
如何有效增强数据集,yolov5 mAP从0.46提升到了0.79?
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
作者:Tushar Kolhe
编译:ronghuaiyang 来源:AI公园
以监控摄像头数据集的人体检测模型为例,说明了如何通过对数据的理解来逐步提升模型的效果,不对模型做任何改动,将mAP从0.46提升到了0.79。

介绍
目标检测能够完成许多视觉任务,如实例分割、姿态估计、跟踪和动作识别。这些计算机视觉任务在监控、自动驾驶和视觉问答等领域都有广泛的应用。随着这种广泛的现实应用,目标检测自然成为一个活跃的研究领域。
我们在Fynd的研究团队正在训练一个行人检测模型来提升我们的目标跟踪模型。在本文中,我们将解释我们如何选择一个模型架构,创建一个数据集,并为我们的特定的用例来训练它。
什么是物体检测?
目标检测是一种计算机视觉技术,它允许我们识别和定位图像或视频中的目标。目标检测可以分为两部分:目标定位和目标分类。定位可以理解为预测图像中物体的准确位置(边界框),分类是定义它属于哪个类(人/车/狗等)。
物体检测的方法
有各种各样的方法来解决目标检测任务。我们可以将模型分为三类。
两阶段检测器:模型有两种网络,一个是做区域建议,一个做检测。一些典型的例子是RCNN family。 带anchor的一阶段探测器:这类架构没有单独的区域建议网络,但依赖于预定义的anchor框。我们可以通过YOLO家族来了解这些网络。 单阶段无anchor检测器:这是一个相当新的物体检测方法,这样的网络是端到端可微分的,不依赖于感兴趣的区域(ROI)。而且一次性来预测物体。这是一个非常有趣的方法,它塑造了的新研究的思路。要了解更多可以看看CornerNet或CenterNet。
什么是COCO数据集?
为了比较模型,业界广泛使用了一个称为COCO的公共数据集(Common Objects in Context)。这是一个具有挑战性的数据集,有80个类和超过150万个物体实例,因此这个数据集是初始模型选择的一个非常好的基准。每年都有各种新的和创新的方法出现,并在该任务上竞提升性能。
如何查看性能?
业内提出了评价目标检测的各种指标。其中一些挑战包括:
The PASCAL VOC Challenge (Everingham et al. 2010) The COCO Object Detection Challenge (Lin et al. 2014) The Open Images Challenge (Kuznetsova 2018).
要理解这些度量标准,你需要很好地理解一些基本概念,如精度、召回率和IOU。下面是这个公式的一个简短定义。
Average Precision
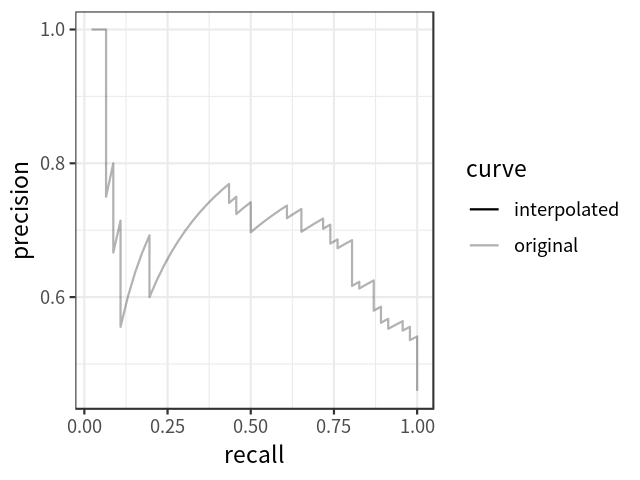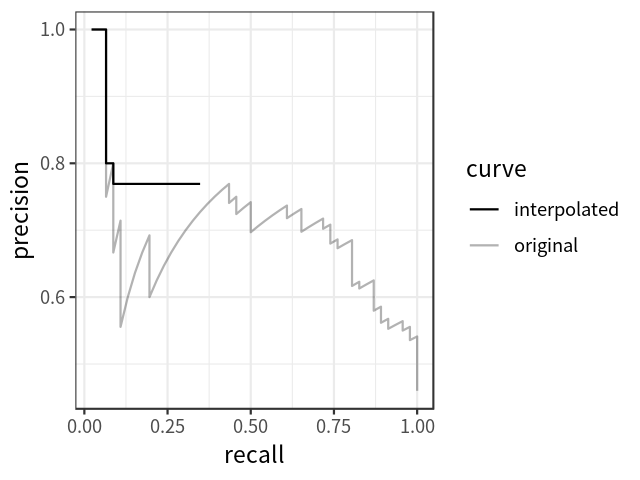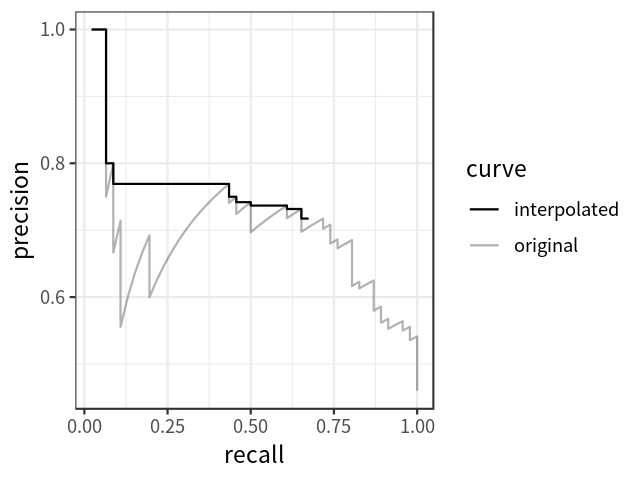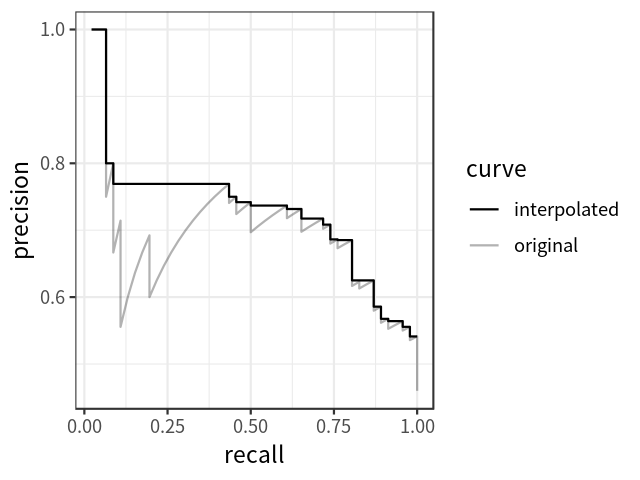
AP可以定义为插值后的precision-recall曲线下的面积,计算公式如下:
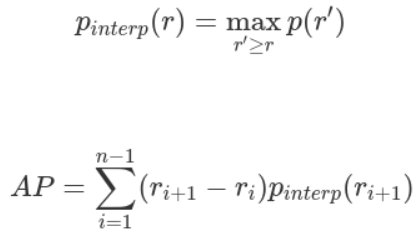
Mean average precision
AP的计算只涉及一个类。然而,在目标检测中,通常有K>1个类。mAP定义为AP在所有K类上的平均值:
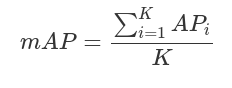
实际问题描述
我们的任务是在零售商店的闭路电视视频中检测人的边界框。该模型非常关键,因为跟踪模型依赖于它,检测产生的所有误差都会传播到跟踪模型中。以下是在此类视频中检测的一些主要挑战。
挑战
视角: 闭路电视是顶部安装的,和正常照片的视角不一样。 拥挤: 商店有时会有非常拥挤的场景。 背景很乱: 零售商店有很多的干扰或杂物(对我们的模型来说),比如衣服、货架、人体模型等,这可能会导致误报。 灯光条件:店内的灯光条件与户外摄影不同。 图像质量:来自闭路电视的视频帧有时会很差,还可能包含运动模糊。
构建测试集
我们创建了一个验证集,其中包含来自零售店CCTV视频的视频帧。我们使用person边界框对每帧进行标注,并使用mAP@ 0.50 IOU阈值在整个训练迭代过程中测试模型。
第1个人体检测模型
我们的第一个模型是COCO的预训练的模型,其中“person”是其中一个类。我们在每种方法中筛选出了2个模型,并根据COCO mAP val和推理时间对其进行了评估。
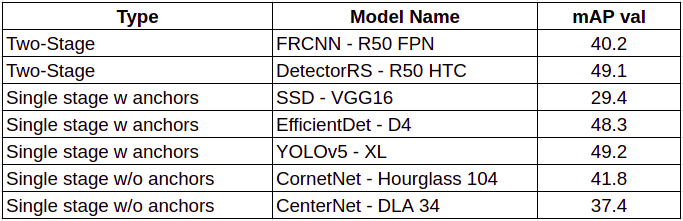
YOLOv5的单阶段特性(快速推理)和在COCO mAP val上的良好性能被我们列入了候选名单。它也有更快的版本,如YOLOv5m和YOLOv5s。
YOLOv5
YOLO家族属于单阶段物体探测器,不像RCNN家族,它没有一个单独的区域建议网络(RPN),并依赖于不同尺度的anchor。整体结构架构可分为三部分:backbone, neck和head。使用CSP (Cross Stage Partial Networks)作为backbone从输入图像中提取特征。PANet用作收集特征金字塔的neck,head是使用特征上的anchor检测物体的最终检测层。
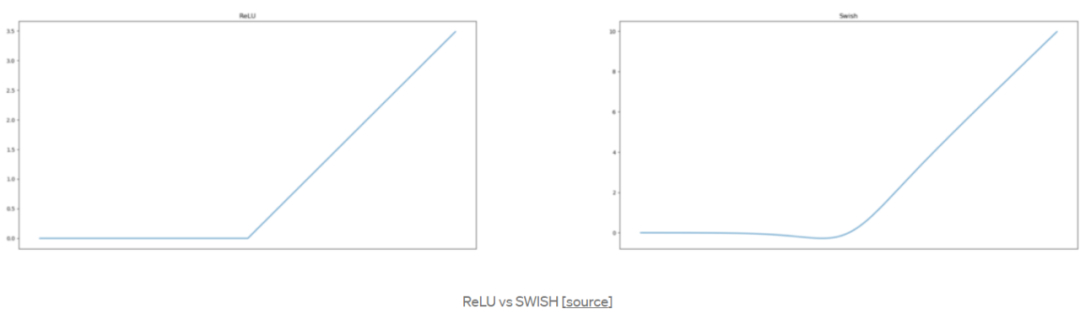
YOLO架构使用的激活功能是谷歌Brains在2017年提出的Hard Swish的变体,它看起来和ReLU非常相似,但不像ReLU,它在x=0附近是平滑的。
损失函数用的是二元交叉熵。
性能
0.48 mAP @ 0.50 IOU (在我们自己的测试集上)
分析
这个开箱即用的模型不是很好,因为模型是在包含一些不必要的类的COCO数据集上训练的。包含人的实例的图像数量较少,人群密度也较低。此外,包含人的实例的图像分布与CCTV视频帧中的非常不同。
结论
我们需要更多的数据来训练模型,使其包含更多拥挤的场景,并使摄像机的视角在45⁰- 60⁰之间(和CCTV类似)。
收集公共数据
我们的下一步是收集包含人边界框的公开数据集。有大量的人检测的数据集,但我们需要一些关于数据集的额外信息,如视角,图像质量,人的密度和背景,以捕获数据集分布信息。
我们可以看到满足我们确切需求的数据集并不是很多,但是我们仍然可以使用这些数据集,因为具备人的边界框的基本要求已经得到了满足。下载所有数据集后,我们将其转换为常见的COCO格式用于检测。
第2个人体检测模型
我们用所有收集到的公共数据集训练模型。
训练迭代 2:
Backbone: YOLOv5x 模型初始化:COCO预训练权重 Epochs: 10 epochs
性能
0.65 mAP @ 0.50 IOU
分析
随着数据集的增加,模型性能显著提高。一些数据集有高拥挤的场景,满足我们的一个要求,和一些包含顶部的相机视角,满足另一个要求。
总结
虽然模型的性能有所提高,但有些数据集是视频序列,而且在某些情况下背景仍然是静态的,可能会导致过拟合。很少量的数据集中有非常小的人类,这使得任务很难学习。
清洗数据
下一步是清理数据。我们从训练和验证集中过滤出造成损失最多的图像,或者我们可以说是那些mAP非常小的图像。我们选择了0.3 mAP阈值并对图像进行可视化。我们从数据集中过滤了三种类型的用例。
标签错误的边框 图像包含非常小的边框或太多太拥挤 重复的或近似重复的帧
为了去除重复的帧,我们只从视频序列中选择稀疏的帧。
第3个人体检测模型
有了清理和整理之后的数据集,我们就可以开始第三次迭代了
训练迭代 3:
Backbone: YOLOv5x 模型初始化:COCO预训练权重 Epochs: ~100 epochs
性能
0.69 mAP @ 0.50 IOU
分析
将未清理的数据从训练和验证集中删除后,模型性能略有改善。
总结
数据集被清理,可以看到性能的改进。我们可以得出结论,进一步改进数据集可以提高模型性能。为了提高性能,我们需要确保数据集包含与测试用例相似的图像。我们处理了人群情况和一些视角情况,但大多数数据都是向前的视角。
数据增强
我们已经列出了在现实案例中检测时将面临的一些挑战,但是收集的数据集分布不同。因此,我们使用了一些数据增强技术,使训练分布更接近生产用例或测试分布。
下面是我们希望对数据集进行的扩充。
视角- 透视变换

光照条件- 亮度
- 对比度

图像质量- 噪声
- 图像压缩
- 运动模糊

通过将所有这些增强加在一起,我们可以将公共数据分布转换为更接近生产分布的数据。我们可以看到从下面的图像和比较原始和转换后的图像。

所有这些增强都是通过使用“albumentation”来实现的,“albumentation”是一个很容易与PyTorch数据转换集成的python库。它还有一个demo应用,我们使用该应用为不同的方法设置增强参数。在库中还有许多可用于其他用例的扩展。
第4个人体检测模型
现在有了转换后的数据集,我们就可以进行第四个迭代了
训练迭代 4:
Backbone: YOLOv5x 模型初始化:来自第3个迭代的模型权重 Epochs: ~100 epochs
性能
0.77 mAP @ 0.50 IOU
分析

性能提高了近8%,该模型能够预测大多数情况,并在摄像机视角上进行了泛化。由于背景杂波和遮挡的影响,视频序列中仍然存在误报和漏报的现象。
结论
我们尝试收集数据集并覆盖任务中几乎所有的挑战,但仍有一个挑战阻碍了我们的模型性能。我们需要收集包含这些用例的数据。
创建自定义的标注
通过数据增强,我们创建了一些真实的案例,但我们的数据在图像背景方面仍然缺乏多样性。对于一个零售商店来说,框架背景充满了杂乱、人体模型或衣服架子,这会导致误报,大遮挡会导致漏报。为了增加多样性,我们放弃了谷歌,我们从商店中收集闭路电视录像,并手工标注图像。首先,我们将迭代4中的所有图像通过模型进行预测,并创建自动标签,然后使用开源标注工具CVAT (Computer Vision and annotation tool)进一步的修正标注。
最终的人体检测模型
我们将自定义的存储图像添加到之前的数据集中,并为最后的迭代训练我们的模型。我们最终的数据集分布是这样的。
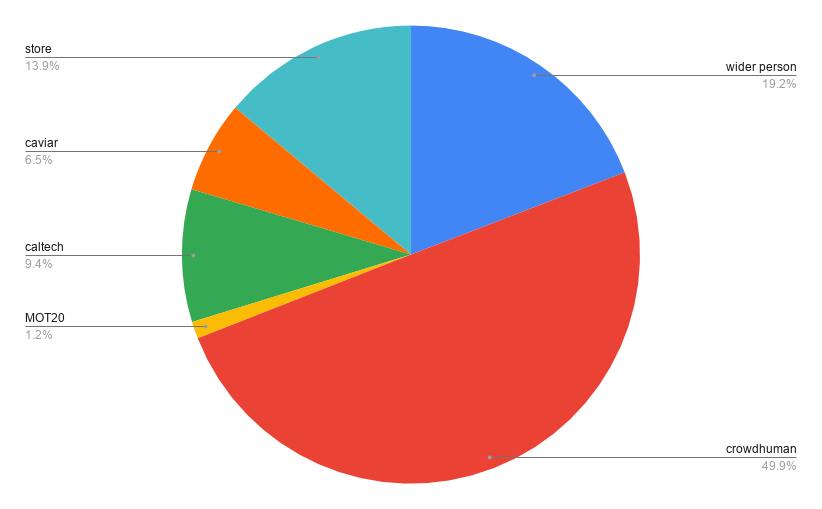
训练迭代 5:
Backbone: YOLOv5x 模型初始化: 从第4个迭代的权重开始 Epochs: ~100 epochs
性能
0.79 mAP @ 0.50 IOU
分析

模型的性能显示出~ 0.2%的正增长。从TIDE 分析中可以看出,假阳性对错误的贡献减小了。
结论
额外的数据有助于使模型对背景干扰更健壮,但是收集的数据量仍然比总体数据集的大小少得多,并且模型仍然有一些false negatives。当对随机图像进行测试时,该模型能够很好地泛化。
过程概述
我们从模型选择开始,以COCO mAP作为基准,我们选出了一些模型。此外,我们考虑了推理时间和模型架构,并选择YOLO v5。我们收集并清理了各种公开可用的数据集,并使用各种数据增强技术将其转换为我们的用例。最后,我们从头收集图像,并在手工标注之后将它们添加到数据集中。我们最终的模型是在这个经过整理的数据集上训练的,能够从 0.46 mAP @ IOU0.5改进到0.79 mAP @ IOU 0.5。
总结
通过根据用例对数据集进行处理,我们将物体检测模型改进了约20%。该模型在mAP和延迟方面仍有改进空间。选择的超参数是YOLO v5默认给出的,我们可以使用超参数搜索库,如optuna对它们进行优化。当训练分布和测试分布之间存在差异时,域适应是另一种可以使用的技术。此外,这样的情况可能需要使用额外数据集进行连续的训练循环,以确保模型的持续改进。

下载1:速查表
在「AI算法与图像处理」公众号后台回复:速查表,即可下载21张 AI相关的查找表,包括 python基础,线性代数,scipy科学计算,numpy,kears,tensorflow等等
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
觉得有趣就点亮在看吧
