
手把手教你爬取任意日期全部股票分时数据~
回复“书籍”即可获赠Python从入门到进阶共10本电子书
大家好,我是志斌~
在之前志斌写过一篇东方财富网的股票数据爬取文章,详看,受到很多读者的喜欢,有的读者问志斌能不能在写一个获取股票分时数据的文章,今天志斌给安排上!
01
数据采集

首先进入某只股票的详情页,然后在右侧找到分时成交并点击查看更多分时成交,然后进入分时数据的详情页面。
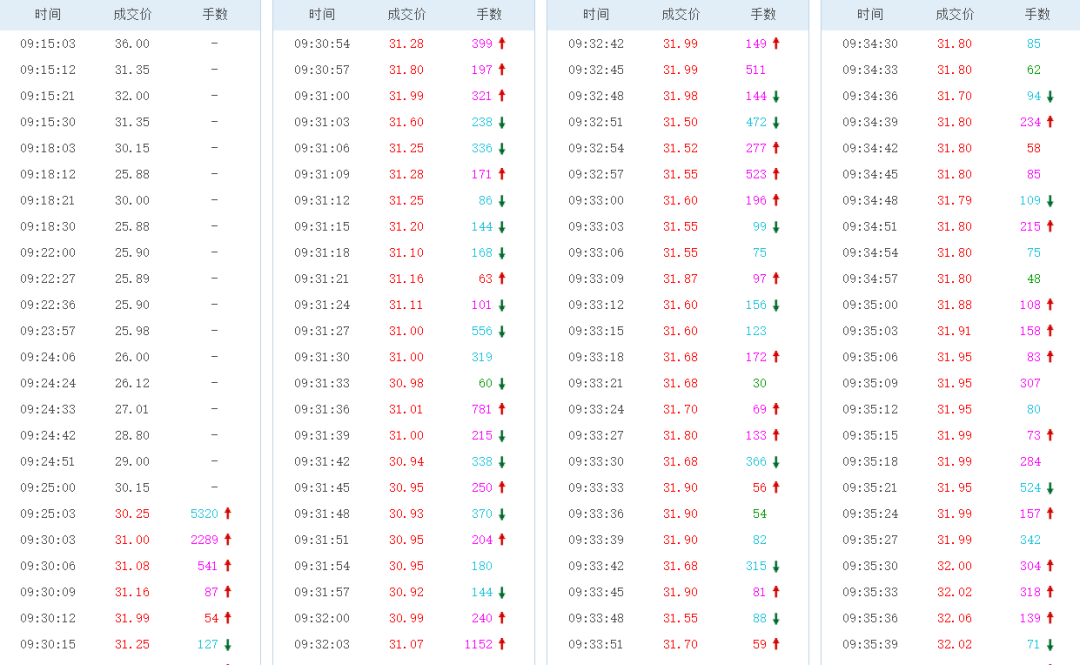
然后我们按F12打开开发者模式,对分时数据的详情页面进行观察后,发现数据存储在一个get开头的页面中,并以JQuery的方式存储。

我们已经发现单页数据存储的方式了,现在我们来看一下各页URL之间的联系,如图:

从图中,我们可以发现,pageindex的值就是页数-1,所以,我们在爬取的时候只需要让pageindex的值进行循环即可。
经过上面的分析,我们已经找全了爬虫的几个关键参数,现在可以开始构建程序,开始爬取了,核心代码如下:
import requests
import csv
with open('688103.csv','a',newline='') as f:
writer = csv.writer(f)
writer.writerow(['时间','成交价','手数'])
for page in range(27):
params = (
('pagesize', '144'),
('ut', '7eea3edcaed734bea9cbfc24409ed989'),
('dpt', 'wzfscj'),
('cb', 'jQuery1124029337350072397084_1631343037828'),
('pageindex', str(page)),
('id', '6009051'),
('sort', '1'),
('ft', '1'),
('code', '688103'),
('market', '1'),
('_', '1631343037827'),
)
response = requests.get('http://push2ex.eastmoney.com/getStockFenShi', headers=headers, params=params, cookies=cookies, verify=False)
for i in eval(response.text[43:-2])['data']['data']:
with open('688103.csv','a',newline='') as f:
writer = csv.writer(f)
if len(str(i['t']))<6:
shi = str(i['t'])[0]
fen = str(i['t'])[1:3]
miao = str(i['t'])[3:]
else:
shi = str(i['t'])[0:2]
fen = str(i['t'])[2:4]
miao = str(i['t'])[4:]
if i['bs'] == 4:
a = '--'
elif i['bs'] == 2:
a = '买入'
elif i['bs'] == 1:
a = '卖出'
02
批量爬取
上面的程序是对单个股票数据的分时数据进行爬取的,我们如果想对其他股票进行爬取,还要在一个一个进行构造那也太麻烦了。
所以我们需要对程序进行完善,让它能够爬取全部的股票分时数据。
我们通过对不同股票的页面数据进行观察发现每个股票的code是它们自己的股票代码,并且id是code+‘2’.
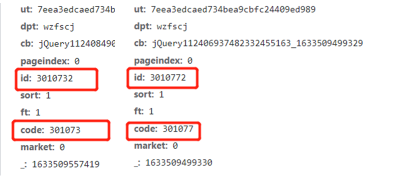
好了,经过上面的分析,我们也只知道不同股票之间的联系了,那我们接下来就可以开始完善程序了,核心代码如下:
gupiao_code = ['301073']
for code in gupiao_code:
with open(f'{code}.csv', 'a', newline='') as f:
writer = csv.writer(f)
writer.writerow(['时间', '成交价', '手数', '买入/卖出'])
try:
for page in range(40):
params = (
('pagesize', '144'),
('ut', '7eea3edcaed734bea9cbfc24409ed989'),
('dpt', 'wzfscj'),
('cb', 'jQuery112408490604705504154_1633509557420'),
('pageindex', str(page)),
('id', '3010732'),
('sort', '1'),
('ft', '1'),
('code', code),
('market', '0'),
('_', '1633509557478'),
)
03
任意时间
有的读者又说了,能不能把之前的分时数据也给爬取下来呢,那必须能啊!
志斌对所有的参数进行观察后发现,在cookie里面有关于日期的参数,如下图:

这就是说当我们改动cookie里面的时间参数就可以爬取任意时间的股票分时数据了,核心代码如下:
riqi = input('输入格式如下:xxxx-')
cookies = {
'st_sp': f'{riqi}%2014%3A57%3A10',
}
因为涉及到cookie,所以就只展示关键部分的数据写法,其他的大家详见代码。
04
小结
1. 本文详细的介绍了如何从东方财富网上批量获取股票分时数据,请读者仔细阅读,并加以操作。
2. 东方财富网没有反爬,但是本着友好的原则,用户在爬取时最好使用间隔爬取。
3. 本文仅供参考学习,不做商用。
小伙伴们,快快用实践一下吧!如果在学习过程中,有遇到任何问题,欢迎加我好友,我拉你进Python学习交流群共同探讨学习。
------------------- End -------------------
往期精彩文章推荐:

欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
想加入Python学习群请在后台回复【入群】
万水千山总是情,点个【在看】行不行
/今日留言主题/
随便说一两句吧~