
如何正确的使用一条SQL删除重复数据

数据库中表存在重复数据,需要清理重复数据,清理后保留其中一条的情况是比较常见的需求,如何通过1条SQL准确的删除数据呢?
1. 创建表及测试数据
1.1 数据库中创建一张测试表
CREATE TABLE `test` (`id` INT NOT NULL AUTO_INCREMENT,`c1` VARCHAR(20) DEFAULT NULL,`c2` VARCHAR(20) DEFAULT NULL,`c3` INT DEFAULT NULL,`c4` DATETIME DEFAULT NULL,PRIMARY KEY (`id`)) ENGINE=INNODB DEFAULT CHARSET=utf8;
1.2 插入测试数据
INSERT INTO test(c1,c2,c3,c4) VALUES( 'a','b',10, '2022-05-24 18:00:46'),('a','c',20, '2022-05-24 18:00:46');INSERT INTO test(c1,c2,c3,c4) VALUES( 'a','c',10, '2022-05-24 18:00:46'),('a','b',20, '2022-05-24 18:00:46');INSERT INTO test(c1,c2,c3,c4) VALUES( 'b','c',10, '2022-05-24 18:00:46'),('d','b',20, '2022-05-24 18:00:46');INSERT INTO test(c1,c2,c3,c4) VALUES( 'b','c',20, '2022-05-24 18:00:46'),('d','b',30, '2022-05-24 18:00:46');INSERT INTO test(c1,c2,c3,c4) VALUES( 'b','c',20, '2022-05-24 18:00:46'),('a','b',40, '2022-05-24 18:00:46');INSERT INTO test(c1,c2,c3,c4) VALUES( 'd','b',40, '2022-05-24 18:00:46'),('r','f',40, '2022-05-24 18:00:46');
1.3 查看重复数据
例如c1,c2 这2个字段组合作为唯一条件,则查询重复数据的SQL如下
SELECTc1,c2,COUNT(*)FROMtestGROUP BY c1,c2HAVING COUNT(*) > 1;
可见,结果如下:

2. 如何删除重复数据
2.1 方案一
很多研发同学习惯的思路如下:
先查出重复的记录(使用in)
再查出在重复记录但id不在每组id最大值的记录
直接将select 改为delete进行删除
查询SQL如下
SELECT * FROM testWHERE (c1,c2) IN (SELECT c1,c2FROM testGROUP BY c1,c2HAVING COUNT(*)>1 )AND id NOT IN (SELECT MAX(id)FROM testGROUP BY c1,c2HAVING COUNT(*)>1)ORDER BY c1,c2;
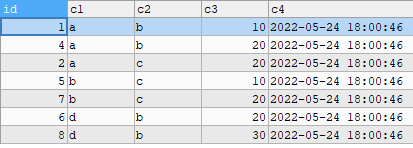
看上去比较符合结果了,但是改为delete执行的时候结果如下:
-- delete SQLDELETE FROM testWHERE (c1,c2) IN (SELECT c1,c2FROM testGROUP BY c1,c2HAVING COUNT(*)>1 )AND id NOT IN (SELECT MAX(id)FROM testGROUP BY c1,c2HAVING COUNT(*)>1)
出现报错信息:
错误代码:1093You can't specify target table 'test' for update in FROM clause
也就是说MySQL里需删除的目标表在in子查询中时,不能直接执行删除操作。
3. 推荐写法
基于以上情况,使用单条SQL删除的方式如下:
查询SQL:
SELECT a.*FROM test a ,(SELECT c1,c2,MAX(id)id FROM test GROUP BY c1,c2 HAVING COUNT(*)>1)bWHERE a.c1=b.c1 AND a.c2=b.c2AND a.id <>b.id

删除SQL
DELETE aFROM test a ,(SELECT c1,c2,MAX(id)id FROM test GROUP BY c1,c2 HAVING COUNT(*)>1)bWHERE a.c1=b.c1 AND a.c2=b.c2AND a.id <>b.id
结果:
查询:delete a FROM test a , (select c1,c2,max(id)id from test group by c1,c2 having count(*)>1)b where a.c1=b.c1 and a.c2=b.c2 and a.... 共 7 行受到影响
删除后数据如下:
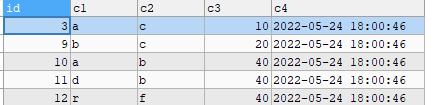
无重复数据了。

2. mysql8.0新增用户及加密规则修改的那些事
3. 比hive快10倍的大数据查询利器-- presto
4. 监控利器出鞘:Prometheus+Grafana监控MySQL、Redis数据库
5. PostgreSQL主从复制--物理复制
6. MySQL传统点位复制在线转为GTID模式复制


评论