
CV领域中的Bert,了解一下?
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


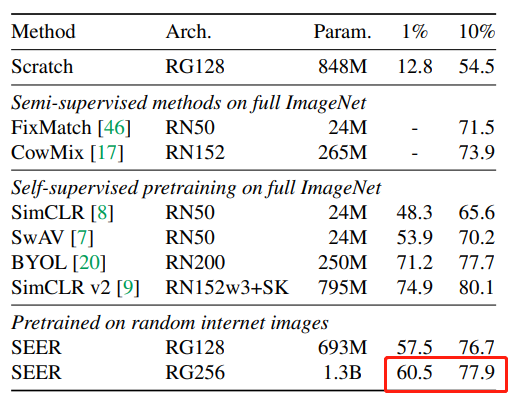
Facebook AI 用 10 亿张来自Instagram的随机、未标注图像预训练了一个参数量达 13 亿的自监督模型 SEER,该模型取得了自监督视觉模型的新 SOTA,可能会为计算机视觉领域打开一个新篇章。

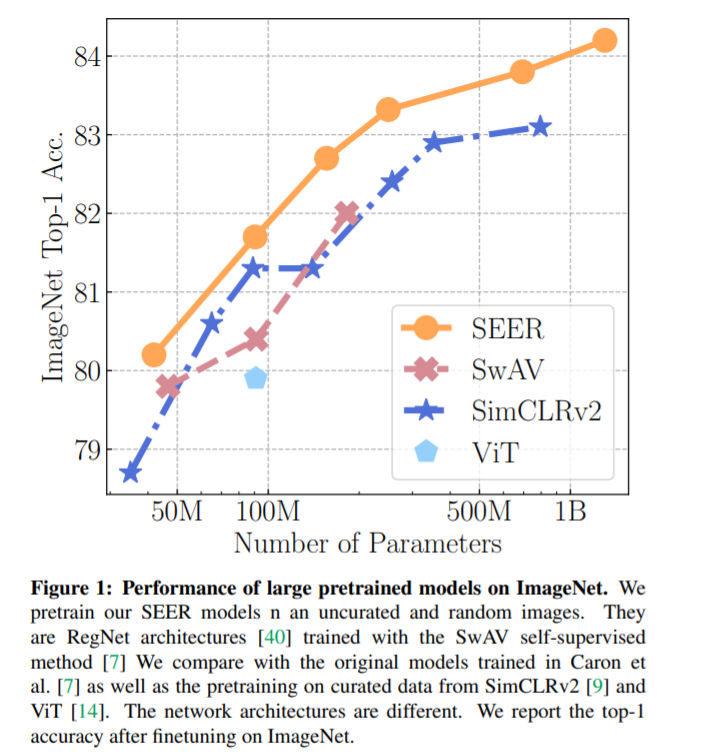


第一为算法,其需要从大量的随机图像中学习,而不需要任何元数据或注释;
第二为卷积网络,ConvNet——模型需要足够大,可以从数据中捕捉和学习每一个视觉概念。

推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!
评论