
调优 | 高吞吐量Flume Agent调优小结
点击上方蓝色字体,选择“设为星标”
回复”资源“获取更多资源



前言
所有电商企业在一年一度的双11都要迎来大促与大考,前段时间在配合执行全链路压测的过程中,发现平时不太关注的Flume配置可能存在瓶颈。Flume在笔者负责的实时计算平台里用于收集所有后端访问日志和埋点日志,其效率和稳定性比较重要。除了及时扩容之外,也有必要对Flume进行调优。
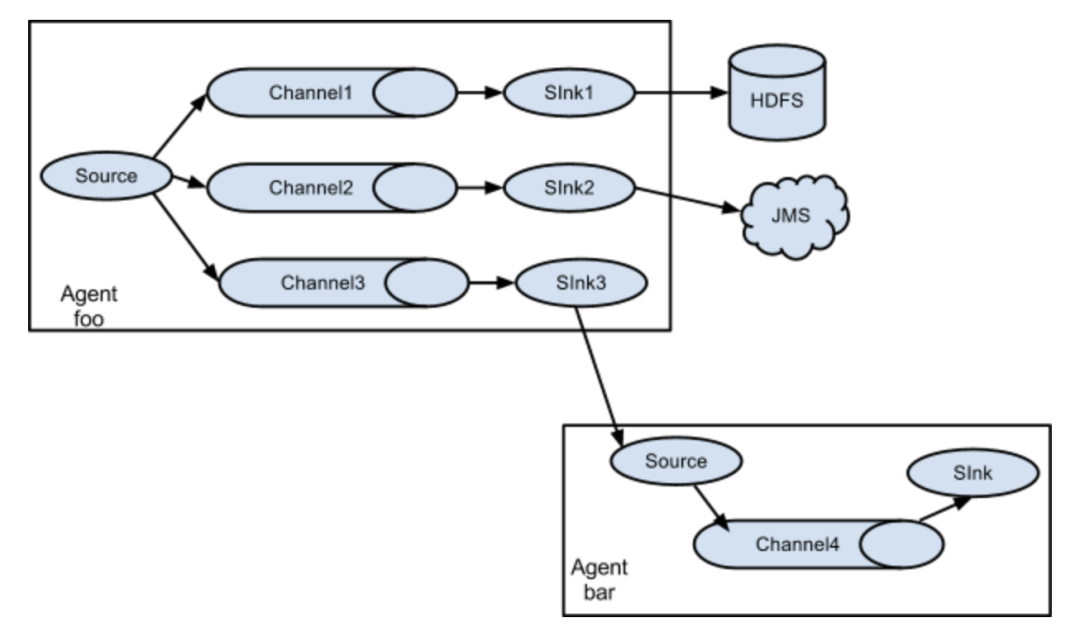
Flume系统以一个或多个Flume-NG Agent的形式部署,一个Agent对应一个JVM进程,并且由三个部分组成:Source、Channel和Sink,示意图如下。
Source
Flume有3种能够监听文件的Source,分别是Exec Source(配合tail -f命令)、Spooling Directory Source和Taildir Source。Taildir Source显然是最好用的,在我们的实践中,需要注意的参数列举如下。
filegroups 如果需要监听的日志文件较多,应该将它们分散在不同的目录下,并配置多个filegroup来并行读取。注意日志文件的正则表达式要写好,防止日志滚动重命名时仍然符合正则表达式造成重复。示例:
a1.sources.r1.type = TAILDIR
a1.sources.r1.filegroups = f1 f2
a1.sources.r1.filegroups.f1 = /data/logs/ng1/access.log
a1.sources.r1.headers.f1.headerKey1 = ng1
a1.sources.r1.filegroups.f2 = /data/logs/ng2/.*log
a1.sources.r1.headers.f2.headerKey1 = ng2
batchSize 该参数控制向Channel发送数据的批次大小,默认值为100。如果日志流量很大,适当增加此值可以增大Source的吞吐量,但是不能超过Channel的capacity和transactionCapacity的限制(后文再说)。示例:
a1.sources.r1.batchSize = 1000
maxBatchCount 该参数控制从同一个文件中连续读取的最大批次数量,默认不限制。如果Flume同时监听多个文件,并且其中某个文件的写入速度远快于其他文件,那么其他文件有可能几乎无法被读取,所以强烈建议设定此参数。示例:
a1.sources.r1.maxBatchCount = 100
writePosInterval 该参数控制向记录读取位置的JSON文件(由positionFile参数指定)写入inode和偏移量的频率,默认为3000ms。当Agent重新启动时,会从JSON文件中获取最近记录的偏移量开始读取。也就是说,适当降低writePosInterval可以减少Agent重启导致的重复读取的数据量。
a1.sources.r1.writePosInterval = 1000
Channel
Flume内置了多种Channel的实现,比较常用的有Memory Channel、File Channel、JDBC Channel、Kafka Channel等。我们的选择主要针对Memory Channel和File Channel两种,对比一下:
Memory Channel将staging事件数据存储在Agent堆内存中,File Channel则将它们存储在指定的文件中;
如果Agent失败,Memory Channel会丢失所有缓存的staging事件,File Channel则可以通过额外记录的checkpoint信息恢复,保证断点续传;
Memory Channel能够容纳的数据量受堆内存的影响,而File Channel不受此限制。
鉴于我们下游业务的主要痛点在吞吐量与实时性,且可以容忍数据少量丢失,日志服务器的磁盘压力也已经比较大了,故Memory Channel更加合适。需要注意的参数如下。
capacity、transactionCapacity 这两个参数分别代表Channel最多能容纳的事件数目,以及每个事务(即Source的一次put或者Sink的一次take)能够包含的最多事件数目。显然,必须满足batchSize <= transactionCapacity <= capacity的关系。适当调大capacity和transactionCapacity可以使得Channel的吞吐量增高,且能够保证不会出现The channel is full or unexpected failure的异常。示例:
a1.channels.c1.type = memory
a1.channels.c1.transactionCapacity = 5000
a1.channels.c1.capacity = 10000byteCapacity
该参数代表Memory Channel中缓存的事件消息的最大总大小,以字节为单位,默认是Flume Agent最大堆内存的80%。此值不建议更改为固定的,而是建议通过改变Agent的JVM参数来影响,后面再提。
byteCapacityBufferPercentage
Memory Channel中缓存的事件消息头占byteCapacity的比例,默认是20%。如果事件的header信息很少,可以适当减小(我们没有更改)。
keep-alive
向Channel中put或take一条事件的超时时间,默认为3秒,对于Memory Channel一般不用更改。如果业务数据是由很多突发流量组成(也就是说Channel经常处于时满时空的状态),那么建议适当调大。示例:
a1.channels.c1.keep-alive = 15
当然File Channel也很常用,其参数就不再赘述,看官可参考官方文档。
Sink
我们实时数仓接入层的起点是Kafka,自然要利用Kafka Sink。需要注意的参数列举如下。
kafka.flumeBatchSize
从Channel取出数据并发送到Kafka的批次大小,与Source的batchSize同理。
kafka.producer.acks
该参数的含义就留给看官去回想(很基础的),一般设为折衷的1即可。设为-1的可靠性最高,但是相应地会影响吞吐量。
kafka.producer.linger.ms
Kafka Producer检查批次是否ready的超时时间,超时即发送(与producer.batch.size共同作用)。一般设为数十到100毫秒,可以在时效性和吞吐量之间取得比较好的平衡。
kafka.producer.compression.type
Producer消息压缩算法,支持gzip/snappy/lz4,如果希望降低消息的体积可以配置。
示例:
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.flumeBatchSize = 1000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.kafka.producer.linger.ms = 50
a1.sinks.k1.kafka.producer.compression.type = snappy
Kafka Sink也支持其他Producer参数,可以按需配置。
Interceptor
拦截器方面就比较简单粗暴,在注重吞吐量的场合一定不要使用或者自定义规则复杂的拦截器(比如自带的Regex Interceptor、Search and Replace Interceptor),最好是不使用任何拦截器,把数据清洗的任务交给下游去处理(Flink它不香嘛
Agent Process
在flume-env.sh中添加JVM参数,避免默认堆内存太小导致OOM。
export JAVA_OPTS="-Xms8192m -Xmx8192m -Xmn3072m
-XX:+UseParNewGC
-XX:+UseConcMarkSweepGC
-XX:+HeapDumpOnOutOfMemoryError"
另外,Taildir Source会积极地使用堆外内存,如果发现Flume消耗的总内存量过大,可以适当限制直接内存的用量,如:-XX:MaxDirectMemorySize=4096m。
Flume原生并没有传统意义上的“高可用”配置(Sink Group Failover不算)。为了防止Agent进程因为各种原因静默地挂掉,需要用一个“保姆脚本”(nanny script)定期检测Agent进程的状态,并及时拉起来。当然也可以在下游采用两级Collector的架构增强鲁棒性,本文不表。
The End
经过上述适当的调优过程,我们的单个Flume-NG Agent能够轻松承受高达5W+ RPS的持续流量高峰,比较令人满意了。


版权声明:
本文为大数据技术与架构整理,原作者独家授权。未经原作者允许转载追究侵权责任。编辑|冷眼丶微信公众号|import_bigdata文章不错?点个【在看】吧! ?