这意味着 Go 运行时将为新分配保留与实时数据集相同的内存量。例如:
hard_target = live_dataset + live_dataset * (GOGC / 100).
然后,pacer 负责预测触发 GC 的最佳时间,以避免命中硬目标(软目标)。
3、动态多样:一个值无法适应所有场景
我们发现固定的 GOGC 值的调整不适合 Uber 的服务。以下是可能的挑战:
它不知道分配给容器的最大内存,并可能导致内存不足问题。 我们的微服务有各种内存利用率组合。例如,分片系统可以有非常不同的实时数据集。我们在其中一项服务中遇到了这种情况,其中 p99 利用率为 1G 但 p1 为 100MB,因此 100MB 实例具有巨大的 GC 影响。
4、自动化案例
GOGCTuner 是一个库,它简化了为服务所有者调整垃圾收集的过程,并在其之上添加了一个可靠层。
GOGCTuner 根据容器的内存限制(或服务所有者的上限)动态计算正确的 GOGC 值,并使用 Go 的运行时 API 设置它。以下是 GOGCTuner 库功能的详细信息:
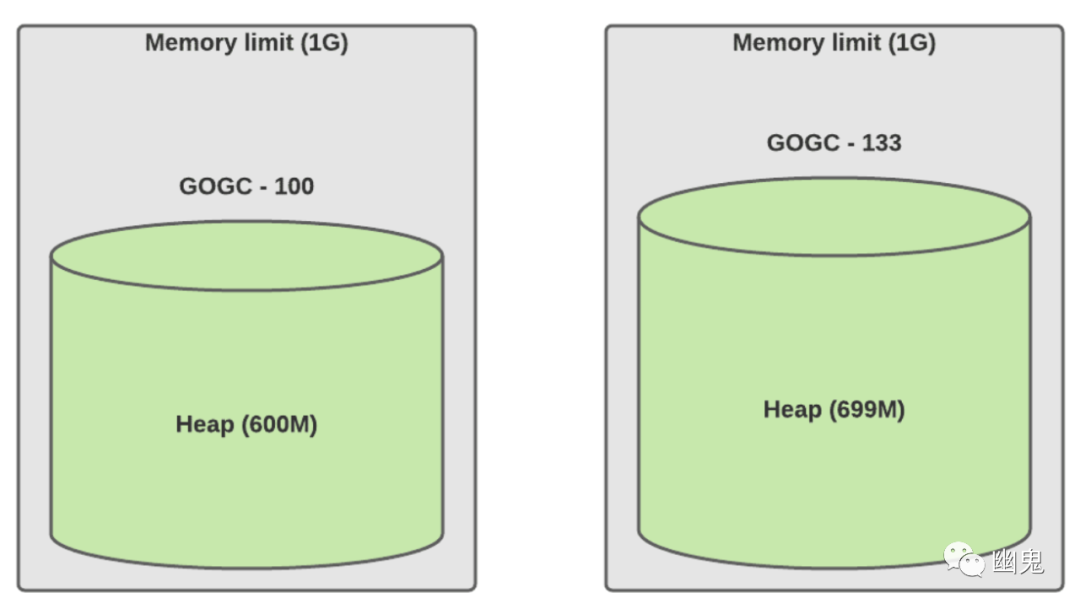
简化配置,便于推理和确定性计算。对于初学者来说,GOGC=100% 的确定性不足,因为它仍然依赖于实时数据集。另一方面,70% 的限制可确保服务始终使用 70% 的堆空间。 防止 OOM(内存不足):该库从 cgroup 读取内存限制并使用 70% 的默认硬限制,根据我们的经验,这是一个安全值。 需要注意的是,这种保护是有限制的。Tuner 只能调整缓冲区分配,因此如果你的服务活动对象高于限制,则 Tuner 将设置默认下限为 1.25X 你的活动对象利用率。 对于极端情况允许更高的 GOGC 值,例如: 正如我们上面提到的,手动 GOGC 不是确定性的。我们仍然依赖实时数据集的大小。如果 live_dataset 将我们的最后一个峰值翻倍了怎么办?GOGCTuner 将以更多 CPU 为代价强制执行相同的内存限制。相反,手动调整可能会导致 OOM。因此,服务所有者过去常常为这些类型的场景提供足够的缓冲。请参见下面的示例:
正常流量(实时数据集为 150M)
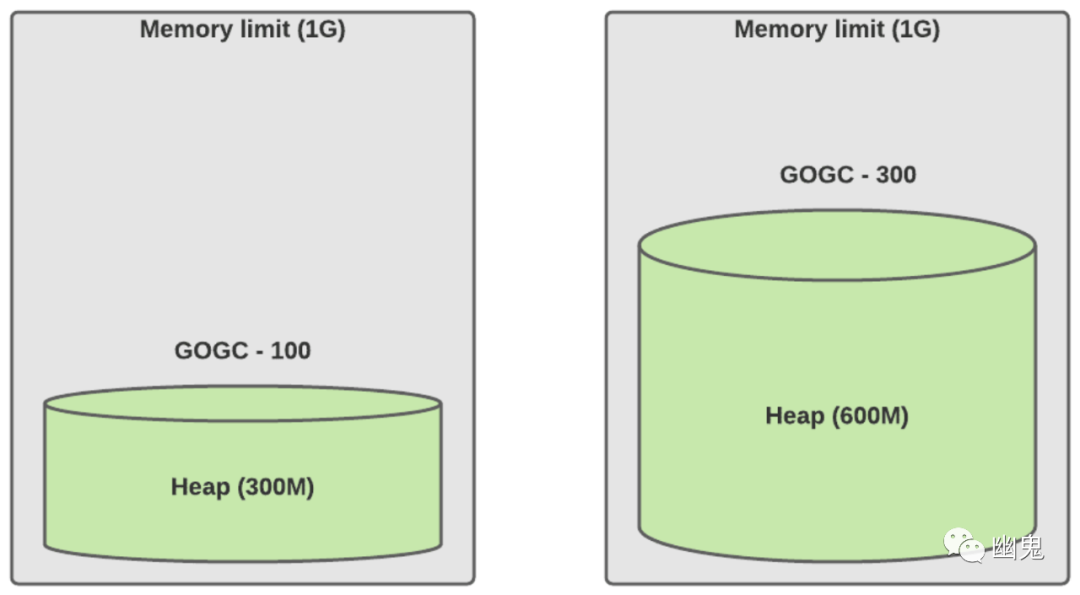
流量增加了 2 倍(实时数据集为 300M)
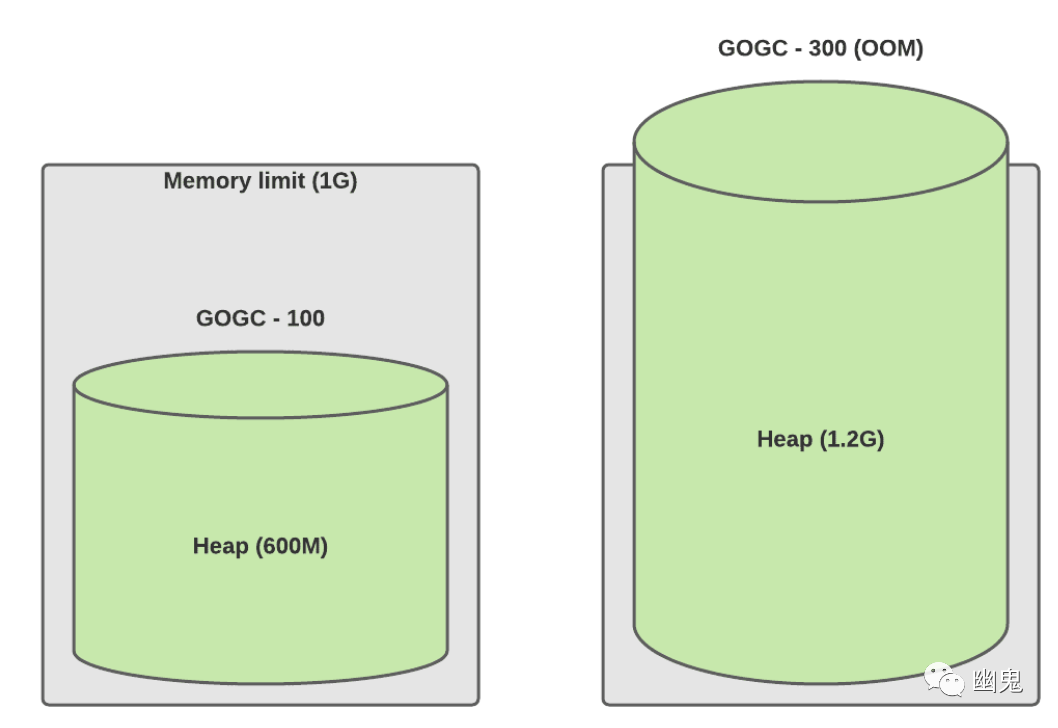
GOGCTuner 达到 70% 时流量增加了 2 倍(实时数据集为 300M)
使用 MADV_FREE[1] 内存策略的服务会导致错误的内存指标。例如,我们的可观察性指标显示 50% 的内存利用率(实际上它已经释放了 50% 中的 20%)。然后服务所有者只是使用这个“不准确”的指标来调整 GOGC。
5、可观察性
我们发现缺乏一些关键指标,这些指标可以让我们更深入地了解每个服务的垃圾收集。
垃圾收集之间的间隔:了解我们是否仍然可以调整很有用。例如,Go 强制每 2 分钟进行一次垃圾收集。如果你的服务仍然具有较高的 GC 影响,但你已经看到此图的 120 秒,这意味着你不能再使用 GOGC 进行调优。在这种情况下,你需要优化分配。
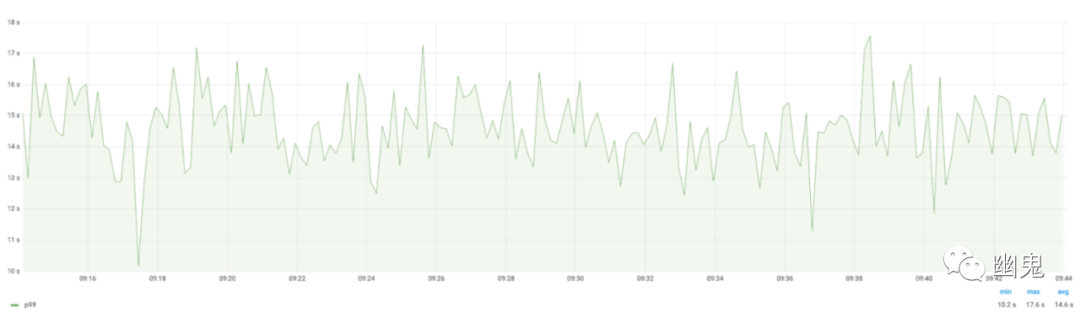
GC CPU 影响:知道哪些服务受 GC 影响最大。
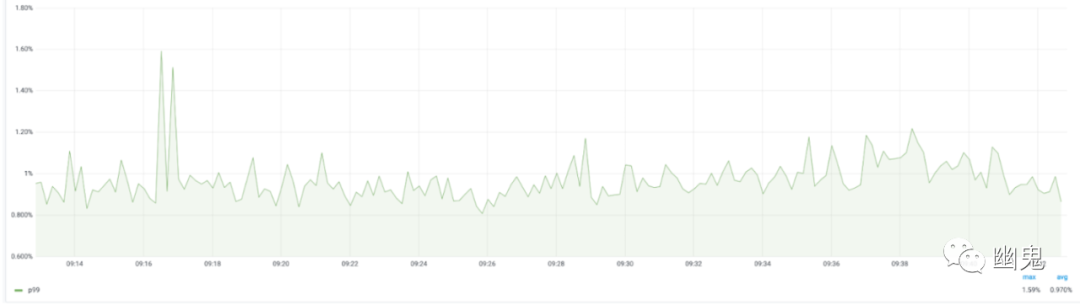
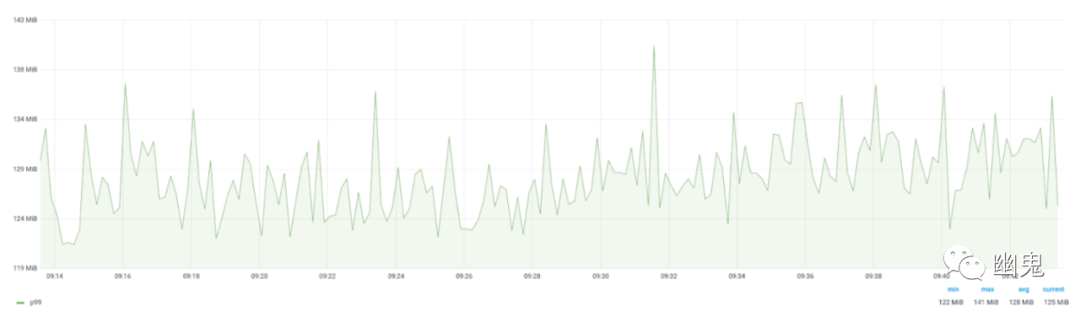
实时数据集(Live dataset)大小:帮助我们识别内存泄漏。服务所有者注意到的问题是他们看到内存利用率有所增加。为了向他们展示没有内存泄漏,我们添加了“实时使用”指标,该指标显示了稳定的利用率。
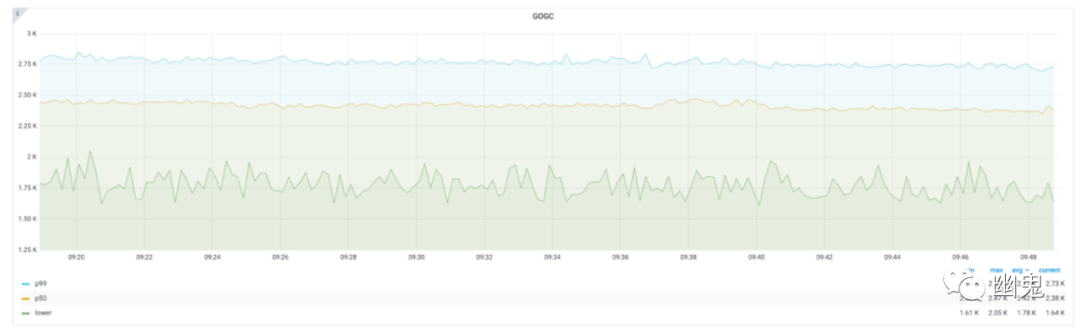
GOGC 值:有助于了解调谐器的反应。
6、实现
我们最初的方法是每秒运行一次代码来监控堆指标,然后相应地调整 GOGC 值。这种方法的缺点是开销开始变得相当大,因为为了读取堆指标,Go 需要执行 STW(ReadMemStats[2]),并且它有点不准确,因为我们每秒可以进行多次垃圾收集。
幸运的是,我们找到一个不错的方法。Go 有终结器(SetFinalizer[3]),它们是在对象将被垃圾收集时运行的函数。它们主要用于清理 C 代码或其他一些资源的内存。我们能够使用一个自引用终结器,它会在每次 GC 调用时自行重置。这使得我们能够减少 CPU 开销。例如:

调用 runtime.SetFinalizer(f, finalizerHandler) 代替直接调用 finalizerHandler 以允许处理程序在每次 GC 上运行;它基本上不会让引用消失,因为它不是保活的昂贵资源(它只是一个指针)。
7、影响
在我们的几十个服务中部署了 GOGCTuner 之后,我们深入研究了其中一些显著的、CPU 利用率提高到两位数的服务。仅这些服务就累计节省了大约 70K 个内核。以下是 2 个这样的示例:
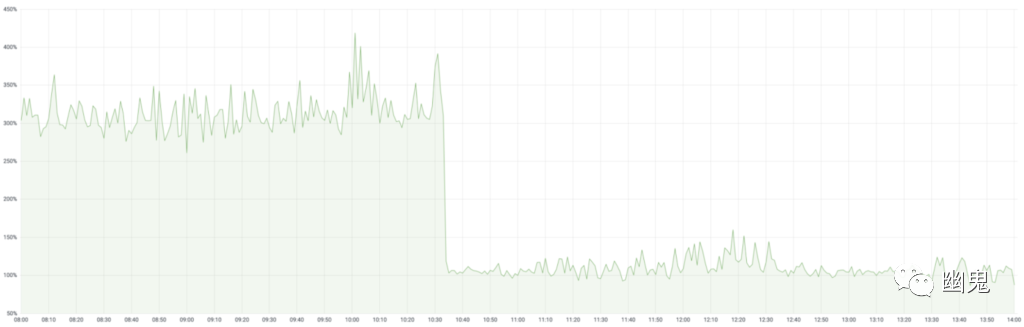
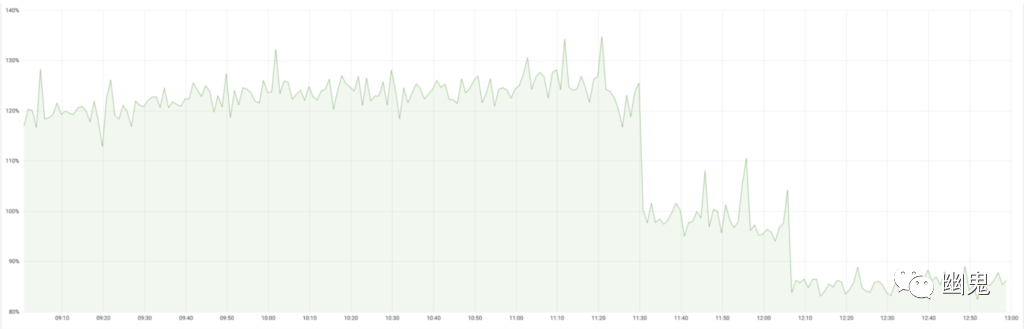
由此产生的 CPU 利用率降低在战术上改善了 p99 延迟(以及相关的 SLA、用户体验),并在战略上改善了容器成本(因为服务是根据其利用率进行扩展的)。
8、总结
垃圾收集(GC)是应用程序中最难以捉摸,同时也是被低估的性能影响因素之一。Go 强大的 GC 机制和简化的调优,加之我们大规模的 Go 服务以及强大的内部平台(如 Go、计算、可观察性),使我们能够产生如此大规模的影响。由于技术和能力的变化,同时问题空间本身的发展,我们希望继续改进我们调整 GC 的方式。
最后再次重申我们在开头提到的内容:没有一个适合所有场景的 GOGC 值。由于公有云和运行在其中的容器化工作负载的性能高度可变,我们认为 GC 性能在云原生设置中将保持可变。再加上我们使用的绝大多数 CNCF 可观测项目都是用 Go 编写的(如 Kubernetes、Prometheus、Jaeger 等),这意味着任何外部的大规模部署也可以从这种努力中受益。
比较可惜的是,目前没看到 Uber 开源了这个工具。
来自公众号:幽鬼
原文链接:https://eng.uber.com/how-we-saved-70k-cores-across-30-mission-critical-services/
参考资料
MADV_FREE: https://man7.org/linux/man-pages/man2/madvise.2.html
[2]ReadMemStats: https://golang.org/pkg/runtime/#ReadMemStats
[3]SetFinalizer: https://golang.org/pkg/runtime/#SetFinalizer
推荐阅读