
教你如何通过分析GC日志来进行JVM调优
不同的垃圾收集器产生的GC日志大致遵循了同一个规则,只是有些许不同,不过对于G1收集器的GC日志和其他垃圾收集器有较大差别,话不多说,正式进入正文。。。
什么时候会发生垃圾收集
首先我们来看一个问题,那就是什么时候会发生垃圾回收?
在Java中,GC是由JVM自动完成的,根据JVM系统环境而定,所以时机是不确定的。当然,我们可以手动进行垃圾回收, 比如调用System.gc()方法通知JVM进行一次垃圾回收,但是具体什么时刻运行也无法控制。也就是说System.gc()只是通知要回收,什么时候回收由JVM决定。
一般以下几种情况会发生垃圾回收:
当Eden区或者S区不够用时 老年代空间不够用了时 方法区空间不够用时 System.gc() 时
注意:可能有些人会以为方法区是不会发生垃圾回收的,其实方法区也是会发生垃圾回收的,只不过大部分情况下,方法区发生垃圾回收之后效率不是很高,大部分内存都回收不掉,所以我们一般讨论垃圾回收的时候也只讨论堆内的回收
怎么拿到GC日志
发生GC之后,我们要分析GC日志,当然就首先要拿到GC日志,上一篇讲述JVM参数分类及常用参数分析时有提到,打印GC日志可以通过如下命令:
-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -Xloggc:D:\\gc.log
配置上之后启动服务:
找到gc.log文件,注意,刚开始如果一次GC都没发生日志是空的,可以等到发生GC之后再打开:
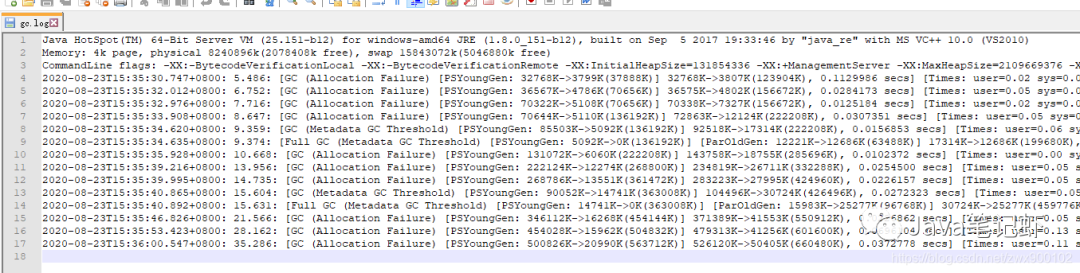
从日志上可以看出来,jdk1.8中默认使用的是Parallel Scavenge+Parallel Old收集器,当然我们也可以通过参数:
-XX:+PrintCommandLineFlags
进行打印:

PS+PO日志分析
前面三行应该都能看懂:
第一行打印的是当前所使用的的HotSpot虚拟机及其对应版本号;
第二行打印的是操作系统相关的内存信息;
第三行打印的是当前Java服务启动后锁配置的参数信息:
CommandLine flags: -XX:-BytecodeVerificationLocal -XX:-BytecodeVerificationRemote -XX:InitialHeapSize=131854336 -XX:+ManagementServer -XX:MaxHeapSize=2109669376 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:TieredStopAtLevel=1 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:-UseLargePagesIndividualAllocation -XX:+UseParallelGC
包括了堆空间打印,以及使用的垃圾收集器及我们自己配置的打印GC日志相关参数等一些信息。
搜索公众号 Java笔记虾,回复“后端面试”,送你一份面试题大全.pdf
下面第4行开始才是我们的GC日志,我们把第4行还有第9行复制出来分析一下:
//第4行
2020-08-23T15:35:30.747+0800: 5.486: [GC (Allocation Failure) [PSYoungGen: 32768K->3799K(37888K)] 32768K->3807K(123904K), 0.1129986 secs] [Times: user=0.02 sys=0.00, real=0.11 secs]
//第9行
2020-08-23T15:35:34.635+0800: 9.374: [Full GC (Metadata GC Threshold) [PSYoungGen: 5092K->0K(136192K)] [ParOldGen: 12221K->12686K(63488K)] 17314K->12686K(199680K), [Metaspace: 20660K->20660K(1067008K)], 0.0890985 secs] [Times: user=0.25 sys=0.00, real=0.09 secs]
1、最前面一个时间2020-08-23T15:35:30.747+0800代表的是垃圾回收发生的时间。
2、紧接着下面的一个数字:5.486表示的是从Java虚拟机启动以来经过的秒数。
3、再往下一个GC (Allocation Failure)表示发生GC的原因,这里是表示分配空间失败而发生了GC。
4、PSYoungGen,PS表示的是Parallel Scavenge收集器,YoungGen表示的是当前发生GC的地方是年轻代,注意,这里不同收集器会有不同的名字,如ParNew收集器就会显示为ParNew等。
5、中括号之内的一个数字32768K->3799K(37888K)这个表示的是:GC前当前内存区域使用空间->GC后当前内存区域使用的内存空间(当前区域的总内存空间)。从这里可以看到,一次GC之后,大部分空间都被回收掉了。
6、中括号之外的数字32768K->3807K(123904K)这个表示的是:GC前Java堆已使用容量->GC后Java堆已使用容量(Java堆使用的总容量)
这里需要注意的是5和6中的这两组数字相减得到的值一般是不相等的,这是因为总空间下面还包括了老年代发生回收后释放的空间大小,可能有人会觉得奇怪,这里明明只有新生代发生了GC,为什么老年代会有空间释放?
不知道大家还记不记得我在前两篇文章中提到了,S区如果空间不够的话会利用担保机制向老年代借用空间,所以借来的空间时可能被释放的。7、0.1129986 secs这个表示的是GC所花费时间,secs表示单位是秒。
8、[Times: user=0.02 sys=0.00, real=0.11 secs] 这一部分并不是所有的垃圾收集器都会打印,user=0.02表示用户态消耗的CPU时间,sys=0.00表示内核态消耗的CPU时间和操作从开始到结束所经过的墙钟时间。
9、最后再看看其他行ParOldGen表示Parallel Old收集器在回收老年代,Metaspace表示的是方法区(jdk1.7是永久代)
10、我们看到第9行Full GC表示发生了Full GC,FullGC=Minor GC+Major GC+Metaspace GC,所以后面可以看到PSYoungGen,ParOldGen,Metaspace三个区域的回收信息,而且第9行对比非常明显,新生代全部回收掉了,老年代回收了一小部分,而方法区一点都没有回收掉,这也体现了三个区域内所存对象的区别。
墙钟时间和cpu时间
墙钟时间(Wall Clock Time)包括各种非运算的等待耗时,例如等待磁盘I/O、等待线程阻塞,而CPU时间不包括这些不需要消耗CPU的时间。
搜索公众号 Java笔记虾,回复“后端面试”,送你一份面试题大全.pdf
CMS日志分析
我们垃圾收集器切换为CMS
-XX:+UseConcMarkSweepGC
注意,CMS也是一款老年代收集器,使用这个参数后新生代默认会使用ParNew收集器
然后重启服务,等候垃圾回收之后,打开gc.log文件。
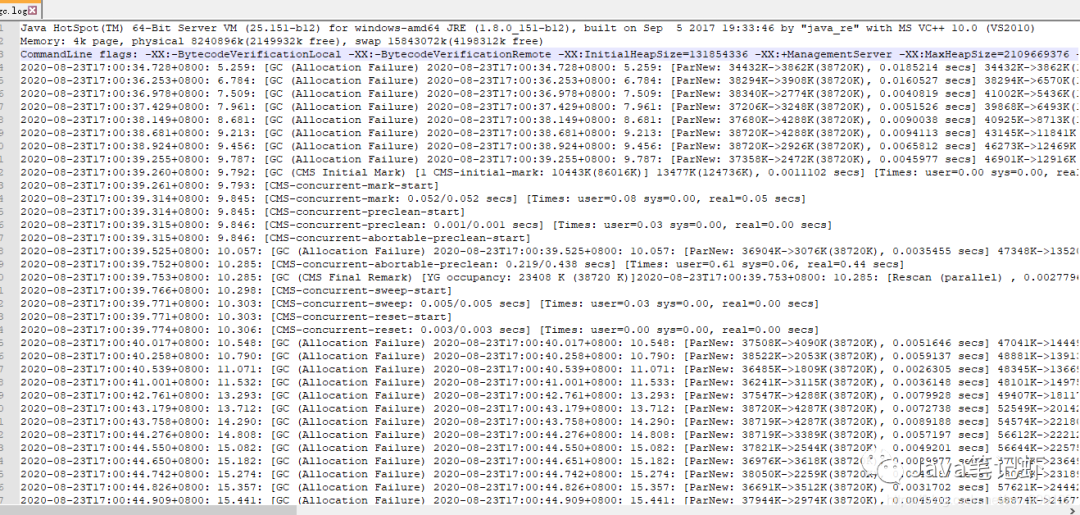
前面两行和上面一样,我们把第三行复制出来看看垃圾收集器是否切换成功:
CommandLine flags: -XX:-BytecodeVerificationLocal -XX:-BytecodeVerificationRemote -XX:InitialHeapSize=131854336 -XX:+ManagementServer -XX:MaxHeapSize=2109669376 -XX:MaxNewSize=348966912 -XX:MaxTenuringThreshold=6 -XX:OldPLABSize=16 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:TieredStopAtLevel=1 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:-UseLargePagesIndividualAllocation -XX:+UseParNewGC
可以看到,CMS和ParNew两个收集器都启用了。打开第4行日志:
2020-08-23T17:00:34.728+0800: 5.259: [GC (Allocation Failure) 2020-08-23T17:00:34.728+0800: 5.259: [ParNew: 34432K->3862K(38720K), 0.0185214 secs] 34432K->3862K(124736K), 0.0188547 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
这里的回收信息和上面一样,也就是新生代名字不一样,这里叫ParNew。我们主要看看老年代CMS的GC日志,我们把一个完成的老年代回收日志复制出来:
2020-08-23T17:00:47.650+0800: 18.182: [GC (CMS Initial Mark) [1 CMS-initial-mark: 30298K(86016K)] 34587K(124736K), 0.0014342 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2020-08-23T17:00:47.651+0800: 18.183: [CMS-concurrent-mark-start]
2020-08-23T17:00:47.712+0800: 18.244: [CMS-concurrent-mark: 0.061/0.061 secs] [Times: user=0.13 sys=0.00, real=0.06 secs]
2020-08-23T17:00:47.712+0800: 18.244: [CMS-concurrent-preclean-start]
2020-08-23T17:00:47.714+0800: 18.245: [CMS-concurrent-preclean: 0.001/0.001 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
2020-08-23T17:00:47.714+0800: 18.246: [CMS-concurrent-abortable-preclean-start]
2020-08-23T17:00:48.143+0800: 18.674: [GC (Allocation Failure) 2020-08-23T17:00:48.143+0800: 18.674: [ParNew: 38720K->4111K(38720K), 0.0101415 secs] 69018K->38573K(124736K), 0.0102502 secs] [Times: user=0.06 sys=0.00, real=0.01 secs]
2020-08-23T17:00:48.451+0800: 18.983: [CMS-concurrent-abortable-preclean: 0.274/0.737 secs] [Times: user=0.94 sys=0.13, real=0.74 secs]
2020-08-23T17:00:48.451+0800: 18.983: [GC (CMS Final Remark) [YG occupancy: 23345 K (38720 K)]2020-08-23T17:00:48.451+0800: 18.983: [Rescan (parallel) , 0.0046112 secs]2020-08-23T17:00:48.456+0800: 18.987: [weak refs processing, 0.0006259 secs]2020-08-23T17:00:48.457+0800: 18.988: [class unloading, 0.0062187 secs]2020-08-23T17:00:48.463+0800: 18.994: [scrub symbol table, 0.0092387 secs]2020-08-23T17:00:48.472+0800: 19.004: [scrub string table, 0.0006408 secs][1 CMS-remark: 34461K(86016K)] 57806K(124736K), 0.0219024 secs] [Times: user=0.05 sys=0.01, real=0.02 secs]
2020-08-23T17:00:48.473+0800: 19.005: [CMS-concurrent-sweep-start]
2020-08-23T17:00:48.489+0800: 19.020: [CMS-concurrent-sweep: 0.015/0.015 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
2020-08-23T17:00:48.489+0800: 19.020: [CMS-concurrent-reset-start]
2020-08-23T17:00:48.492+0800: 19.023: [CMS-concurrent-reset: 0.003/0.003 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
如果不了解CMS垃圾收集器工作机制的,可以参考:
https://blog.csdn.net/zwx900102/article/details/108180739
1、CMS Initial Mark对应的是CMS工作机制的第一步初始标记,主要是寻找GCRoot对象
2、中括号内10443K(86016K)表示的是当前区域已经使用大小和总空间大小
3、中括号外13477K(124736K)表示的是堆内已使用空间大小和堆内总空间大小
4、CMS-concurrent-mark-start这里对应了CMS工作机制中的第二步并发标记。这个阶段主要是根据GCRoot对象遍历整个引用链
5、再往后面一行CMS-concurrent-mark: 0.052/0.052 secs,这里的两个时间,第一个表示该阶段持续的cpu时间和墙钟时间
6、后面的CMS-concurrent-preclean和CMS-concurrent-abortable-preclean对应了预清理和可中断预清理阶段
7、CMS-concurrent-sweep-start对应最终标记,此阶段需要STW,可以看到,在此阶段前发生了一次Young GC,这是为了减少STW时间。
8、CMS-concurrent-sweep并发清除垃圾,CMS-concurrent-reset重置线程
G1日志分析
切换到G1垃圾收集器:
-XX:+UseG1GC
然后重启服务,等待发生垃圾回收之后打开gc.log文件:
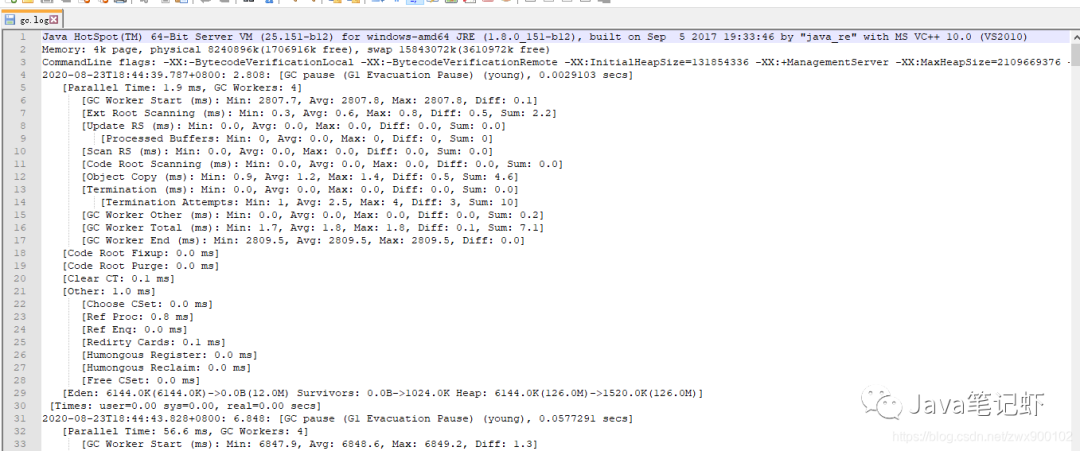
可以看到,这个文件相比较于其他垃圾收集器要复杂的多。我们还是先看下第3行,确认是否使用了G1收集器:
CommandLine flags: -XX:-BytecodeVerificationLocal -XX:-BytecodeVerificationRemote -XX:InitialHeapSize=131854336 -XX:+ManagementServer -XX:MaxHeapSize=2109669376 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:TieredStopAtLevel=1 -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC -XX:-UseLargePagesIndividualAllocation
可以看到确实使用了G1收集器。我们找到一次完整的G1日志,复制出来:
2020-08-23T18:44:39.787+0800: 2.808: [GC pause (G1 Evacuation Pause) (young), 0.0029103 secs]
[Parallel Time: 1.9 ms, GC Workers: 4]
[GC Worker Start (ms): Min: 2807.7, Avg: 2807.8, Max: 2807.8, Diff: 0.1]
[Ext Root Scanning (ms): Min: 0.3, Avg: 0.6, Max: 0.8, Diff: 0.5, Sum: 2.2]
[Update RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Processed Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0]
[Scan RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Code Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Object Copy (ms): Min: 0.9, Avg: 1.2, Max: 1.4, Diff: 0.5, Sum: 4.6]
[Termination (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0]
[Termination Attempts: Min: 1, Avg: 2.5, Max: 4, Diff: 3, Sum: 10]
[GC Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.2]
[GC Worker Total (ms): Min: 1.7, Avg: 1.8, Max: 1.8, Diff: 0.1, Sum: 7.1]
[GC Worker End (ms): Min: 2809.5, Avg: 2809.5, Max: 2809.5, Diff: 0.0]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.1 ms]
[Other: 1.0 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.8 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.1 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 6144.0K(6144.0K)->0.0B(12.0M) Survivors: 0.0B->1024.0K Heap: 6144.0K(126.0M)->1520.0K(126.0M)]
[Times: user=0.00 sys=0.00, real=0.00 secs]
[GC pause (G1 Evacuation Pause) (young), 0.0029103 secs]这里表示发生GC的区域是Young区,后面就是总共耗费的时间。
注意:G1虽然在物理上取消了区域的划分,但是逻辑上依然保留了,所以日志中还是会显示young,Full GC会用mixed来表示。
[Parallel Time: 1.9 ms, GC Workers: 4] 这句表示线程的并行时间和并行的线程数
[GC Worker Start (ms): Min: 2807.7, Avg: 2807.8, Max: 2807.8, Diff: 0.1]这个表示并行的每个线程的开始时间最小值,平均值和最大值以及时间差(Max-Min)。
后面就是一些具体的执行步骤,在这里就不逐行去说明了,如果有兴趣的可以看看文档。这里面有非常详细的解释,不过是英文版本,但是大致应该能看得懂:
https://blogs.oracle.com/poonam/understanding-g1-gc-logs

利用工具分析GC日志
虽然说我们从日志上能看懂GC日志,但是如果需要进行调优,我们最关注的是2个点:
1、吞吐量(Throughput)
吞吐量=运行用户代码时间/(运行用户代码时间+GC时间)2、GC暂停时间(Pause Time)
Stop The World时间
那么我们直接从GC日志上很难看出来这两个指标,如果要靠自己计算去确认问题,我觉得这会是一个噩梦。所以同样的,我们需要有工具来帮助我们分析,下面就介绍2款常用的工具。
gceasy
1、打开官网地址:https://gceasy.io/
2、上传gc日志
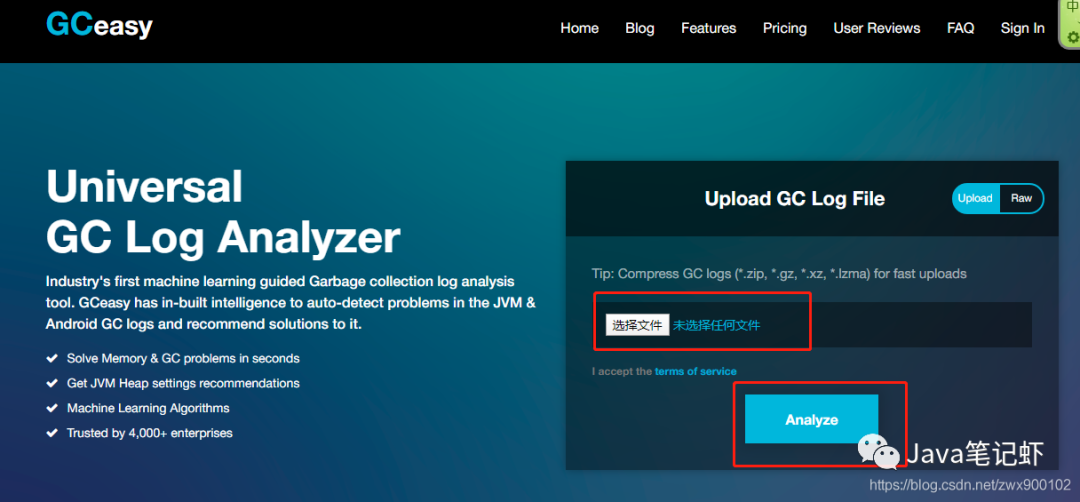
然后可以进入主页面: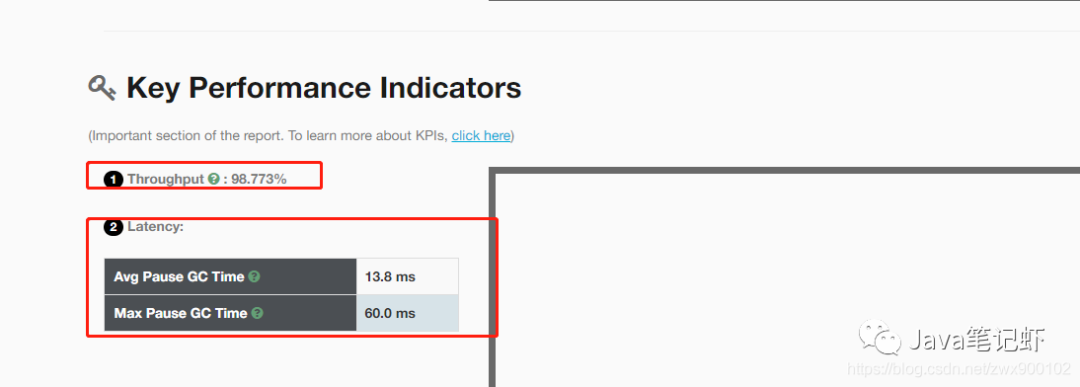
这里已经帮我们把吞吐量和GC暂停时间统计出来了,当然还有其他指标也有统计,有了工具我们就可以对比指标来确认哪种收集器适合自己的系统了。
GCViewer
1、下载gcviewer的jar包
2、执行命令java -jar gcviewer-1.36-SNAPSHOT.jar

打开主界面:
点击File–>Open File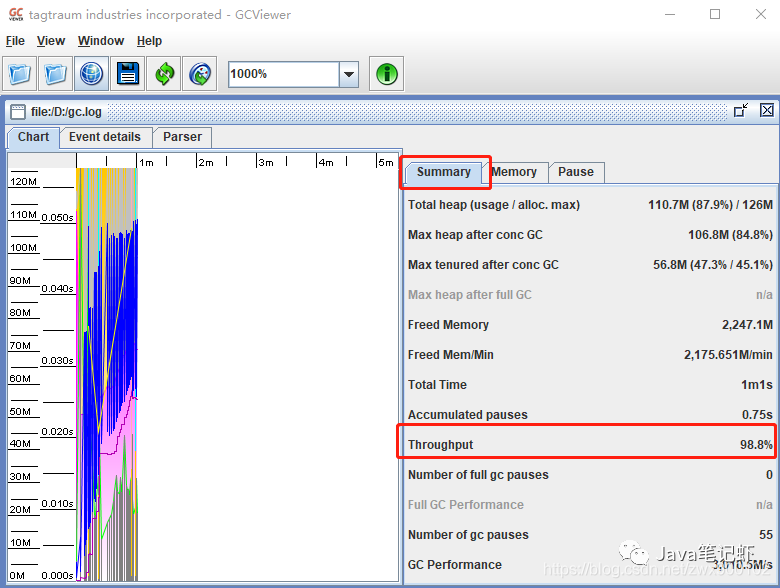
在右边的第一个Summary概要里面可以看到吞吐量的统计。切换到第三个标签Pause:
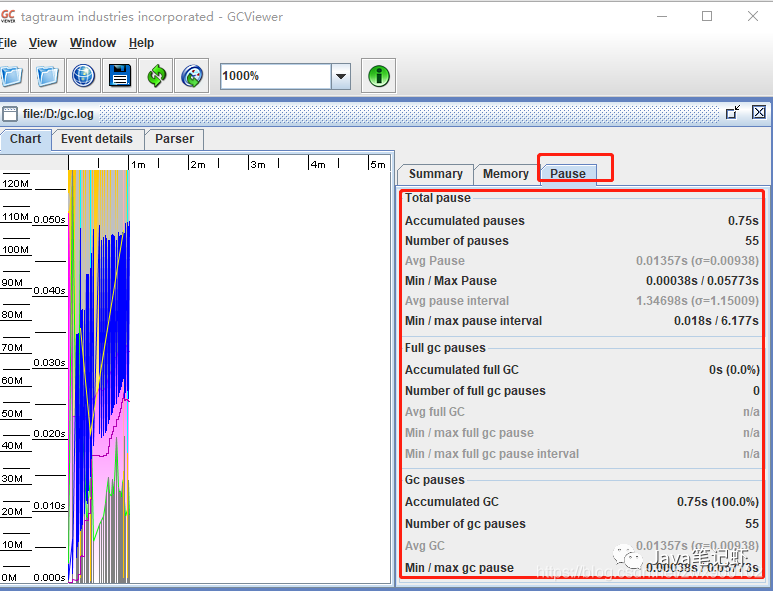
可以查看到各种停顿时间的统计。
总结
本文主要介绍了常用的垃圾收集器的GC日志应该如何进行分析,并且介绍了两款常用的工具来帮助我们更好更直观的分析GC日志。
来源:blog.csdn.net/zwx900102/article/details/108274141
版权申明:内容来源网络,版权归原创者所有。除非无法确认,我们都会标明作者及出处,如有侵权烦请告知,我们会立即删除并表示歉意。谢谢!
