
详细解读PVT-v2 | 教你如何提升金字塔Transformer的性能?(附论文下载)


本文提出PVTv2,PVTv2在分类、检测和分割方面显著改进了PVTv1,表现SOTA!性能优于Twins、DeiT和Swin等网络,代码刚刚开源!
作者单位:南京大学, 香港大学, 南京理工大学, IIAI, 商汤科技
1简介
计算机视觉中的Transformer最近取得了令人鼓舞的进展。在这项工作中,作者通过添加3个改进设计来改进原始金字塔视觉Transformer(PVTv1),其中包括:
具有卷积的局部连续特征; 具有zero paddings的位置编码, 具有平均汇集。
通过这些简单的修改,PVTv2在分类、检测和分割方面显著优于PVTv1。此外,PVTv2在ImageNet-1K预训练下取得了比近期作品(包括 Swin Transformer)更好的性能。
2Transformer Backbones
ViT将每个图像作为固定长度的token(patches)序列,然后将它们提供给多个Transformer层进行分类。这是第一次证明纯Transformer在训练数据充足时(例如,ImageNet-22k JFT-300M)也可以在图像分类方面表现出最先进的性能。
DeiT进一步探讨了一种数据高效的ViT训练策略和一种蒸馏方法。
为了提高图像分类性能,一些最新的方法对ViT进行了定制化的改进。
T2T-ViT将重叠滑动窗口中的token逐步连接到一个token中。
TNT利用内部和外部的Transformer block分别生成pixel emebding和patch embedding。
CPVT用条件位置编码取代了ViT中嵌入的固定尺寸位置,使其更容易处理任意分辨率的图像。
Cross-ViT通过双支路Transformer处理不同尺寸的图像patch。
Local-ViT将深度卷积融合到vision Transformers中,以提高特征的局部连续性。
为了适应密集的预测任务,如目标检测、实例和语义分割,也有一些方法将CNN中的金字塔结构引入到Transformer主干的设计中。
PVT-v1是第一个金字塔结构的Transformer,它提出了一个有4个阶段的分层Transformer,表明纯Transformer主干可以像CNN对等体一样多用途,并在检测和分割任务中表现更好。
在此基础上,对特征的局部连续性进行了改进,消除了固定尺寸的位置嵌入。例如,Swin Transformer用相对位置偏差替换固定大小的位置嵌入,并限制移动窗口内的自注意。
CvT、CoaT和LeViT将类似卷积的操作引入vision Transformers。Twins结合局部注意和全局注意机制获得更强的特征表示。
3金字塔ViT的改进点
与ViT类似,PVT-v1将图像看作是一系列不重叠的patch,在一定程度上失去了图像的局部连续性。此外,PVT-v1中的位置编码是固定大小的,对于处理任意大小的图像是不灵活的。这些问题限制了PVT-v1在视觉任务中的表现。
为了解决这些问题,本文提出了PVT-v2,它通过以下设计改进了PVT-v1的性能:
3.1 Overlapping Patch Embedding
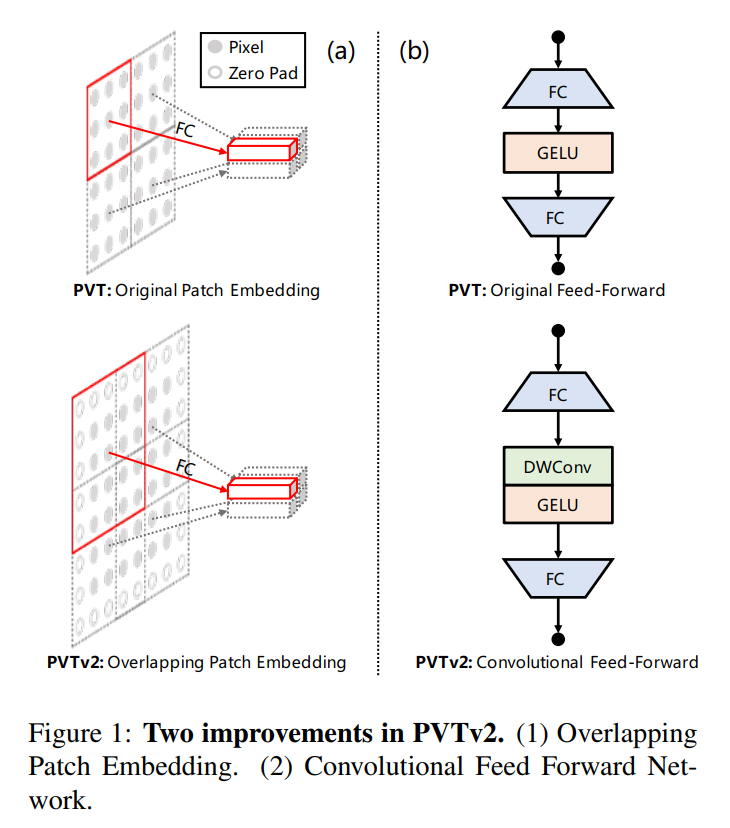
作者利用重叠的patch嵌入来标记图像。如图1(a)所示,对patch窗口进行放大,使相邻窗口的面积重叠一半,并在feature map上填充0以保持分辨率。在这项工作中,作者使用0 padding卷积来实现重叠的patch嵌入。
具体来说,给定一个大小为h×w×c的输入,将其输入到一个步长为S、卷积核大小为2S−1、padding大小为S−1、卷积核数目为的卷积中。输出大小为。
3.2 卷积的前向传播
这里删除固定大小位置编码,并引入0 padding位置编码进pvt如图1所示(b),在前馈网络中的FC层与GELU之间添加一个3×3的depth-wise卷积。
3.3 Linear Spatial Reduction Attention
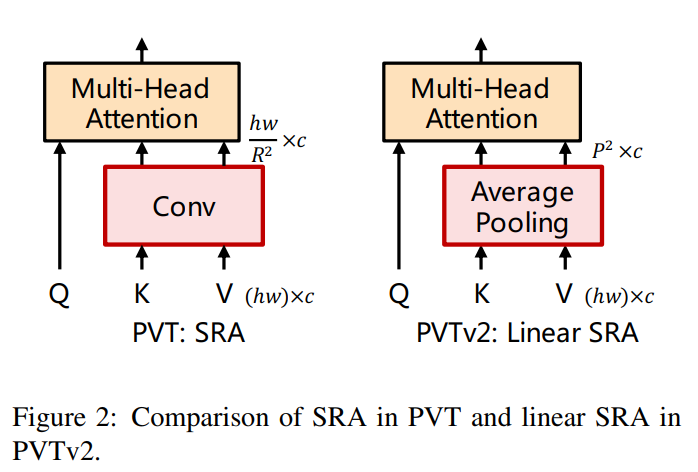
为了进一步降低PVT的计算成本,作者提出Linear Spatial Reduction Attention(SRA),如图所示。与SRA不同,线性SRA具有像卷积层一样的线性计算和存储成本。具体来说,给定输入规模为h×w×c, SRA的复杂度和线性SRA是:
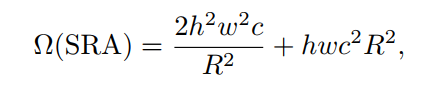
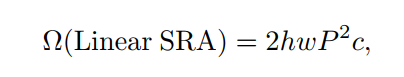
式中R为SRA的空间压缩比。P为线性SRA的pool size,默认为7。
结合这3种改进,PVTv2可以:
获得更多的图像和特征图的局部连续性; 变分辨率输入更加灵活; 具有和CNN一样的线性复杂度。
4PVTv2系列详细介绍
作者通过改变超参数将PVTv2从B0扩展到B5。具体如下:
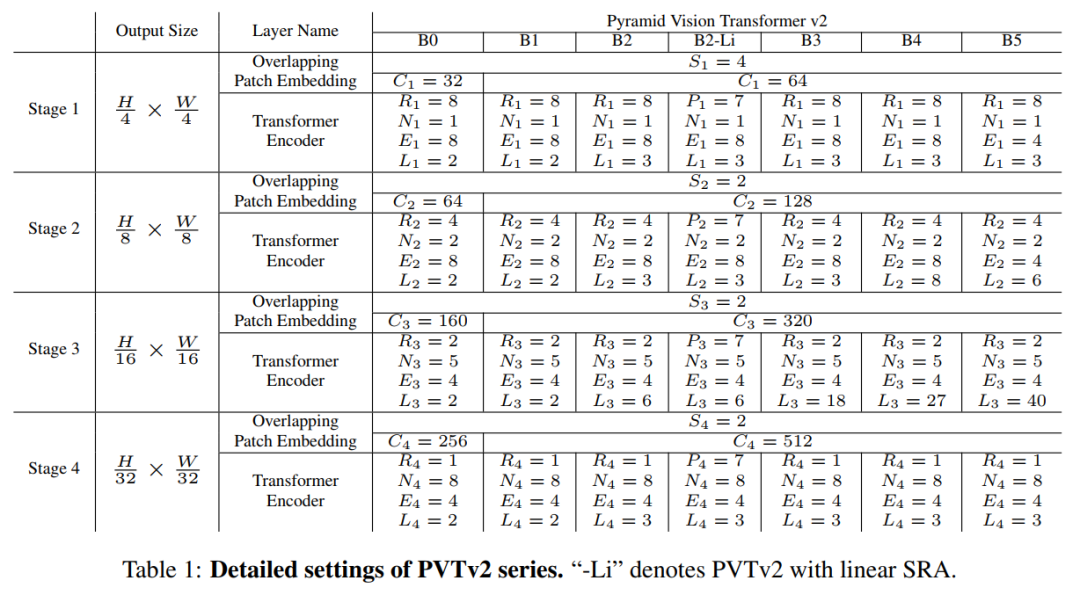
:第阶段overlapping patch embedding的stride; :第阶段输出的通道数; :第阶段中编码器层数; :第阶段SRA的reduction ratio; :第阶段线性SRA的adaptive average pooling size; :第阶段有效Self-Attention的head number; :第阶段前馈层的expansion ratio;
表1显示了PVT-v2系列的详细信息。设计遵循ResNet的原则。
随着层数的增加,通道维数增大,空间分辨率减小。 阶段3为大部分计算开销。
5实验
5.1 Image Classification
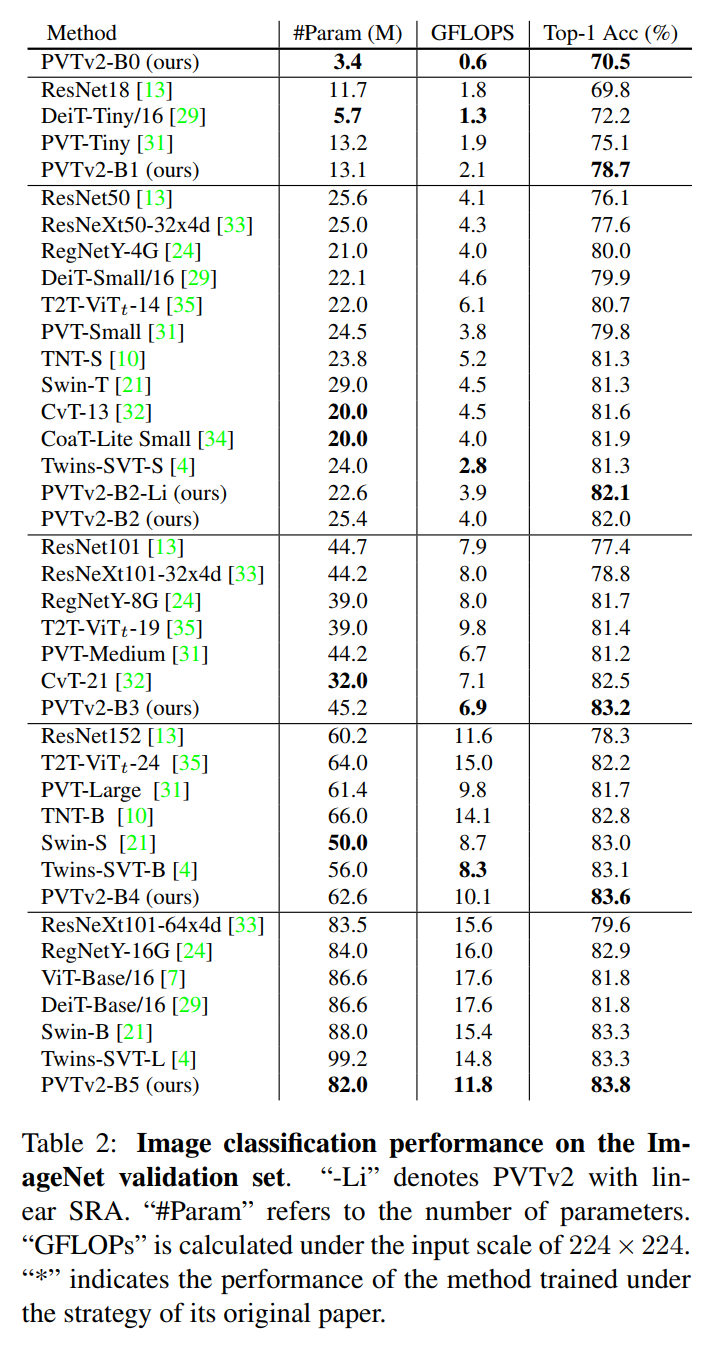
在表中可以看到PVT-v2是ImageNet-1K分类中最先进的方法。与PVT相比,PVT-v2具有相似的FLOPs和参数,但图像分类精度有了很大的提高。例如,PVTv2-B1比PVTv1-Tiny高3.6%,并且PVTv2-B4比PVT-Large高1.9%。
与最近的同类模型相比,PVT-v2系列在精度和模型尺寸方面也有很大的优势。例如,PVTv2-B5的ImageNet top-1准确率达到83.8%,比Swin Transformer和Twins高0.5%,而参数和FLOPs更少。
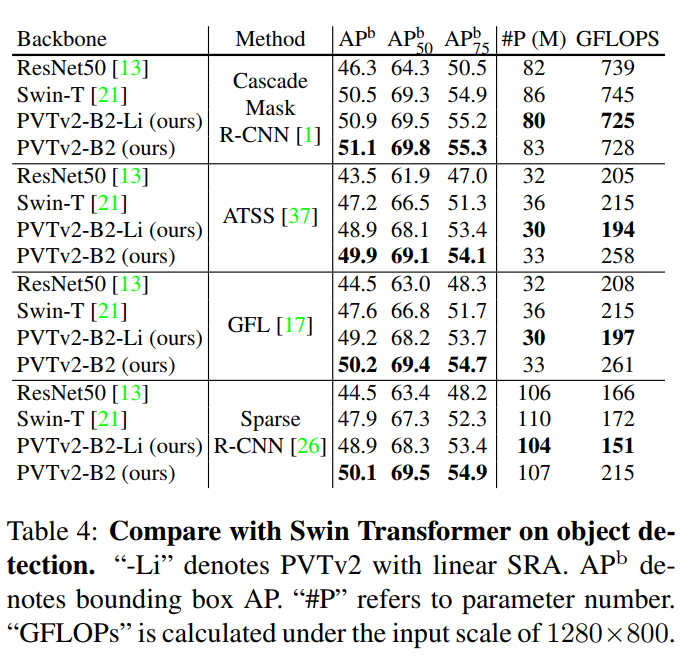
5.2 Object Detection
6参考
[1].PVTv2:Improved Baselines with Pyramid Vision Transformer
7推荐阅读

其实书童是一个集算法、实践、论文以及Transformer于一身的公号(往期索引大全)

详细解读 | CVPR 2021轻量化目标检测模型MobileDets(附论文下载)
即插即用模块 | CompConv卷积让模型不丢精度还可以提速(附论文下载)

详细解读Google新作 | 教你How to train自己的Transfomer模型?
本文论文原文获取方式,扫描下方二维码
回复【PVTv2】即可获取论文
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
