
揭秘:如何考察前端的 Node.js 及工程能力
正文如下
本文是第二十二届 - 前端早早聊面试专场,也是早早聊第 161 场,来自阿里云高可用架构团队 - 雪卒 分享的图文讲稿
聊聊面试
说起面试,其实每个面试官他都有自己的一套方法论。
我记得我刚入职阿里的时候,我给团队内推了一个候选人,然后我团队的另外一个高 P 面试的,面完之后我问他候选人怎么样。他可能因为忙,然后也没有怎么详细说,他就回复我三个字,他说味不对,我的心里就挺一头雾水的,就是什么是味儿不对。
其实我觉得这么多年面试下来,面试官他是有自己的一个考量标准,然后根据候选人他的表现来考察,说白了就是是否合他的胃口。
所以说面试这个东西其实是非常主观的一个事情,可能会经常发生这个团队觉得不合适,但是又入职了同家公司另一个团队,这些都是跟面试官自己从事的领域、和他的工作经历、还有他对面试考量标准有关。
Node.js 可以做什么

Node.js 领域是非常多的,生态是非常大的。它是一门语言,背后其实代表的是整个工程工具,还有服务,以及整个的一个大领域。
所以做 Node.js 的人其实也有出现隔行与隔山的现象。在这么多领域里面,有可能你是做客户端领域的,有可能你是服务端领域的,有可能你是做实时推流的。
那么无论是做哪个领域,我们在面试的时候都尽量的需要有一套相同的一个标准去衡量,所以我抽象了一些考察候选人的侧重点。
考察候选人侧重点
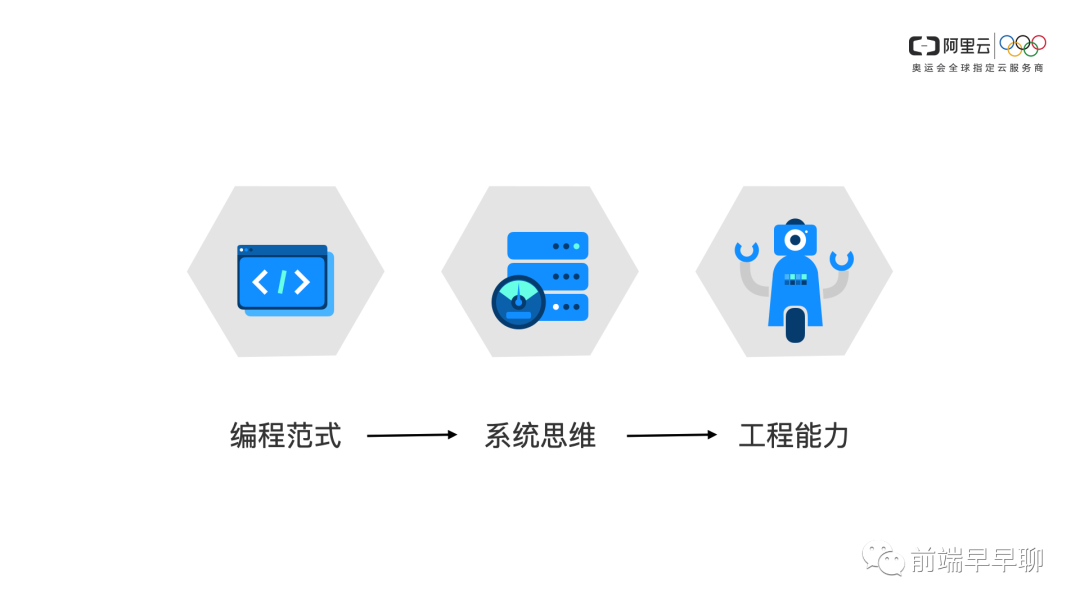
编程范式
我个人侧重的,首先是编程范式,有的人问我为什么不是编程,为什么不是基础,难道不应该基础是第一位的吗?
没错,基础确实是第一位的,那么我们在编程的过程中,其实基础是必须的。我通过你的编程,你的代码可以看出你的平时的编程习惯是怎么样的,你的风格是怎么样的,你对问题的思考路径是怎么样的,所以我称之为编程范式。
系统思维
第二个是系统思维,其实就是你对整个服务的设计,你是否是有一个全面的考量?这个是一般架构师必须具备的一个能力。
工程能力
工程能力其实就是把你的脑子里的对系统图、设计图、架构图去更好的落地的一个过程。
一个工程,我认为它是非常有技术含量的,他需要去考虑系统的边界,并且还需要考虑从应用开发完成,从部署到后面系统的可观测性、可运维性。
总结
工程和系统之间其实它们往往边界是模糊的,只是工程它可能在某些方面侧重于执行,那么这三者我认为是一个递进的关系。
首先你是有编程标准的一个编程范式,然后在你做系统的时候,逐渐形成你的方法论,最后你是如何把这个系统去落地下去、执行下去的。
编程范式
刚才讲到范式,但是我的理解就是你在 Node.js 领域是有一定的规范的。
比如 Node.js 标准的原生API,大家都知道它的 API 的风格是 callback 风格,它的第一个入参是 error,第二个入参是 callback。那么这种 API 形式是 Node.js 特有的一个 API 的风格或者说规范。
模式可以理解成就是你在解问题的时候,在思考的时候,你会形成一些的编程模型,或者说是思考的方式,或者说是设计模式。
那么通常我看到一些代码跟我的想法接近了,或者是他的解题思路也好,他的代码设计也好,我通常会觉得候选人跟我的味道还挺搭的。
上图我想表达的意思是条条大路都通罗马,一道题你可能有 ABCD 4种解法,对吧?可能其中一种解法和我相符合的话,我对你的好感会增加,所以面试确实是一个主观的东西。
案例
问题:磁盘上某目录下有 100 个 JSON 文件,请合并成 1 个 JSON 文件。
解法一
这个问题其实还是比较简单的,首先想到的是把 JSON 都 require,然后再一起合并。(如下图)

解法二
从解法一可能看得出来,这其实是有坑的,因为我并没有说 JSON 有多大单个,JSON 文件可能是非常大的,所以我就想到了我们去分批处理这些文件。(如下图)

每次读 20 个文件,然后把它合并在一起,那这样子是不是就避免了内存占用的问题?
看起来是这样,但是这里面又有一个基础知识的坑,就是 require 在 Node.js 模块系统里面,它是会缓存住的,require 的内存是常驻的。
所以上面这样的解法,其实是没有解决内存占用的问题,但是你的思路是对的,只是这里面是有基础知识的一个坑。于是我们就把 require 换一个写法,直接用 fs 模块读它,这个时候它就不会再内存里面常驻。(如下图)

解法三
到这里其实这道题的解法已经差不多了,通常我都会再问一下候选者:你还有没有其他的解法?
这个时候大家可以思考一下,通常如果说第三种解法是我这边我个人是比较青睐的解法,当然不代表这道题就必须要这样解,我只是想表达就是什么是编程范式。
因为大家都知道在 Node.js 里面,stream 这个模块是非常特殊,也是非常核心的一个模块,它可以以流的形式去读取一个文件,避免内存占用过大的一个问题。
它在处理批处理操作的时候,可以用 stream 的另外一个模式: objectMode。它是一种对象模式,我们把一件事情、或一个文件、或一个操作,抽象成一个对象。
这个对象它可以放到流里面去,像水管道一样的传给下面处理流、读入流,那么就可以挨个的去处理它。在开源的工具里面,给我印象比较深的就是 gulp,它就是利用了 objectMode 去做了构建工具。(如下图)

上图里面有两个参数,第一个是 objectMode,第二个就是 highWatermark。
当 objectMode 为 true 的时候,它在程序里面赋值为 20,它表示一次性处理流可以容纳 20 个处理任务,这个时候其实它代表了某种并发的意义,大家可以体会一下,在水管里面,它其实可以容纳20个处理流、或任务流。
回到刚才的话题,那个同学可能就会问你这代码也太多了,你解一个这么简单的题目去搞这么多代码,我前面的解法就已经足够用了。
我的观点是这样的,其实你不必要非得回答出这种解法三,但是如果你回答出解法三的时候,我可能会觉得是给我暗示,然后咱们能不能别再浪费时间了,直接上强度。对,如果你回答出解法三的话,我可能很多问题都略过了,因为我觉得你是一个练家子,所以这是我个人的考察的方式。
系统思维
系统其实是一个整体,同时它有很多的部件(或者说组件、模块)组成,这些部件必须是非常精密的,这些精密的部件就像齿轮一样咬合在一起,它才能够让这个系统非常高效的稳健的去运行。
给我的感觉就是,让候选人给我讲一个项目的时候,它是否是以一个系统的角度去讲,而不是仅仅是从业务上介绍我做这个平台主要是什么功能,然后主要是有哪些 Feature,我更希望可能听到的是怎么设计的,里面关键的架构是由哪些组件组成呢?每个组件我的思考是怎么样的?
案例
问题:请用 Node.js 原生 API 实现一个静态资源源站服务。
什么是静态资源源站服务?大家可能都用过 cdn,如果没有用过 cdn,可能就也用过 nginx,再不济可能会用过 express 或 koa 里面的中间件,就是 static 中间件,它可能是会把静态资源作为一个服务暴露出去,让我们的网页可以请求到 css、js、html 这些资源。
这里面的要求是用原生 API,为什么用原生 API?因为如果你用框架的话,其实几行代码就实现了。
在实现源站服务的时候,我们通常是怎么样的一个思路?这里列举了一些点:
思路 - 校验文件
首先我们会检查文件是否存在?是否是文件?而不是一个目录。
const http = require('http');
const { join } = require('path');
const { lstatSync } = require('fs');
const { URL } = require('url')
// 约定目录
const rootDir = join(require('os').homedir(), 'assets');
http.createServer((req, res) => {
const { pathname } = new URL(req.url);
// 检查文件是否存在
try {
const stats = lstatSync(join(rootDir, pathname));
if (!stats.isFile()) {
throw new Error('Not Found');
}
} catch (e) {
res.statusCode = 404;
return;
}
});
假设我们服务器上有一个约定的目录 rootDir,我的静态资源全部存在这里,所有的 URL 请求过来,我都是能够映射到约定目录下面的某个文件。
首先检测这个文件是否存在。这个文件如果不存在的话,就返回 404 Not Found,这是第一个想到的问题。然后我们可能会去查找文件,它是否是文件,而不是一个目录,这是一些必要的查找。
思路 - 资源合法性
接着检查资源的合法性,包括文件后缀,是否在约定目录里等等。
const { extname, join, realPathSync } = require('fs');
const validExts - [ '.js', '.css', '.png', /*...*/ ];
const fileExt = extname(pathname);
// 文件后缀是否合法
if(!validExts.includes(fileExt)) {
res.statusCode = 404;
return;
}
// 文件路径是否合法
const filePath = realPathSync(join(rootDir, pathname));
if (!filePath.startsWith(rootDir)) {
res.statusCode = 404;
return;
}
我们先检查一下文件的后缀,是不是 .js、.css 这些结尾的?如果不是的话,我认为他请求的不是一个合法的静态资源,我也会返回 404 或 500、或是其他你认为觉得比较语义化的 Code。
接下来的合法性校验是一个比较忽略的问题。我的文件很可能会请求到其他目录,而我这个目录可能是我在服务器端不想让你访问到的,是比较私密的一些文件。
这个时候我可能就要校验这个文件到底是不是存在于 rootDir 里面。下面如果不存在的话,我一样是不让访问的。
这个时候我会用 realpathSync,因为还是软链接的问题,我可能去校验真实的,我会取得它文件的真实路径,然后去判断这个是文件路径的合法性的一个校验。
思路 - 304
紧接着还会考察一下候选者对 HTTP 的基本协议是否了解。我们在协商缓存这里大家都比较清楚,304 的协议你可以用。If-Modified-Since 或者 Etag 去实现 304 的逻辑。这里就略过了。
// 实现 304,这里使用 If-Modified-Since,用 Etag 也是可以的
const clientModifiledTimeStamp = req.headers['if-modified-since'];
const expectedModifiedTimeStamp = new Date(stats.mtime).getTime();
if (clientModifiledTimeStamp && clientModifiledTimeStamp === expectedModifiedTimeStamp) {
res.statusCode = 304;
res.setHeader('Last-Modified', new Date(expectedModifiedTimeStamp).toGMTString());
}
思路 - 200
const fs = require('fs');
const CONTENT_TYPE_MAP = {
'.js': 'application/javascript',
'.html': 'text/html',
'.css': 'text/css',
// ...
};
const MAX_AGE_MAP = {
'.js': 86400,
'.html': 3600,
};
// 200 输出
res.statusCode = 200;
res.setHeader('Content-Type', CONTENT_TYPE_MAP[extname]);
res.setHeader('Cache-Control', `max-age=${MAX_AGE_MAP[extname]}`);
res.setHeader('Last-Modified', new Date(expectedModifiedTimeStamp).toGMTString());
最后我们要输出,会先设置响应码 200,然后我们会设置它的媒体类型,内容类型,然后还要注意设置它不同的针对不同的资源类型,你是否有不同的 Cache-Control 策略,这个是一个容易忽略的。
通常 html、js、css 是会缓存的时间会设置的比较大,这个地方并不一定以代码上这个值为标准,但是体现出你的一些思考,哪怕是这些数值都不一样。
// 此处省略 chatset 检测,假设是 utf-8
const charset = 'utf-8';
if (extname ==== '.html'/* ... */) {
// 提高 TTFB
fs.createReadableStream(filePath, { encoding: charset }).pipe(res);
} else {
res.end(fs.readFileSync(filePath, { encoding: charset }));
}
接下来我们就要把这个文件返回了,这个时候我们可能因为某些资源我们可以提高它的首字节响应,提高 TTFB,这个时候比如说 html,我就可以用流的方式去响应它,这个也是一个你自己对这个事情的思考。
这里是省略了 charset 的编码检测,如果你能说出来的话也是一个非常好的,因为这里面代码是涉及到比较多的,所以放不下了,所以这里做了一个假设。到这里的话一个基本 HTTP 请求响应的过程已经完成了。
思路 - 其他
通常还是会在再深挖一下,问一下这个候选人有没有什么其他的一些想法?那么我这里就罗列了一些
缓存设计 URL Combo Gzip压缩 图片类型检测 ......
比如我们的源站服务如果是用于生产的话,它一定是一个集群,我们现在的集群基本上都是容器化的,也就是容器化的一个最重要的特点,它是无状态的。那么刚才我们的例子,其实是放在静态资源文件是放在磁盘,这就非常的不利于扩展,不利于水平扩展。
这个时候我们是不是要设计一些缓存,通过这些缓存,无论是临时的缓存,还是永久的缓存弹性存储,我们都可以去设计一些,比如说内存的缓存,先把一部分的文件做一个 LRU 的内存的缓存,如果内存命中了直接返回,如果没有命中,我们再去磁盘上去查找文件,如果磁盘命中了返回,没有命中我们再去远端的比如说 redis 或者是阿里的 oss 这种弹性的这种存储,最终再去找一下这个文件,既提高了高可用,也提高了性能响应的效率。
第二个 URL Combo 是作为一个 CDN 源站。目前来看是比较基础的一个能力了,我比如说 url 后面拼接 1.js,2.js 这个时候,用一个请求去返回 1.js 和 2.js 整个内容。
第三个 Gzip,Gzip 通常其实是配置在 nginx,这个地方你也可以提一提,因为我们这边这道题没有提到前置有 nginx,但是在工业化标准上面,或者是在普遍的一个线上的最佳实践,我们不会在 Node 端去做 Gzip 的逻辑,因为那样子会很耗CPU,这个不是 Node 擅长的。然后下面可以可能图片类型检测,可能就是考察的你对现在现有 cdn 能力的一个认知了。
比如说我们在阿里的 cdn 它有这样的服务,就是我们对图片其实是可以返回 webp 的格式了。就针对png 这些图片我们。一旦通过浏览器的 user-agent 检测,那么其实是可以更智能的返回webp,这种格式来减少带宽。
一套下来,这道题就变得比较丰满。如果你能把从基础到后面的各种缓存,各种 Feature,各种高阶的功能的一些都能说出来的话,其实是我就会觉得你对源站的思考是比较完整的。
工程能力
工程其实就是把你的系统按照一定的规范去把它落地掉。

比如说你拿着设计图纸,这是你的系统设计,然后你把这个房子造出来,你造出来的房子不是说造完就拉倒,你还要引入物业对吧?
你要引入物业,然后让用户入住了之后都非常的舒服。平时的物业的与住户的协同,和能提供的服务取决于你的工程所完成的质量,也提高了用户的一个舒适度。
案例
问题:异构系统中 Java 与 Node.js 的同机部署方案。
背景 0.0
 上述问题其实是我几年前遇到的一个问题,然后我做了一个方案,这个问题我不会在面试的时候去这么问,因为这个是特有的一个阿里场景问题,我在这里只是仅仅是拿这个方案来举一个例子,工程化它可能会遇到哪些方面的挑战?
上述问题其实是我几年前遇到的一个问题,然后我做了一个方案,这个问题我不会在面试的时候去这么问,因为这个是特有的一个阿里场景问题,我在这里只是仅仅是拿这个方案来举一个例子,工程化它可能会遇到哪些方面的挑战?
那么这个时候我们先说一下背景,因为几年前和大家一样,我们都是前端站队 react,特别是阿里站队的是 react,那么我们的 react 就在 15、16 年就迅速的在业务线铺开。
那么当时阿里的外部层的架构全部都是 Java 技术栈,基本上这个地方我没有把后面的微服务,就后面的微服务我就不画了,我就只是画到 web 这一层。
背景 1.0
各个业务系统都是 Java,然后 react 在客户端,在浏览器端去做 CSR 的客户端渲染,逐渐跑了一段时间,发现我们业务上其实是有一定的诉求的。
比如说我们有一些业务是要 seo 的诉求,我们如果纯客户端渲染的话,对搜索引擎不够友好,还有一些我们的广告投放对吧?也是需要借助于 seo 的能力的。所以我们也考虑到商业的角度,我们需要有去做服务端渲染的诉求。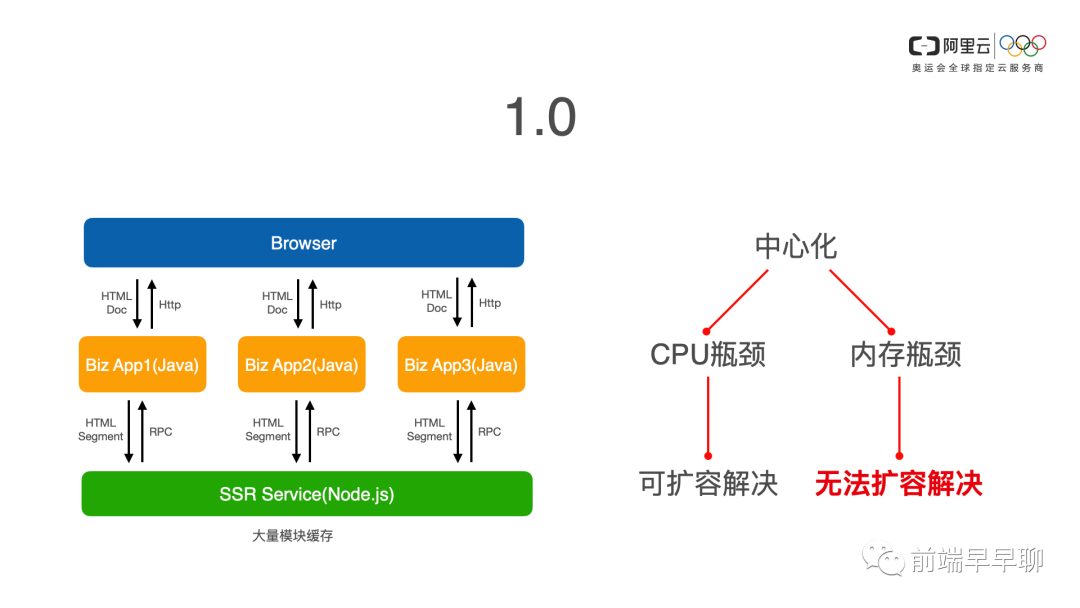
那么同时有些站点在服务端渲染上,确实能够提高一定的渲染性的。于是我们就设计了 react 的 ssr 的服务,当时是作为 1.0 的方案,在尽量不改动现有的架构的情况下,去做了这么一个服务。
那么刚开始我说的是异构系统,这里的异构系统就变成了 Java 和 Node.js 之间他们两个是不同的技术栈,和 react 里面的同构,不是一个相对立的一个概念。
这里的异构仅仅是说技术栈的不同,那么我们 1.0 的方案,我们就部署了一套极为庞大的 ssr service,就是 ssr5。
我们每个业务侧的代码都部署在前端代码也都会被 Node.js 服务所拉取到。当各个业务请求到具体的业务系统,Java 侧再请求我们统一的渲染服务。随着业务的逐渐的铺开,我们逐渐发现了一些问题。
首先我们的请求响应越来越慢,这个很好理解,随着业务的越来越多,Java 接入的越来越多,我们的 Node 的服务逐渐就不够用了。这个好办,于是我们就加机器扩容,扩容了之后又发现有问题。因为我们在中心化的这种渲染服务里面,我们为了性能,我们会大量的在内存里面去对 react 模块做缓存,如果你不缓存的话,性能肯定是不理想的。
我们也有做过压测的数据,所以我们在设计之初在系统上我们就设计了缓存的方案。那么这就遇到一个问题,我们水平扩展就无法解决了,因为我们每个容器都需要缓存所有业务的前端代码是数10万个模块和组件,这个时候中心化的问题就逐渐显现了。
如果说 CPU 出现渲染性能问题,我们还可以通过扩容来解决的话,那么我们的这种内存的缓存的设计,遭遇的瓶颈,我们已经无法通过扩容去解决了。所以在这种情况下,我们去做了 2.0 的方案。
背景 2.0
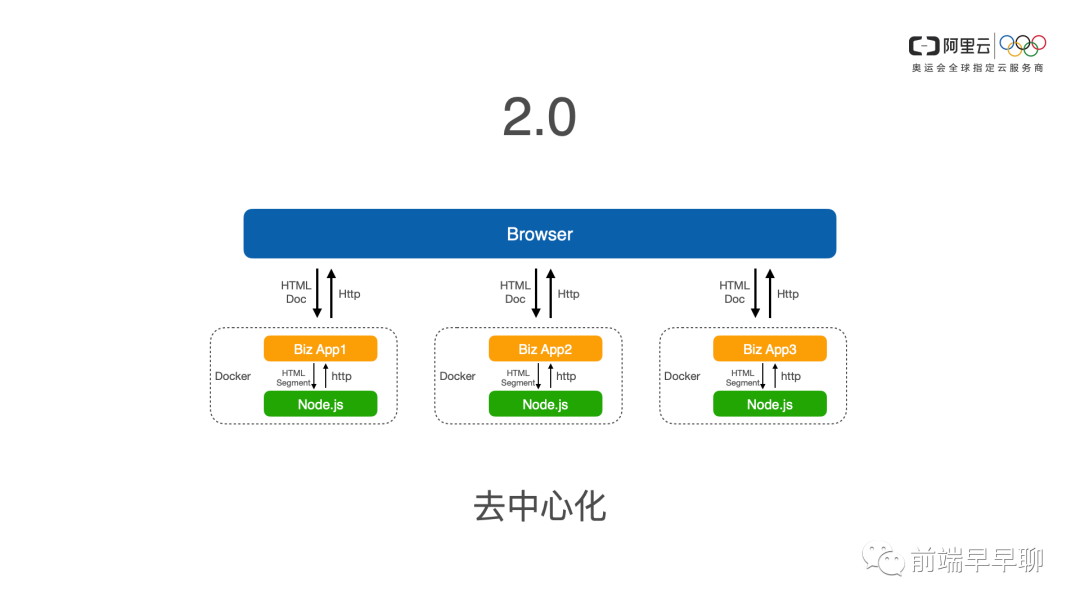 2.0 的方案是通过异构系统的同级部署,也就是 Java 和 Node 同级部署去解决这样的问题。那么我们每个 Node 的服务,只会拉取相应的业务系统的代码,也就是说我不会包含其他业务的代码,我只服务好我自己的业务就行了。
2.0 的方案是通过异构系统的同级部署,也就是 Java 和 Node 同级部署去解决这样的问题。那么我们每个 Node 的服务,只会拉取相应的业务系统的代码,也就是说我不会包含其他业务的代码,我只服务好我自己的业务就行了。
那么在同机的情况下,我们采用了简单的HTTP,因为在同期走内环地址 127 的情况下,它的 HTTP 性能是可以接受的,并且是在长连接的情况下,那么在这种方案下,现在我们这种方案已经被淘汰了,只是当时在这种方案下。看起来是当时最善的一个方案,最好的一个方案,或者说最合适的一个方案。
我们这里就不再讨论这个方案是否还有优化的空间,我们就单独去看 2.0 的问题,它其实是去中心化的问题,我们要把刚才说的无法水平扩展的问题去解决掉,同时我们的性能最终做出来也是有大幅的提升。
按照这种这样的方案,在落地的一个过程中,我们其实遇到了很多的问题,特别是对 Java 同学来说,你的 Node 是寄生在它的 Java 的业务容器里面的,你怎么去说服他,去把你的代码放到它的容器里面,并且还要和 Java 应用,共同占用内存,共同的去占用 CPU 资源系统资源的争夺。
当你的 Node.js 的死循环了怎么办?把我的 CPU 都打满了怎么办?我的业务是不是被你卡死了?等等问题,包括你的部署怎么办?难道在我的 Java 仓库里面把你的代码直接通过 get some module 打过来吗?
我不接受,当时很多 Java 同学就不同意。
思路 - 部署
最终我们是怎么样解决?首先在部署这一侧,因为是 Docker 的容器化部署,我们没有把 Node 的代码去直接嵌入到 Java 的仓库,我们最终采用了 rpm 包的方式。
Linux 它提供了 rpm 这种方式,它其实是对软件包的一种管理,就像 npm 包一样,我们其实也是可以把我们的服务就打成一个 RPM 包,然后只要在他们的 Docker 里面加一行,安装 rpm 包,然后在容器启动拉起来的时候,它也会把 Node 应用拉起来,这个是部署上我们解决了第一个部署的问题。
思路 - 安全

然后在安全上面,我们这里的安全指的是我在 Node 应用里面,我们去执行业务代码的时候,他业务代码其实是可能会写一些很奇怪的一些对服务端来说是不太合适的代码。这个时候可能会污染到服务端的一些环境。
如果说这里可能就发生概率比较小,如果说有人想搞怪你的系统的话,它的代码很可能就可以写一些恶意代码,当然我们的业务同学是不会这么搞的,这里只是一个说明对安全这一块我们的一个思考。
所以我们是通过 vm 模块来创建一个沙箱去运行它,这个可能可以最大程度的减少这个业务代码对 Node 服务端的一个侵入。同时我们在压测的过程中我们发现 Node.js 很有可能因为业务代码写得不规范,很有可能会导致死循环,这个是很可能发生的,而且我们已经发生了这样的问题。所以我们就必须要解这个问题。
我们为此开发了 egg-heartbeat,就是我们因为我们是基于 Egg.js 去搭建我们的 Node 服务的,所以这个是可能跟技术栈相关,但我相信这个原理是类似的,你如果是用其他的技术在你需要思考这样的问题,那么通过 Egg.js 的插件,我们可以通过一个进程去专门 worker,他提供了 agent 这种这种进程,这种它是可以对 worker 进程之间它是有一个它是可以连接做心跳检测。
那么我们通过这个插件,确保我们 worker 的一些死循环的代码一旦进入,瞬间这个 worker 就会被kill 掉。那么避免了对吧?这就是一种垄断措施了,就是当我们的代码发生问题的时候,我们就要把它熔断掉。
这个时候 Node 就会挂掉,这也是没有办法的,因为你的代码已经影响到这个业务了,如果你不及时的把它 kill 掉的话,甚至会连累到 Java,整台机器可能都会被这个容器干掉。
思路 - 监控
在工程领域里面有一个很重要的就是系统的可观测性,可观测性更多的一些监控的指标的建立。当时我们有阿里 monitor 这样的监控平台,可以提供这种脚本式的健康检查。

我们在监控平台,我们可以对 Node.js 进行一个探活的, 然后如果发现某台 Linux 挂的话,是会给我们发送报警,同时我们还有错误采集指令,我们可以在指定日志 Node 的日志目录,然后我们配置关键字,也是可以通过报警的方式来通知我们。
思路 - 性能
 那么接下来性能的话,我们有一个 Alinode 的平台,它是基于 node runtime 去做的一个版本,那么主要是提供了平台化的工具,白屏化的工具来观测 Node 它的实时的一个占用系统占用的指标。
那么接下来性能的话,我们有一个 Alinode 的平台,它是基于 node runtime 去做的一个版本,那么主要是提供了平台化的工具,白屏化的工具来观测 Node 它的实时的一个占用系统占用的指标。

那么讲到性能问题,其实在 rpm 包我们也提供了一些配置,因为有些业务,其实它的页面数量,它的 ssr 的比例并不高,有的会多一些高一些,有的会低一些,这个时候我们其实可以可以针对具体的情况来提供我们 node 的服务拉起来的一些配置。比如:
worker 进程数:通常它是和 CPU 的个数相同的,但是我们仍然支持可以配置 内存水位:就是我们的老生代的对象的空间,这个空间的大小会跟 V8 的 GC 的频率有一定关系。 模块缓存策略:我究竟是缓存多久?都是 lru 还是什么?这是我们暴露的配置,可以通过不同的业务可以根据它的配置去做一些更改。
思路 - 容灾

最后一个就是容灾。我们如果这个服务挂掉了,就像刚才说的死循环了,如果是发生死循环了,我们Node 的就会被熔断。
把 Node 熔断了之后,我不应该去影响业务,顶多就是 ssr 服务端渲染失败了,所以浏览器端继续CS2 继续客户端渲染,这是一个你需要去把这个方案做好的一个兜底。
刚才说了其实也只是说了一部分,从大面上来大概说了一下几个点,其实我们还做了很多的一些事情,这里简答列举一下,比如说我们的前端代码发布之后,我们怎么智能的同步到服务端,我们需要在服务端去做些什么,其实不用的,我们前端发布之后,我们其实打通了发布通道。Node 端它自动感知到,它会把最新的代码拉下来,重新把这个模块 reload 的等等这些工作。
总结
所以说工程化其实看你怎么做的,我相信不同的人做出来的方案是不同的,包括他的想法都是不一样的,即使是面对同一个命题。所以它是可大可小的,它的力度也是可以粗一点,可以细一点,这是你对工程化的理解。
建议
那么最后也给大家交流一下,也是我的一些心得。
第一条:多看一下源码,特别是比较业界比较流行的库和工具,比如说你最近要开发命令行,你可能去看一下 commander 这样的库,你可能如果要开发服务端,你可能要去看一下 express 和 koa,特别是 express 和 koa 它里面其实公用的很多的包都是非常好的。
特别是HTTP相关的,你还可以通过那些包来了解很多 http rfc 可以看到很多 rfc 的文档标准,其实你学到的就是更多的一些系统或者网络协议相关的东西。
第二条:多上手实践,特别是工程化,因为我觉得工程化你干的事情很杂,但是杂的过程中,如果你都是去认真思考每个点的话,其实给你带来的收益是比较大的。
你很可能通过复杂的一些点,慢慢构筑你的知识体系。所以说我认为前端工程化是非常有技术含量的,而不是说仅仅是打杂的,并不一定说一定是要深入 v8 底层要去做一些这种 runtime 的优化什么那些才是有技术含量的,主要是看领域。
第三条:多了解操作系统,因为 Node 说到底它是一门服务端的语言,无论是你开发工具,开发命令行开发桌面应用还是开发服务,它其实都是跟操作系统息息相关的。
我们在前端工程化做命令行的时候,也会针对 Mac、Windows、Linux 去做各种适配,这里面其实你有很多东西是可以学习到系统之间的差异的。