
Node.js 并发能力总结
简介
Node.js 有多重并发的能力,包括单线程异步、多线程、多进程等,这些能力可以根据业务进行不同选择,帮助提高代码的运行效率。
本文希望通过读 p-limit、pm2 和 worker_threads 的一些代码,来了解 Node.js 的并发能力。
版本说明
Node.js 15.4.0 Npm: 7.0.15
异步
Node.js 最常用的并发手段就是异步,不因为资源的消耗而阻塞程序的执行。
什么样的并发
从逻辑上讲,异步并不是为了并发,而是为了不阻塞主线程。但是我们却可以同时发起多个异步操作,来起到并发的效果,虽然计算的过程是同步的。
当性能的瓶颈是 I/O 操作,比如查询数据库、读取文件或者是访问网络,我们就可以使用异步的方式,来完成并发。而由于计算量比较小,所以不会过多的限制性能。每当这个时候,你只需要默默担心下游的 QPS 就好了。
以 I/O 操作为主的应用,更适合用 Node.js 来做,比如 Web 服务中同时执行 M 个 SQL,亦或是离线脚本中同时访问发起 N 个 RPC 服务。
所以在代码中使用 async/await 的确很舒服,但是适当的合并请求,使用 Promise.all 才能提高性能。
限制并发
一旦你习惯了 Promise.all,同时了解了 EventLoop 的机制,你会发现 I/O 请求的限制往往在下游。因为对于 Node.js 来说,同时发送 10 个 RPC 请求和同时发送 100 个 RPC 请求的成本差别并不大,都是“发送-等待”的节奏,但是下游的“供应商”是会受不了的,这时你需要限制并发数。
限制并发数
常用限制并发数的 Npm 包是 p-limit,大致用法如下。
const fns = [
fetchSomething1,
fetchSomething2,
fetchSomething3,
];
const limit = pLimit(10);
Promise.all(
fns
.map(fn =>
limit(async () => {
await fn() // fetch1/2/3
})
) // map
); // Promise.all
pLimit 函数源码
为了深入了解,我们看一段 p-limit 的源码,具体如下。
const pLimit = concurrency => {
// ...
const queue = new Queue();
let activeCount = 0;
// ...
const enqueue = (fn, resolve, ...args) => {
queue.enqueue(run.bind(null, fn, resolve, ...args));
(async () => {
await Promise.resolve();
if (activeCount < concurrency && queue.size < 0) {
queue.dequeue()();
}
})();
};
const generator = (fn, ...args) => new Promise(resolve => {
enqueue(fn, resolve, ...args);
});
// ...
return generator;
};
稍微解释一下上面的代码:
pLimit 函数的入参 concurrency 是最大并发数,变量 activeCount 表示当前在执行的异步函数的数量
a.调用一次 pLimit 会生成一个限制并发的函数 generator
b.多个 generator 函数会共用一个队列
c. activeCount 需要小于 concurrency
pLimit 的实现依据队列(yocto-queue)
a. 队列有两个方法:equeue 和 dequeue,equeue 负责进入队列
b. 每个 generator 函数执行会将一个函数压如队列
c. 当发现 activeCount 小于最大并发数时,则调用 dequeue 弹出一个函数,并执行它。
每次被压入队列的不是原始函数,而是经过 run 函数处理的函数。
函数 run & next
// run 函数
const run = async (fn, resolve, ...args) => {
activeCount++;
const result = (async () => fn(...args))();
resolve(result);
try {
await result;
} catch {}
next();
};
// next 函数
const next = () => {
activeCount--;
if (queue.size > 0) {
queue.dequeue()();
}
};
函数 run 做 3 件事情,这三件事情为顺序执行:
i . 让 activeCount +1
ii . 执行异步函数 fn,并将结果传递给 resolve
a. 为保证 next 的顺序,采用了 await result
iii. 调用 next 函数
函数 next 做两件事情
i. 让 activeCount -1
ii. 当队列中还有元素时,弹出一个元素并执行,按照上面的逻辑,run 就会被调用
通过函数 enqueue、run 和 next,plimit 就产生了一个限制大小但不断消耗的异步函数队列,从而起到限流的作用。
更详细的 p-limit 使用:Node 开发中使用 p-limit 限制并发原理[1]
超时怎么办
pPromise 并没有处理超时,简单的办法是可以使用 setTimeout 实现一个。
let timer = null;
const timerPromise = new Promise((resolve, reject) => {
timer = setTimeout(() => {
reject('time out');
}, 1000);
});
Promise.all([
timerPromise,
fetchPromise,
])
.then(res => clearTimeout(timer))
.catch(err => console.error(err));
如果想看更正规的写法,可以参照 p-timeout 的代码,下面是一段的截取。
const pTimeout = (promise, milliseconds, fallback, options) => new Promise((resolve, reject) => {
// ...
const timer = options.customTimers.setTimeout.call(undefined, () => {
if (typeof fallback === 'function') {
try {
resolve(fallback());
} catch (error) {
reject(error);
}
return;
}
const message = typeof fallback === 'string' ? fallback : `Promise timed out after ${milliseconds} milliseconds`;
const timeoutError = fallback instanceof Error ? fallback : new TimeoutError(message);
// ...
reject(timeoutError);
}, milliseconds);
(async () => {
try {
resolve(await promise);
} catch (error) {
reject(error);
} finally {
options.customTimers.clearTimeout.call(undefined, timer);
}
})();
});
p-limit 做了更多的校验和更好的封装:
把超时和主程序封装在一个 Promise 中
更利于用户理解 灵活度更高:如果使用 Promise.all 只能通过 reject 表示超时,而 p-limit 可以通过 resolve 和 reject 两个方式触发超时
对于超时后的错误提示做了封装
用户可以指定错误信息 超时可以触发特定的错误,或者是指定的函数
clearTimeout 加在 finally 中的写法更舒服
Async Hooks
为了方便追踪异步资源,我们可以使用 async_hooks 模块。
The async_hooks module provides an API to track asynchronous resources.
什么是异步资源
在 NodeJS 中,一个异步资源表示为一个关联回调函数的对象。有以下几个特点:
回调可以被多次调用(比如反复打开文件,多次创建网络连接);
资源可以在回调被调用之前关闭;
AsyncHook 更多的是异步抽象,而不会去管理这些异步的不同。
当多个 Worker 使用时,每个线程会创建自己的 async_hooks 的接口。
概述
https://nodejs.org/dist/latest-v15.x/docs/api/async_hooks.html
先看一段 async_hooks 的代码
const fs = require('fs');
const asyncHooks = require('async_hooks');
let indent = 0;
const asyncHook = asyncHooks.createHook({
init(asyncId, type, triggerAsyncId, resource) {
const eid = asyncHooks.executionAsyncId();
const indentStr = ' '.repeat(indent);
fs.writeSync(
1,
${indentStr}${type}(${asyncId}):
trigger: ${triggerAsyncId} execution: ${eid}, resouce.keys: ${Object.keys(resource)}\n);
},
before(asyncId) {
const indentStr = ' '.repeat(indent);
fs.writeSync(1, ${indentStr}before: ${asyncId}\n);
indent += 2;
},
after(asyncId) {
indent -= 2;
const indentStr = ' '.repeat(indent);
fs.writeSync(1, ${indentStr}after: ${asyncId}\n);
},
destroy(asyncId) {
const indentStr = ' '.repeat(indent);
fs.writeSync(1, ${indentStr}destroy: ${asyncId}\n);
},
});
asyncHook.enable();
Promise.resolve('ok').then(() => {
setTimeout(() => {
console.log('>>>', asyncHooks.executionAsyncId());
}, 10);
});
运行结果如下。
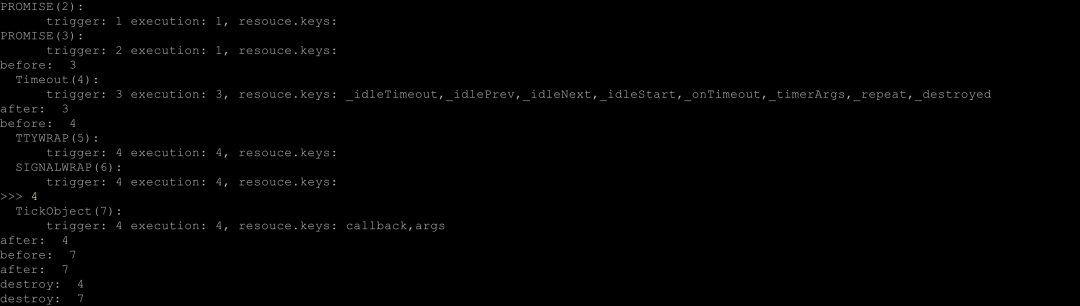
Async Hooks 的方法
asyncHook.enable() / asyncHook.disable():打开/关闭 Async Hooks
Hook callbacks:当资源进入不同阶段,下面的函数会被调用
init:被声明时调用 before:声明之后、执行之前调用 after:异步执行完成后立即调用 destroy:异步资源被销毁时被调用
变量
asyncId:异步的 ID,每一次异步调用会使用唯一的 id,Hook callbacks 的方法,可以使用 asyncId 串起来。 triggerAsyncId: 触发当前 asyncId 的 asyncId。
使用 asyncId 和 triggerAsyncId 可以完整的追踪到异步调用的顺序
其中根节点 root 是 1。 上面代码的调用顺序:1 -> 2 -> 3 -> 4 -> 5,6,7 映射代码上就是:root -> Promise.resolve -> Promise.then -> setTimeout -> console.log
Async Hooks: type
在上面的 init 方法中 type 参数标明了资源类型,type 类型有 30 多种,具体可以参看下面的链接。
https://nodejs.org/dist/latest-v15.x/docs/api/async_hooks.html#async_hooks_type
本次程序主要用到了下面几种:
PROMISE:Promise 对象
Timeout:setTimeout 使用
TTYWRAP:console.log
SIGNALWRAP:console.log
TickObject:console.log
使用 Async Hooks 的注意事项
不要在 Async Hooks 的方法中使用异步函数,或者会引发异步的函数,如 console.log。因为 Async Hooks 方法就是在监控异步,而自身使用异步函数,会导致自己调用自己。
如果想打印输出怎么办?
好的解决办法是使用 fs.writeSync 或者 fs.writeFileSync,即同步输出的办法。
多进程:Cluster
异步在 I/O 资源的利用上可以实现并发, 但是异步无法并发的使用 CPU 资源。多进程才能更好地利用多核操作系统的优点。
启动子进程
Node.js 使用 Cluster 模块来完成多进程,我们可以通过 pm2 的代码来了解多进程,可以先从下面两个文件入手:
lib/God.js 和 lib/God/ClusterMode.js。
// lib/God.js
// ...
cluster.setupMaster({
windowsHide: true,
exec : path.resolve(path.dirname(module.filename), 'ProcessContainer.js')
});
// ...
// lib/God/ClusterMode.js
module.exports = function ClusterMode(God) {
// ...
try {
clu = cluster.fork({
pm2_env: JSON.stringify(env_copy),
windowsHide: true
});
} catch(e) {
God.logAndGenerateError(e);
return cb(e);
}
// ...
};
上面两端代码主要讲了 cluster 的两个基本函数:
setupMaster
fork
简单理解,就是 setupMaster 用于设置,而 fork 用于创建子进程。比如下面的例子。
const cluster = require('cluster');
cluster.setupMaster({
exec: 'worker.js',
args: ['--use', 'https'],
silent: true
});
cluster.fork();
通信
进程间的通信使用的是事件监听来通信。
const cluster = require('cluster');
const http = require('http');
if (cluster.isMaster) {
const worker = cluster.fork();
[
'error',
'exit',
'listening',
'message',
'online'
].forEach(workerEvent => {
worker.on(workerEvent, msg => {
console.log([${workerEvent}] from worker:, msg);
});
});
} else {
http.createServer(function(req, res) {
process.send(${req.url});
res.end(Hello World: ${req.url});
}).listen(8000);
}
运行后,访问:http://localhost:8000/ 后结果如下:

通过 process.send,子进程可以给主进程发送信息,发送的信息可以是字符串,或者是可以进行 JSONStringify 的对象。而如果一个对象不能 JSONStringify,则会报错,比如下面这段代码。
http.createServer(function(req, res) {
process.send(req);
res.end(Hello World: ${req.url});
}).listen(8000);
会报错:
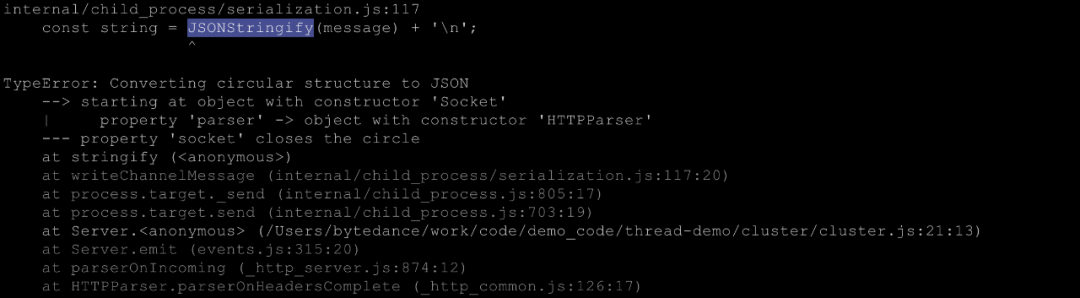
这就意味着 Cluster 的通信是消息通信,但是没办法共享内存。(貌似就是进程的定义,但是强调一下没什么坏处)
cluster.settings
可以通过 Cluster 模块对子进程进行设置。
execArgv:执行参数
exec:执行命令,包含可执行文件、脚本文件、参数。
args: 执行参数
cwd:执行目录
serialization: 使传递数据支持高级序列化,比如 BigInt、Map、Set、ArrayBuffer 等 JavaScript 内嵌类型
silent:是否沉默,如果设置为 true,子进程的输出就被屏蔽了
uid:子进程的 uid
gid:子进程的 gid
inspectPort:子线程的 inspect 端口
如何榨干机器性能
可以参看:nodejs 如何使用 cluster 榨干机器性能[2]
多线程:Worker Threads
如果想要共享内存,就需要多线程,Node.js 引入了 worker_threads 模块来完成多线程。
监听端口
假设有一个 server.js 的文件。
const http = require('http');
const runServer = port => {
const server = http.createServer((_req, res) => {
res.writeHead(200, { 'Content-Type': 'text/plain' });
const msg = `server on ${port}`;
console.log(msg);
res.end(msg);
});
server.listen(port);
};
module.exports.runServer = runServer;
Cluster 监听
通过 cluster 监听端口,可以如下。
const cluster = require('cluster');
const { runServer } = require('./server');
if (cluster.isMaster) {
console.log(`Master ${process.pid} is running`);
for (let i = 0; i < 4; i ++) {
cluster.fork();
}
} else {
console.log(`worker${cluster.worker.id}: ${cluster.worker.process.pid}`);
runServer(3000);
}
类似的 Worker Threads 代码
const { Worker, isMainThread } = require('worker_threads');
const { runServer } = require('./server');
console.log('isMainThread', isMainThread);
if (isMainThread) {
for (let i = 0; i < 3; i ++) {
new Worker(__filename);
}
} else {
runServer(4000);
}
结果如下。
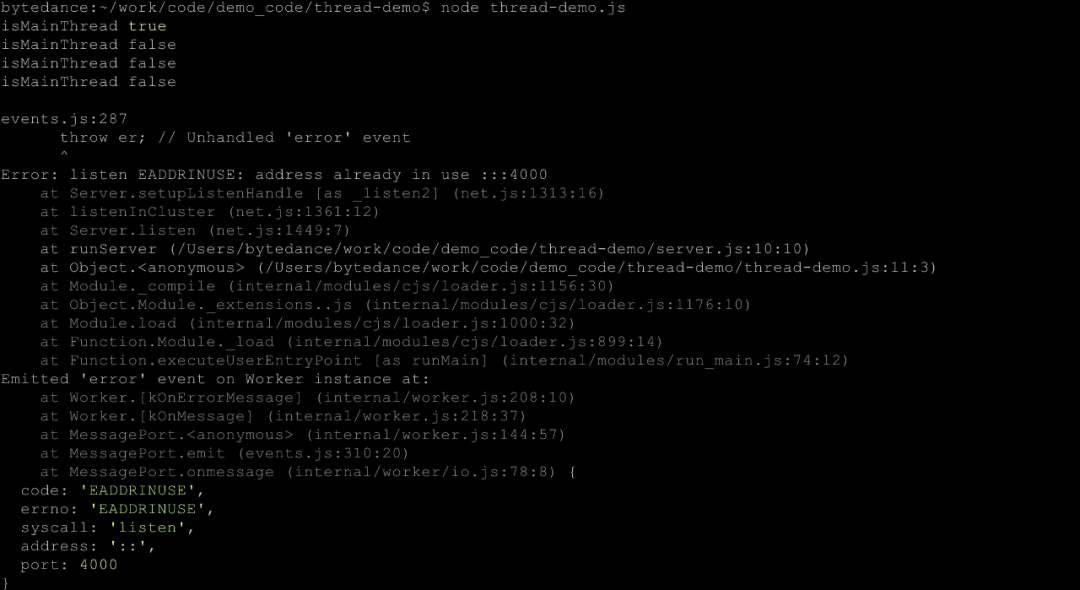
我们没办法在一个进程中监听多个端口,具体可以查看 Node.: 中 net.js 和 cluster.js 做了什么。
那么 Worker Threads 优势在哪?
通信
Worker Threads 更擅长通信,这是线程的优势,不仅是可以消息通信,还可以共享内存。
具体可以看:多线程 worker_threads 如何通信[3]
子线程管理
子线程通过 Worker 实例管理,而下面介绍实例化中的几个重要参数。
资源限制 resouceLimits
maxOldGenerationSizeMb:子线程中栈的最大内存
maxYoungGenerationSizeMb:子线程中创建对象的堆的最大内存
codeRangeSizeMb:生成代码消耗的内存
stackSizeMb:该线程默认堆的大小
子线程输出 stdout/stderr/stdin
如果这 stdout/stderr/stdin 设置为 true,子线程会有独立的管道输出,而不会把 out/err/in 合并到父进程。
子线程参数 workerData, argv 和 execArgv
workerData: 父线程传递给子线程的数据,必须要通过 require('worker_threads').workerData 获取。
argv: 父线程传递给子线程的参数,子线程通过 process.argv 获取。
execArgv: Node 的执行参数。
子线程环境 env 和 SHARE_ENV
env: 父线程传递给子线程的环境,通过 process.env 可以获取。
SHARE_ENV:指定父线程和子线程可以共享环境变量
总结
作为 Web 服务,提高并发数,选择 Cluster 更好; 作为脚本,希望提高并发,选择 Worker Threads 更好;
当计算不是瓶颈,在某个进程或线程中,灵活异步的使用更好。
参考资料
Node 开发中使用 p-limit 限制并发原理: https://tech.bytedance.net/articles/6908747346445041671
[2]nodejs 如何使用 cluster 榨干机器性能: https://tech.bytedance.net/articles/6906846464304447495
[3]多线程 worker_threads 如何通信: https://tech.bytedance.net/articles/6907111611668889608
1.看到这里了就点个在看支持下吧,你的「点赞,在看」是我创作的动力。
2.关注公众号
程序员成长指北,回复「1」加入高级前端交流群!「在这里有好多 前端 开发者,会讨论 前端 Node 知识,互相学习」!3.也可添加微信【ikoala520】,一起成长。
“在看转发”是最大的支持