
NLP领域中面向文本的情感分析研究
文本情感分析是 NLP 领域中最活跃的研究方向之一,是指根据文本中包含的观点、态度和情感倾向将文本划分为正向、负向、中性不同的情感类别。
情感分析可以将用户的情感信号转化为有价值的知识信息,用于做用户画像,市场营销,个性化推荐,商业决策,舆情监控,或是做电影票房预测,股票及加密数字货币投资者情绪分析等等。本文从演进的角度来讲讲如何从文本中挖掘情感信息。
本文主要内容包括:
基于情感词典和规则的情感分析
基于机器学习的情感分析
基于深度神经网络的情感分析
基于语言模型的情感分析
总结与展望
提示:全文内容较长,包含大量理论和代码实践,建议点赞收藏后慢慢看~
01
基于情感词典和规则的情感分析
这是一种基于预先定义的规则,利用情感词对文本进行情感分析的方法。
这家餐厅的服务太差了!如果我们有一个情感词典包含了大量的情感词及其对应的情感极性,定义 “好”、“赞” 等词为积极情感词,其情感极性为正数;而 “差”、“坏” 等词则为消极情感词,其情感极性为负数。
在这个例子中, “太差了” 包含"差"这个消极情感词,并且 “太” 字表示程度很大。对句子中所有词的情感极性进行加权汇总,得到整个句子的情感极性为负数,表示消极情感。
我们针对文本中所有情感词语计算文本的情感得分,这个得分可以表示情感的极性。如果文本中的积极情感得分高于阈值,那么我们可以将其标注为积极评论,反之则为消极评论。
▌代码实践
我们可以借助 VADER (Valence Aware Dictionary and Entity Reasoner)实现基于情感词典的情感分析任务,它使用一个预先定义的词汇表,为每个词都分配了固定的情感权值,这些权值是根据人类对一系列单词的情感评分而生成的。
# 安装 nltk 包,并下载情感词典
pip install nltk==3.7
import nltk
nltk.download('vader_lexicon')
# 情感分析器
from nltk.sentiment.vader import SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
# 进行情感打分
texts = ["This is a great day! I'm so happy!",
"I'm feeling sad and upset today.",
"I don't know how to feel about this situation."]
for text in texts:
scores = sid.polarity_scores(text)
print(scores) (三句话的打分结果)
(三句话的打分结果)
执行结果中:neg 表示文本中否定情绪词的占比(0~1),neu 表示文本中中性情绪词的占比(0~1),pos 表示文本中肯定情绪词的占比(0~1),compound 表示整体情感倾向,也就是最终结论值(-1~1),负值代表消极倾向,正值代表积极倾向,0 为中性。
那么这个结果怎么得来的呢 ? 打开下载的情感词典 vader_lexicon.txt 可以看到它将绝大多数英文单词都进行了情感打分,love,loved,lovely,lovable… 为正向情感词,权值为正数;lost,louse,lousy,low… 为负向情感词,权值为负数。
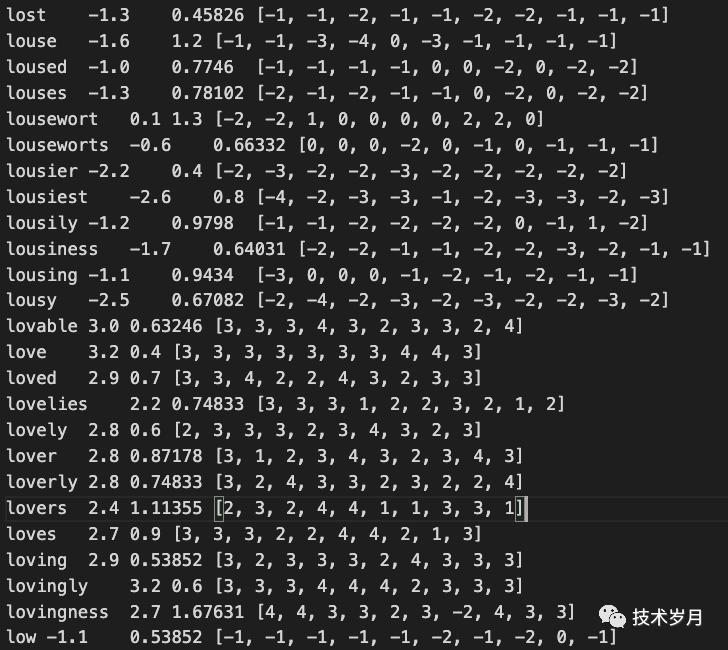 (vader_lexicon.txt 词典部分截图)
(vader_lexicon.txt 词典部分截图)基于规则的情感分析方法实现简单,具有可解释性,但情感词典收录的情感词汇数量有限,且无法对具有多重含义的情感词进行准确分类,只能对单个词汇进行情感分类,而无法考虑词汇之间的语义关系,例如同义词、反义词等。
02
基于机器学习的情感分析
使用机器学习的第一步就是进行文本的特征工程,由于文本是字符串(字符序列)结构,在计算机中不可计算,因此需将其转为可计算向量。将文本中的词语转化成向量的过程叫词向量法,称之为空间向量模型。
常用的空间向量模型包括:One-Hot 编码,词袋法,TF-IDF,Word2Vec,GloVe,FastText 等。
▌2.1 One-Hot 编码
One-Hot 编码是一种将不同的词汇表示成数字形式的方法。首先将文本中的不同词汇都分配一个唯一的整数作为它的编号,然后将该词汇表示成一个维度等于词汇总数的向量,其中该词汇的编号所在位置为 1,其余位置都为 0。
比如这句话:
I like to eat apple.我们先建立一个词汇表,将所有不同的词在词汇表中编号:
| 词汇 | 编号 |
|---|---|
| I | 0 |
| like | 1 |
| to | 2 |
| eat | 3 |
| apple | 4 |
词汇表目前只有 5 个词,我们可以使用一个五维向量表示(向量的维度等于词汇表的大小),对应每个单词向量表示如下:
I - [1, 0, 0, 0, 0]like - [0, 1, 0, 0, 0]to - [0, 0, 1, 0, 0]eat - [0, 0, 0, 1, 0]apple - [0, 0, 0, 0, 1]
看到这里,One-Hot 编码的缺点显而易见,词汇表有多长则向量维度就有多少,那么要构建一个常用英文单词词汇表就有上万个,容易造成维度过高,计算存储量过大,文本稀疏等问题。
▌2.2 词袋法 Bag of Words
词袋模型是基于词频统计的一种方法,即统计每个单词在句子中的出现次数。
I like to eat apple.这句话可以构建词频统计向量为 [1, 1, 1, 1, 1]
(每个数字表示词汇表中该位置单词出现的次数)
对于下面句子:
I like to eat apple, he like to eat orange.词汇表扩展为:[“I”, “like”, “to”, “eat”, “apple”, “he”, “orange”] ,对应的词频统计向量为 [1, 2, 2, 2, 1, 1, 1]。
词袋法相比于 One-Hot 编码维度大大减少,由于 One-Hot 只统计单词是否出现,而词袋法统计了出现次数,有助于挖掘文档中的关键词(高频词),但其并未考虑词语的重要性,有时并非出现次数越多单词就越重要,因此有了 TF-IDF。
▌2.3 TF-IDF
TF-IDF 在词频统计的基础上加入了一层“权重”,即词频-逆文档频率。
假设如下两句话构成一个文档(实际会有更大的语料库作文档)
I like to eat apple.He like to eat orange.
构建词汇表:[“I”, “like”, “to”, “eat”, “apple”, “he”, “orange”]
TF-IDF 计算公式:
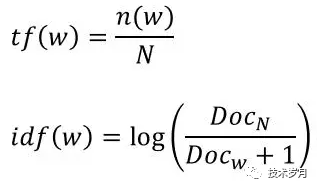
(公式图片来自网络)
计算TF(词频):
“I like to eat apple”: [1, 1, 1, 1, 1, 0, 0]
“he like to eat orange”:[0, 1, 1, 1, 0, 1, 1]
(1 表示词汇表中该位置单词在本句中出现,0 表示没有出现)
计算IDF(逆文档频率):
“I”: log(2 / 1) = 0.301
“like”: log(2 / 2) = 0
“to”: log(2 / 2) = 0
“eat”: log(2 / 2) = 0
“apple”: log(2 / 1) = 0.301
“he”: log(2 / 1) = 0.301
“orange”: log(2 / 1) = 0.301
提示:idf 计算公式中分母的 +1 是为了防止分母为 0,只有在分母非常大的时候才会去 +1,这样对结果的影响可忽略
将 TF 值乘以 IDF 值得出 TF-IDF 向量如下:
“I like to eat apple”:[0.301, 0, 0, 0, 0.301, 0, 0]
“he like to eat orange”:[0, 0, 0, 0, 0, 0.301, 0.301]
TF-IDF 考虑了词语的权重,但未考虑文本的词语顺序和上下文关系等,这样对于 "我爱她" 和 "她爱我" 这两种文本会混为同一个意思。
▌2.4 机器学习做情感分析
通过将文本编码为向量后,就可以使用机器学习的方法进行模型训练,比如基于朴素贝叶斯、支持向量机、随机森林、XGBoost 等进行有监督学习分类任务。
第一个案例,我们基于预训练的 TextBlob 来看机器学习做情感分析的效果。TextBlob 默认基于朴素贝叶斯分类器(Naive Bayes Classifier),使用了由电影评论组成的大型语料库"NLTK(Natural Language Toolkit) movie_reviews",基于这个训练好的分类器,TextBlob 可以直接对文本进行情感分析。
提示:虽然TextBlob的情感分析模型是基于电影评论训练的,但它通常对许多其他主题和领域的文本也能提供合理的分析结果。
#安装包
pip install textblob==0.17.1
from textblob import TextBlob
# 需要进行情感分析的文本
text = "I love programming in Python! Its simplicity is so empowering."
# 创建TextBlob对象
blob = TextBlob(text)
# 计算文本的情感分析结果
sentiment = blob.sentiment
# 输出情感分析结果
print(f"Polarity: {sentiment.polarity}, Subjectivity: {sentiment.subjectivity}")

其返回值包括极性Polarity:(-1~1)-1 表示非常负面,+1 表示非常正面,0 表示中立;主观性Subjectivity(0~1)0 表示纯客观描述,1 表示非常主观。
第二个案例,我们将从特征工程开始构建一个情感分类模型,机器学习建模一般分为如下几个步骤。
(1)数据收集与预处理:
收集文本数据集,对数据进行清洗、去除噪声和不相关的信息,如去除停用词、标点符号、单词纠错、词形还原等。同时需要一部分数据带有情感标签用于监督学习,如果没有情感标签咋办?那就人工打标,专门有从事人工打标的团队。
(2)特征提取:
根据业务需求和任务类型,选择适合的特征提取方法,特征提取方法包括 One-Hot编码、词袋模型、TF-IDF 以及后面要介绍的 Word2Vec 词嵌入等不同的方法。
(3)模型训练:
根据任务类型,选择适合的分类器进行训练,比如朴素贝叶斯、支持向量机、决策树和神经网络等,并且可以使用交叉验证和网格搜索等技术来优化模型。
(4)模型评估:
使用测试集来评估模型的性能,通常采用准确率、F1分数、召回率和精确率等指标来评价模型的性能。
这里选用 Kaggle 上 Amazon Fine Food Reviews 亚马逊美食评论作为训练样本,Text 作为文本挖掘对象,情感标签可以根据 Score 进行衍生(大于 3 分为正向情感,小于 3分为负向情感,这里做二分类不设置中性情感)。
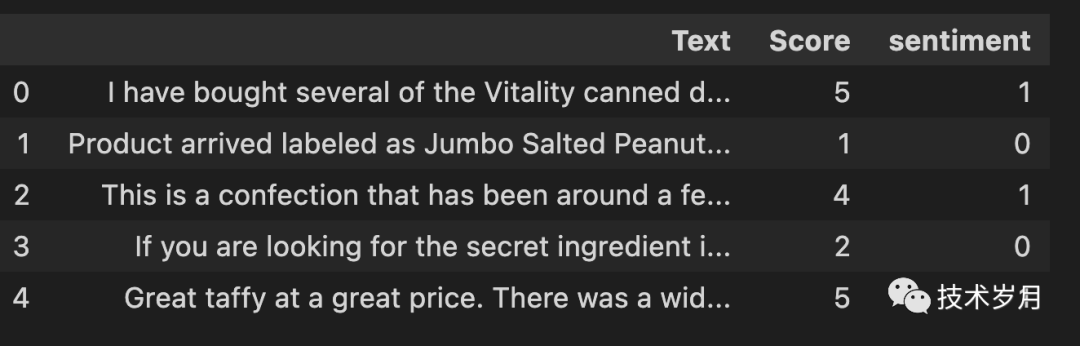
(样本样例)
# 使用 conda 默认已安装常用的机器学习包
# 数据来自 Kaggle:Amazon Fine Food Reviews
# https://www.kaggle.com/datasets/snap/amazon-fine-food-reviews?resource=download
# 加载数据并进行分析预处理
import pandas as pd
data = pd.read_csv("Reviews.csv")
# 使用 nltk 包,去停用词,字母小写化,删除标点,纠错,词形还原等
# ...省略,详细见附录源码
# 标签 data 的 Score 如果大于3,那么就是正面评价,否则就是负面评价
data['sentiment'] = data['Score'].apply(lambda rating : +1 if rating > 3 else 0)
# 划分测试集合训练集
from sklearn.model_selection import train_test_split
train_text, test_text, train_labels, test_labels = train_test_split(data['Text'], data['sentiment'], random_state=2023)
接着进行特征工程和建模如下:
# 使用 TF-IDF 做特征工程
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer()
train_tfidf = tfidf.fit_transform(train_text)
#SVM建模
from sklearn import svm
clf = svm.SVC()
model = clf.fit(train_tfidf, train_labels)
#预测
test_tfidf = tfidf.transform(test_text)
predictions = model.predict(test_tfidf)
#效果评估
from sklearn.metrics import accuracy_score
print(accuracy_score(test_labels, predictions))
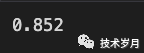
(评估准确率得分)
B. Pang, L. Lee, S. Vaithyanathan 最早利用机器学习算法进行情感分析的研究,他们分别使用了朴素贝叶斯、SVM和最大熵这三种有监督算法模型,实验结果表明SVM在三种方法中效果最优,准确率高达80%。随着连接派深度神经网络的崛起,基于深度学习的的情感分析研究大量出现。
03
基于深度神经网络的情感分析
相较于机器学习的特征工程,深度神经网络可以自动构建特征,尤其是对于文本特征,无论从词频统计还是其他统计方式所构建的特征都无法捕捉到词的相似性和相关性,而这是基于连接的深度神经网络所擅长的,因此大量 NLP 开始基于深度学习方法。
▌3.1 Word2Vec
Word2Vec 是 Word Embeddings (词嵌入)的一种表示方法,它能够捕捉词之间的相似性以及词义的各种关系。Word2Vec通过训练一个浅层神经网络(浅层的意思是它只有一个隐藏层),使得这个神经网络能够根据当前词预测其周围的词 (该方法也叫 Skip-gram),或根据用上下文信息预测当前词(该方法也叫 Continuous Bag of Words,缩写 CBOW)。经过训练后,我们可以提取神经网络的词向量表示,以便在其他自然语言处理任务(情感分析)中使用。
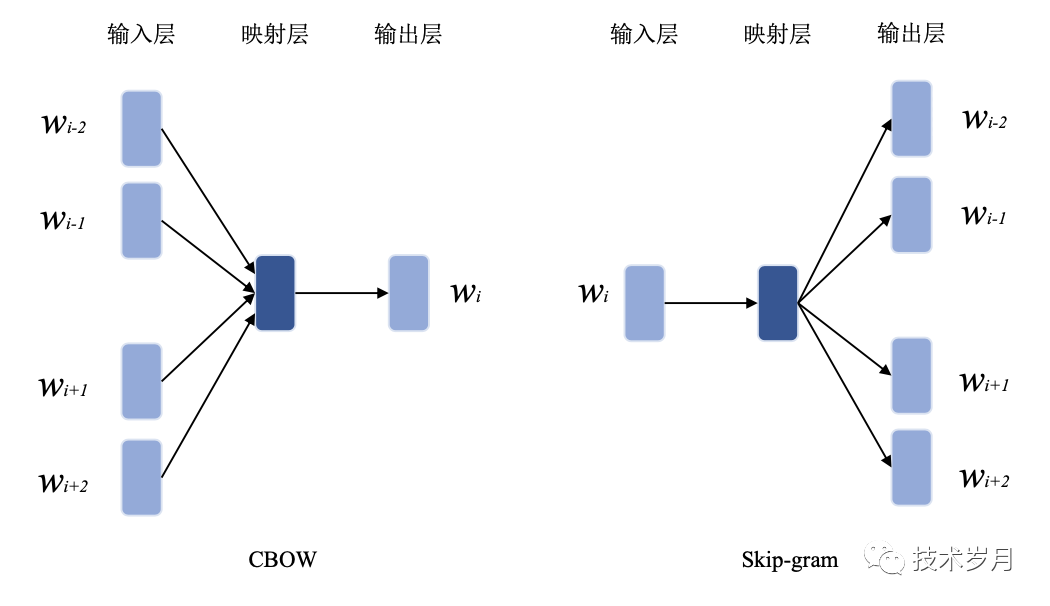
(图片来自邓钰博士论文[3])
以 Skip-gram 为例:
假设我们有一个句子:“猫在沙发上睡觉”,我们设置窗口大小为 2(上下文的范围)。现在,我们要根据"猫"、“沙发"这两个上下文词预测目标词"在”。
Skip-gram方法会尝试不断调整网络权重改变这两个词的向量,以使预测目标词的概率最大化。训练完成后,每个词都会对应一个向量表示。
"猫"可能对应向量 [0.06, 0.52, -0.23, …]"沙发"可能对应向量 [0.72, 0.35, -0.61, …]
因此 Word2Vec 能够捕捉词义的相似性及各种关系,其所构建的词向量具有连续性、稠密性,且具有较低的维度,适用于许多机器学习和深度学习模型进一步做情感分析建模。在情感分析任务中,可以利用词向量之间的距离或相似度来度量词语与情感之间的关系。
Word2Vec 也有其缺点,首先对于未出现在训练语料库中的词(未登录词),无法直接提供向量表示。其次它无法有效处理多义词的情况,因为每个词只有一个固定的向量表示,和上下文无关,无法做到词义消歧。
“bank" 在英语中有银行的意思,也有河岸的意思,我们需要根据该词的上下文推断其具体词义。
"球" 在中文中可以指代圆形物体,也可以是足球、篮球、羽毛球、乒乓球,在不同上下文中词义千差万别,不能用一个向量统一替代。
▌3.2 GloVe
GloVe (Global Vectors for Word Representation 全局词向量)是一种无监督学习算法,基于词与词之间的共现统计信息,通过最小化上下文词与目标词概率之间的平方损失来产生词向量。
与Word2Vec方法不同,GloVe 考虑了整个语料库的统计信息,而不是局限于固定大小的滑动窗口。
举例说明:
假设在某个语料库中,两个词语 “ice” 和 “steam” 共同出现场景较少,而 “ice” 和 “water” 以及 “steam” 和 “water” 共同出现场景较多。通过学习词共现矩阵,GloVe 可以发现这些词之间的关系,将 “ice” 和 “steam” 关联起来,具有类似语义的词在向量空间中的距离更近。
其优点是利用了全局统计信息,因此在捕获词与词之间的关系方面更有效,因此也具有更好的可解释性。但 GloVe 仍无法有效处理多义词的情况,因为每个词仅有一个固定的向量表示。同时对语料库的预处理需求较高,因为需要构建词共现矩阵和计算全局共现统计信息。
▌3.3 FastText
FastText 是一种基于 Word2Vec 的改进模型,它不仅可以为每个单词生成一个向量表示,还可以为每个单词的 N-gram 子序列生成向量表示,然后将单词向量和其子序列的向量相加,得到最终的向量表示,这种方法可以捕捉到单词的内部结构和上下文信息。
举例来说
对于词语 “apple”,FastText 可以表示为子词集合:
{“app”, “appl”, “ple”, “pple”, “apple”}然后将这些子词的向量表示与整个词的向量表示求和,得到最终的词向量表示,利用子词信息提高词向量表示的泛化能力和准确性。
我喜欢看足球比赛经过分词处理后,再以字符 N-gram(假设 n=2)进行字符细粒度拆分如下。
我: 我
喜欢:喜欢, 喜, 欢
看: 看
足球:足球, 足, 球
比赛:比赛, 比, 赛
FastText 模型进行训练,过程中同时考虑子词信息(比赛、比、赛)。通过以上过程,FastText 可以在多粒度上表示词语,更好地捕捉词形变化、构词规律等信息。如字“决赛”与“比赛”,“决”与“比”意义较远,但由于它们都含有“赛”字,这种联系在FastText 模型中可以得到体现,提高词向量表示的泛化能力。
04
基于语言模型的情感分析
以上介绍的方法均是将文本词语转为数值向量,属于空间向量模型(Vector Space Model),通过提取词语的数学特征,为进一步的文本挖掘、相似性度量、聚类、分类等任务提供基础。
接下来要介绍的语言模型(Language Model)是一种计算词语在给定语料库上的概率的方法。语言模型通俗讲就是通过计算语句存在的概率,来判断词语序列是不是真实自然语言(这些词连在一起还是不是人话)。语言模型可以用于文本生成、文本自动补全、拼写纠错等任务,也可通过微调来完成情感分析等任务。
向量空间模型主要关注如何将文本(词语)表示为向量,而语言模型则关注计算给定文本序列(词语)的概率,对于一个确定的概念或表达,哪种表示结果的可能性更大。
比如翻译这段文字:
今天天气很好.1 = Today is a fine day.2 = Today is a good day.
最后要的结果通过判断 P(1)和 P(2)哪个概率更大。
语言模型主要包括:统计语言模型如 N-gram模型,和基于神经网络的语言模型,如 LSTM、GRU、基于 Transfomer 的语言模型(大语言模型)。
▌4.1 N-gram
N-gram 模型是基于马尔科夫假设的统计语言模型,是计算自然语言中长度为 N 的连续词组出现的频率。
给定一个句子:S = {w1,w2,w3,…,wn}
生成该句子的概率为:p(S) = p(w1,w2,w3,w4,w5,…,wn)
链式法得到:p(S) = p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn-1)
最后这个 p(S) 就是我们所要的统计语言模型。
但是由于语料中数据稀疏问题, p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn-1) 最后很可能变成了 0,所以要做一个简化。其实文本中的词,它出现的概率很大程度上由这个单词前面的一个或几个单词决定的(和后继词无关),这就是马尔科夫假设。
那么通过假设其与 1个,2个,3个,N个词决定,可以做如下计算:
Unigram:N=1,即单个词的频率。在这种情况下,模型仅考虑每个词的概率,而忽略词与词之间的关系。例如,对于文本“我爱你,你爱我”,Unigram概率分布为:P(我)=0.33,P(爱)=0.33,P(你)=0.33。
Bigram:N=2,即两个连续词的频率。此时,模型计算每个词在给定前一个词的情况下的概率。例如,对于文本“我爱你,你爱我”,Bigram概率分布为:P(我|爱)=0.5,P(你|我)=1,P(爱|我)=0.5等。
Trigram:N=3,即三个连续词的频率。在这个模型中,每个词的出现概率依赖于其前两个词。例如,对于文本“我爱吃苹果,我爱喝水”,Trigram概率分布为:P(吃|我爱)=0.5,P(喝|我爱)=0.5,P(苹果|爱吃)=1等。
N-gram:N>3,通常用于捕捉更长的词组关系。随着N的增加,模型可以捕捉到更丰富的上下文信息。然而,随着N的增加,概率分布的计算量和数据稀疏性问题也会增加。可以采用平滑技术(如Add-One平滑、Good-Turing平滑等)来处理概率分布的计算。
在情感分析任务中,N-gram模型可以捕获局部情感信息,所学习到的概率分布可以用于评估文本的情感倾向。
▌4.2 基于 Transformer 模型
Transformer 自问世以来,由于其良好的算法设计,更易并行化处理,可以捕捉长距离位置信息,比 RNN / LSTM 具备更优异的表现,已成为 NLP 领域的一种强大且受欢迎的算法。
Transformer Embedding 是一种基于注意力机制的模型编码方法,它能够捕捉单词的位置信息,关注单词的上下文关系和语义,即模型关注输入序列中每个单词与其他单词之间的关系,进而消除单词歧义,提高模型的准确性和泛化能力。
举例说明:
The animal didn't cross the street because it was too tired.这里 it 指代的是 animal 还是 street?这个问题人类肯定可以阅读理解得出,而对于机器如何理解呢?
通过 Attention 公式计算(具体原理下次展开讲讲)得出,animal 和 it 的相关性更高,因此 it 指代 animal。

(图片来自网络:注意力相关性,橘色相关性强)
对于给定的输入句子,它首先计算出每个单词与其他单词的相关性,然后根据这些相关性将它们组合在一起。这样可以捕捉到句子中所有单词之间的复杂关系,从而更好地表达句子的含义。而基于此预训练出的模型,可以通过微调应用下游情感任务分析中。
目前已经有大量预训练的基于 Transformer 的语言模型,而通常由于其参数量巨大,也被称为大语言模型。如 BERT、GPT、T5 、GLM、PalM 等,这些模型已经在大型语料库上进行了预训练,参数中已“记忆了“大量词向量及其关系,可以通过微调后直接应用到下游任务(如情感分析)中。
下面通过案例讲解如何使用大语言模型做情感分析:
首先选择一个合适的预训练语言模型(如 BERT、GPT或其他 Transformer-based模型),这些预训练模型已经在大量语料上进行了训练,可以捕捉到词汇之间的语义和句法关系。
然后利用这些预训练模型进行迁移学习,将模型适应到具体的情感分类任务。具体步骤如下:
(1)准备标注数据,和机器学习一样
(2)微调预训练模型:加载预训练模型,并在模型顶部加上一个全连接层,用于输出分类预测。使用训练集对模型进行微调,使其学习特定的情感分类任务。
(3)模型评估与选择:在验证集上评估微调后的模型性能,如准确率、F1分数等。可以通过调整模型参数、模型结构或训练策略(如学习率、批次大小等)进行优化。
(4)完成情感分类:使用训练好的模型对未标注的文本进行情感分类。
这里使用 RoBERTa 做演示, Robustly Optimized BERT Pre-training Approach 是根据 BERT 模型架构进行改进的,采用的训练数据比 BERT 更大,训练过程中还采用了一些其他的优化策略,例如动态掩码,更长的序列长度等。
#这里仍选用上面的 Amazon Fine Food ReViews 数据集#加载模型
import torch
import transformers
# 加载 RoBERTa 预训练模型和 tokenizer
model = transformers.RobertaForSequenceClassification.from_pretrained('roberta-base')
tokenizer = transformers.RobertaTokenizer.from_pretrained('roberta-base')
# 将train_text_data转成可放入 tokenizer 的格式
train_text_token = tokenizer.batch_encode_plus(train_text.values.tolist(), max_length=128, padding=True, truncation=True)
# 将数据包装成 PyTorch tensor 格式
train_dataset = torch.utils.data.TensorDataset(torch.tensor(train_text_token['input_ids']),
torch.tensor(train_text_token['attention_mask']),
torch.tensor(train_labels.to_list()))
# 训练微调模型
# 定义训练参数和优化器
batch_size = 32
epochs = 5
optimizer = torch.optim.Adam(params=model.parameters(), lr=1e-5)
# 训练
model.train()
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
for epoch in range(epochs):
for batch in train_loader:
input_ids, attention_mask, labels = tuple(t for t in batch)
optimizer.zero_grad()
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
logits = outputs.logits
loss.backward()
optimizer.step()
基于 RoBERTa 模型对带标签的文本分类数据做了微调训练,训练后在用于评估测试数据。
# 验证
model.eval()
with torch.no_grad():
val_encodings = tokenizer(test_text.values.tolist(), truncation=True, padding=True, max_length=128)
val_dataset = torch.utils.data.TensorDataset(torch.tensor(val_encodings['input_ids']),
torch.tensor(val_encodings['attention_mask']),
torch.tensor(test_labels.tolist()))
val_loader = torch.utils.data.DataLoader(val_dataset, batch_size=batch_size)
num_correct = 0
num_total = 0
for batch in val_loader:
input_ids, attention_mask, labels = tuple(t for t in batch)
outputs = model(input_ids, attention_mask=attention_mask)
logits = outputs.logits
predictions = torch.argmax(logits, dim=1)
num_correct += (predictions == labels).sum().item()
num_total += labels.size(0)
accuracy = num_correct / num_total
print(f'Accuracy: {accuracy:.2f}')
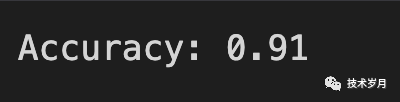
(评估准确率得分)
这里可以看到使用了相同的样本,微调后的 RoBERTa 情感分类的准确率是 0.91 (高于 SVM 的 0.85),但是微调时间也是真长,几百条数据做了 5次 epoch 用了 25min (mac Intel i5 Core 4c)。
这里使用的 RoBERTa-Base 参数量(约为 1.1亿) 仍然比较小,可以使用 GPT3.5、GPT4、PaLM2 等更大模型来做情感分析任务,当然计算量也会更大,最好上 GPU 来跑。
05
总结与展望
对文本进行情感分类是一条无止尽的路,不断有新的方法涌现,这张图很好的展示了对于 Embedding 技术的发展历程。
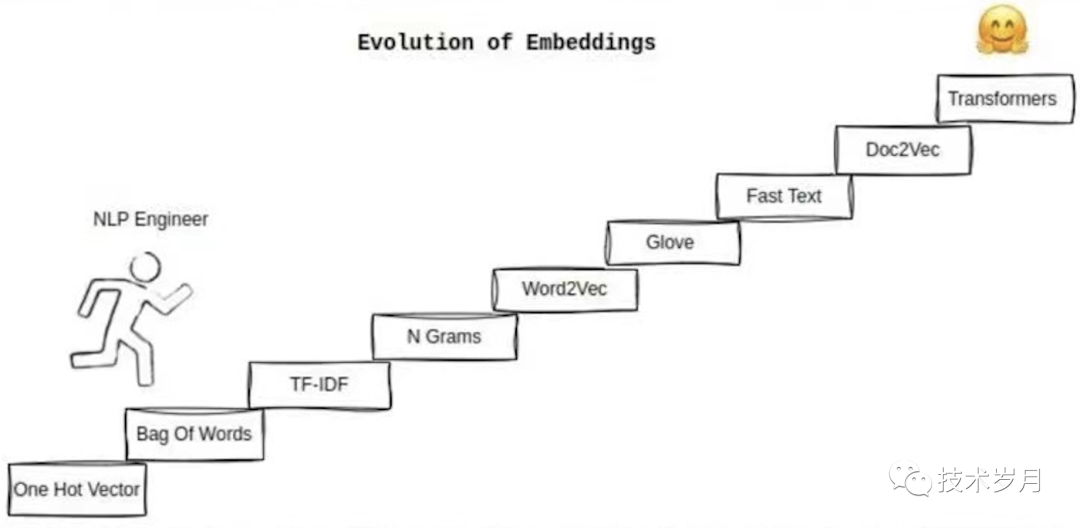 (图片来自网络)
(图片来自网络)
最后对常用文本情感分析方法做个汇总:
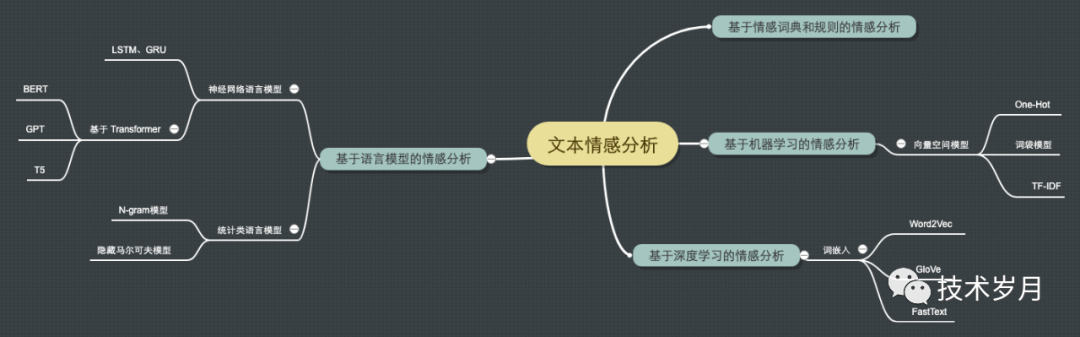
▌展望
鉴于篇幅和研究有限,仍有一些研究方法并未提及或展开。基于知识图谱和图神经网络的情感分析方法也是目前主流研究方向。本文研究的情感分析更偏向于社交媒体评论类的短文本情感分析,对于新闻类文档型长本文,有 LDA Doc2Vec 方法。对于中文的分词方法也有诸多研究和困难点未展开说明。此外,基于图片、视频、音频、文本等多模态的研究方法也是未来的研究方向。
▌参考文献
[1] B. Pang, L. Lee, S. Vaithyanathan. Thumbs up? sentiment classification using machine learning techniques[C]. Empirical Methods in Natural Language Processing, 2002: 79-86
[2] B. Liu, L. Zhang. Sentiment analysis and opinion mining[J]. Synthesis Lectures on Human Language Technologies, 2012,5(1):1-167
[3] Samar Al-Saqqa and Arafat Awajan. The Use of Word2vec Model in Sentiment Analysis: A Survey[J]. Association for Computing Machinery, 2019: 39-43
[4] 邓钰. 面向短文本的情感分析关键技术研究. 2021. [D]. 电子科技大学
[5] Deng, Xiang, et al. LLMs to the Moon? Reddit Market Sentiment Analysis with Large Language Models. Companion Proceedings of the ACM Web Conference 2023
[6] Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30
[7] 闫晓妍. 基于深度学习的中文在线评论情感分析研究.2022. [D]
[8] Zhang W, Deng Y, Liu B, et al. Sentiment Analysis in the Era of Large Language Models: A Reality Check[J]. arXiv preprint arXiv:2305.15005, 2023
文章完整代码和数据请关注公众号 技术岁月 ,发送关键字 情感分析 获取。