
Python异步爬虫进阶必备,效率杠杠的!

Python异步爬虫进阶必备,
效率杠杠的!
爬虫是 IO 密集型任务,比如我们使用 requests 库来爬取某个站点的话,发出一个请求之后,程序必须要等待网站返回响应之后才能接着运行,而在等待响应的过程中,整个爬虫程序是一直在等待的,实际上没有做任何的事情。
因此,有必要提高程序的运行效率,异步就是其中有效的一种方法。
今天我们一起来学习下异步爬虫的相关内容。
一、基本概念
阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。常见的阻塞形式有:网络 I/O 阻塞、磁盘 I/O 阻塞、用户输入阻塞等。阻塞是无处不在的,包括 CPU 切换上下文时,所有的进程都无法真正处理事情,它们也会被阻塞。如果是多核 CPU 则正在执行上下文切换操作的核不可被利用。
非阻塞
程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的。非阻塞并不是在任何程序级别、任何情况下都可以存在的。仅当程序封装的级别可以囊括独立的子程序单元时,它才可能存在非阻塞状态。非阻塞的存在是因为阻塞存在,正因为某个操作阻塞导致的耗时与效率低下,我们才要把它变成非阻塞的。
同步
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。例如购物系统中更新商品库存,需要用“行锁”作为通信信号,让不同的更新请求强制排队顺序执行,那更新库存的操作是同步的。简言之,同步意味着有序。
异步
为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。例如,爬虫下载网页。调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无需相互通知协调。这些异步操作的完成时刻并不确定。简言之,异步意味着无序。
多进程
多进程就是利用 CPU 的多核优势,在同一时间并行地执行多个任务,可以大大提高执行效率。
协程
协程,英文叫作 Coroutine,又称微线程、纤程,协程是一种用户态的轻量级线程。协程拥有自己的寄存器上下文和栈。协程调度切换时,将寄存器上下文和栈保存到其他地方,在切回来的时候,恢复先前保存的寄存器上下文和栈。因此协程能保留上一次调用时的状态,即所有局部状态的一个特定组合,每次过程重入时,就相当于进入上一次调用的状态。协程本质上是个单进程,协程相对于多进程来说,无需线程上下文切换的开销,无需原子操作锁定及同步的开销,编程模型也非常简单。我们可以使用协程来实现异步操作,比如在网络爬虫场景下,我们发出一个请求之后,需要等待一定的时间才能得到响应,但其实在这个等待过程中,程序可以干许多其他的事情,等到响应得到之后才切换回来继续处理,这样可以充分利用 CPU 和其他资源,这就是协程的优势。
二、协程用法
从 Python 3.4 开始,Python 中加入了协程的概念,但这个版本的协程还是以生成器对象为基础的,在 Python 3.5 则增加了 async/await,使得协程的实现更加方便。
asyncio
Python 中使用协程最常用的库莫过于 asyncio
event_loop:事件循环,相当于一个无限循环,我们可以把一些函数注册到这个事件循环上,当满足条件发生的时候,就会调用对应的处理方法。 coroutine:中文翻译叫协程,在 Python 中常指代为协程对象类型,我们可以将协程对象注册到时间循环中,它会被事件循环调用。我们可以使用 async 关键字来定义一个方法,这个方法在调用时不会立即被执行,而是返回一个协程对象。 task:任务,它是对协程对象的进一步封装,包含了任务的各个状态。 future:代表将来执行或没有执行的任务的结果,实际上和 task 没有本质区别。
async/await 关键字,是从 Python 3.5 才出现的,专门用于定义协程。其中,async 定义一个协程,await 用来挂起阻塞方法的执行。
定义协程
定义一个协程,感受它和普通进程在实现上的不同之处,代码如下:
import asyncio
async def execute(x):
print('Number:', x)
coroutine = execute(666)
print('Coroutine:', coroutine)
print('After calling execute')
loop = asyncio.get_event_loop()
loop.run_until_complete(coroutine)
print('After calling loop')
运行结果如下:
Coroutine: 0x0000027808F5BE48>
After calling execute
Number: 666
After calling loop
Process finished with exit code 0
首先导入 asyncio 这个包,这样才可以使用 async 和 await,然后使用 async 定义了一个 execute 方法,方法接收一个数字参数,方法执行之后会打印这个数字。
随后我们直接调用了这个方法,然而这个方法并没有执行,而是返回了一个 coroutine 协程对象。随后我们使用 get_event_loop 方法创建了一个事件循环 loop,并调用了 loop 对象的 run_until_complete 方法将协程注册到事件循环 loop 中,然后启动。最后我们才看到了 execute 方法打印了输出结果。
可见,async 定义的方法就会变成一个无法直接执行的 coroutine 对象,必须将其注册到事件循环中才可以执行。
前面还提到了 task,它是对 coroutine 对象的进一步封装,它里面相比 coroutine 对象多了运行状态,比如 running、finished 等,我们可以用这些状态来获取协程对象的执行情况。在上面的例子中,当我们将 coroutine 对象传递给 run_until_complete 方法的时候,实际上它进行了一个操作就是将 coroutine 封装成了 task 对象。task也可以显式地进行声明,如下所示:
import asyncio
async def execute(x):
print('Number:', x)
return x
coroutine = execute(666)
print('Coroutine:', coroutine)
print('After calling execute')
loop = asyncio.get_event_loop()
task = loop.create_task(coroutine)
print('Task:', task)
loop.run_until_complete(task)
print('Task:', task)
print('After calling loop')
运行结果如下:
Coroutine: 0x000001CB3F90BE48>
After calling execute
Task: 3>>
Number: 666
Task: 3> result=666>
After calling loop
Process finished with exit code 0
这里我们定义了 loop 对象之后,接着调用了它的 create_task 方法将 coroutine 对象转化为了 task 对象,随后我们打印输出一下,发现它是 pending 状态。接着我们将 task 对象添加到事件循环中得到执行,随后我们再打印输出一下 task 对象,发现它的状态就变成了 finished,同时还可以看到其 result 变成了 666,也就是我们定义的 execute 方法的返回结果。
定义 task 对象还有一种常用方式,就是直接通过 asyncio 的 ensure_future 方法,返回结果也是 task 对象,这样的话我们就可以不借助于 loop 来定义,即使还没有声明 loop 也可以提前定义好 task 对象,写法如下:
import asyncio
async def execute(x):
print('Number:', x)
return x
coroutine = execute(666)
print('Coroutine:', coroutine)
print('After calling execute')
task = asyncio.ensure_future(coroutine)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
print('After calling loop')
运行效果如下:
Coroutine: 0x0000019794EBBE48>
After calling execute
Task: 3>>
Number: 666
Task: 3> result=666>
After calling loop
Process finished with exit code 0
发现其运行效果都是一样的
task对象的绑定回调操作
可以为某个 task 绑定一个回调方法,举如下例子:
import asyncio
import requests
async def call_on():
status = requests.get('https://www.baidu.com')
return status
def call_back(task):
print('Status:', task.result())
corountine = call_on()
task = asyncio.ensure_future(corountine)
task.add_done_callback(call_back)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
定义了一个call_on 方法,请求了百度,获取其状态码,但是这个方法里面我们没有任何 print 语句。随后我们定义了一个 call_back 方法,这个方法接收一个参数,是 task 对象,然后调用 print打印了 task 对象的结果。这样我们就定义好了一个 coroutine 对象和一个回调方法,
希望达到的效果是,当 coroutine 对象执行完毕之后,就去执行声明的 callback 方法。实现这样的效果只需要调用 add_done_callback 方法即可,我们将 callback 方法传递给了封装好的 task 对象,这样当 task 执行完毕之后就可以调用 callback 方法了,同时 task 对象还会作为参数传递给 callback 方法,调用 task 对象的 result 方法就可以获取返回结果了。
运行结果如下:
Task: 4> cb=[call_back() at D:/python/pycharm2020/program/test_003.py:8]>
Status: 200]>
Task: 4> result=200]>>
也可以不用回调方法,直接在 task 运行完毕之后也能直接调用 result 方法获取结果,如下所示:
import asyncio
import requests
async def call_on():
status = requests.get('https://www.baidu.com')
return status
def call_back(task):
print('Status:', task.result())
corountine = call_on()
task = asyncio.ensure_future(corountine)
print('Task:', task)
loop = asyncio.get_event_loop()
loop.run_until_complete(task)
print('Task:', task)
print('Task:', task.result())
运行效果一样:
Task: 4>>
Task: 4> result=200]>>
Task: 200]>
三、异步爬虫实现
要实现异步处理,得先要有挂起的操作,当一个任务需要等待 IO 结果的时候,可以挂起当前任务,转而去执行其他任务,这样才能充分利用好资源,要实现异步,需要了解一下 await 的用法,使用 await 可以将耗时等待的操作挂起,让出控制权。当协程执行的时候遇到 await,时间循环就会将本协程挂起,转而去执行别的协程,直到其他的协程挂起或执行完毕。
await 后面的对象必须是如下格式之一:
A native coroutine object returned from a native coroutine function,一个原生 coroutine 对象。 A generator-based coroutine object returned from a function decorated with types.coroutine,一个由 types.coroutine 修饰的生成器,这个生成器可以返回 coroutine 对象。 An object with an await method returning an iterator,一个包含 await 方法的对象返回的一个迭代器。
aiohttp 的使用
aiohttp 是一个支持异步请求的库,利用它和 asyncio 配合我们可以非常方便地实现异步请求操作。下面以访问我博客里面的文章,并返回 reponse.text() 为例,实现异步爬虫。
from lxml import etree
import requests
import logging
import time
import aiohttp
import asyncio
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
url = 'https://blog.csdn.net/fyfugoyfa'
start_time = time.time()
# 先获取博客里的文章链接
def get_urls():
headers = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
url_list = html.xpath('//div[@class="article-list"]/div/h4/a/@href')
return url_list
async def request_page(url):
logging.info('scraping %s', url)
async with aiohttp.ClientSession() as session:
response = await session.get(url)
return await response.text()
def main():
url_list = get_urls()
tasks = [asyncio.ensure_future(request_page(url)) for url in url_list]
loop = asyncio.get_event_loop()
tasks = asyncio.gather(*tasks)
loop.run_until_complete(tasks)
if __name__ == '__main__':
main()
end_time = time.time()
logging.info('total time %s seconds', end_time - start_time)
实例中将请求库由 requests 改成了 aiohttp,通过 aiohttp 的 ClientSession 类的 get 方法进行请求,运行效果如下:
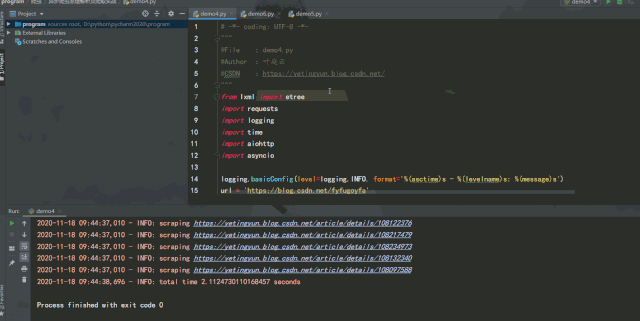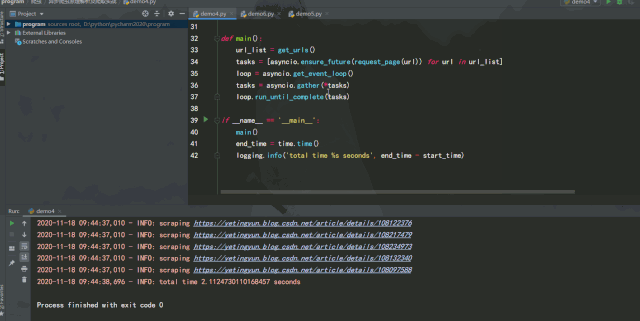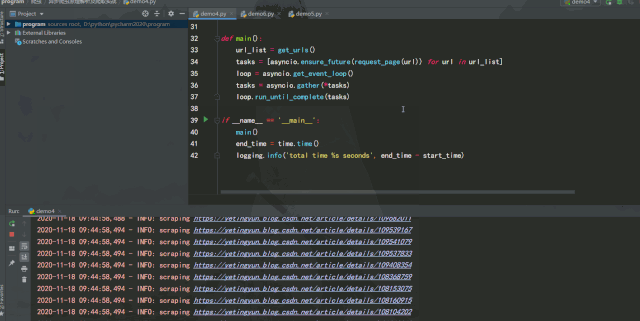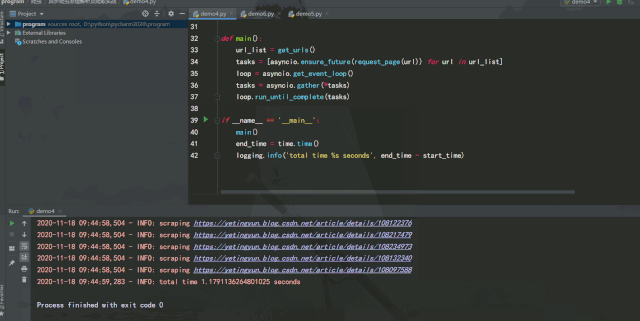
异步操作的便捷之处在于,当遇到阻塞式操作时,任务被挂起,程序接着去执行其他的任务,而不是傻傻地等待,这样可以充分利用 CPU 时间,而不必把时间浪费在等待 IO 上。
上面的例子与单线程版和多线程版的比较如下:
多线程版
import requests
import logging
import time
from lxml import etree
from concurrent.futures import ThreadPoolExecutor
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
url = 'https://blog.csdn.net/fyfugoyfa'
headers = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
start_time = time.time()
# 先获取博客里的文章链接
def get_urls():
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
url_list = html.xpath('//div[@class="article-list"]/div/h4/a/@href')
return url_list
def request_page(url):
logging.info('scraping %s', url)
resp = requests.get(url, headers=headers)
return resp.text
def main():
url_list = get_urls()
with ThreadPoolExecutor(max_workers=6) as executor:
executor.map(request_page, url_list)
if __name__ == '__main__':
main()
end_time = time.time()
logging.info('total time %s seconds', end_time - start_time)
运行效果如下:
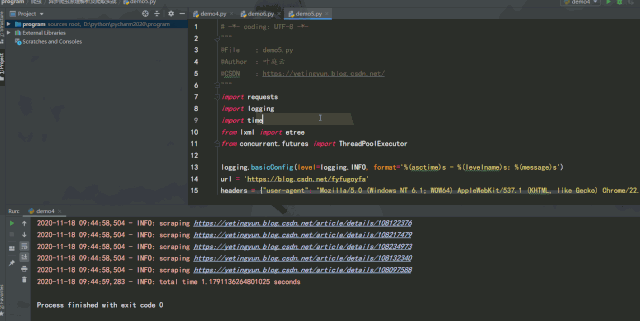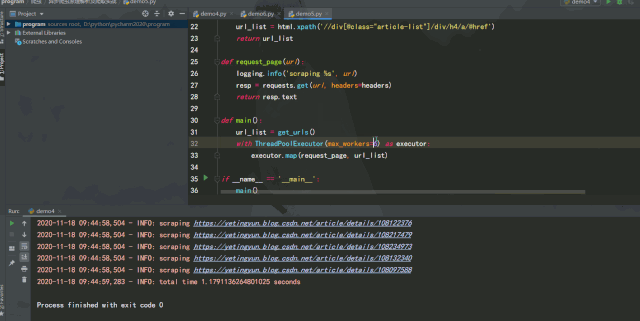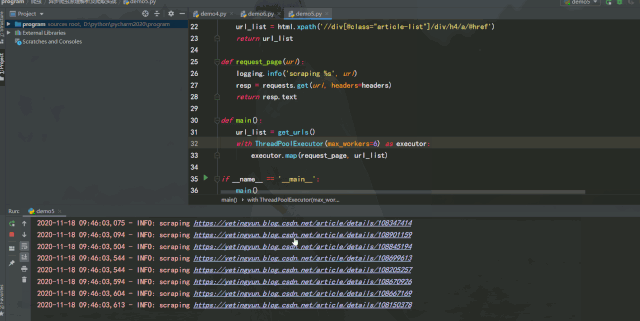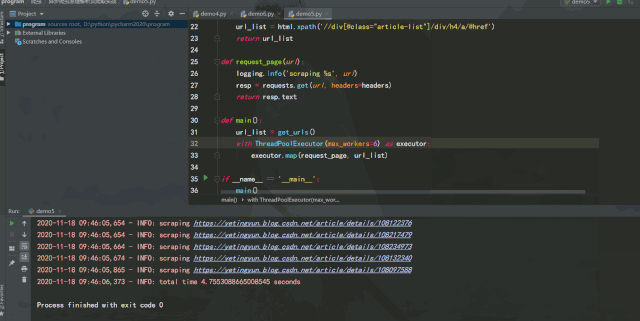
单线程版
import requests
import logging
import time
from lxml import etree
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
url = 'https://blog.csdn.net/fyfugoyfa'
headers = {"user-agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"}
start_time = time.time()
# 先获取博客里的文章链接
def get_urls():
resp = requests.get(url, headers=headers)
html = etree.HTML(resp.text)
url_list = html.xpath('//div[@class="article-list"]/div/h4/a/@href')
return url_list
def request_page(url):
logging.info('scraping %s', url)
resp = requests.get(url, headers=headers)
return resp.text
def main():
url_list = get_urls()
for url in url_list:
request_page(url)
if __name__ == '__main__':
main()
end_time = time.time()
logging.info('total time %s seconds', end_time - start_time)
运行效果如下:
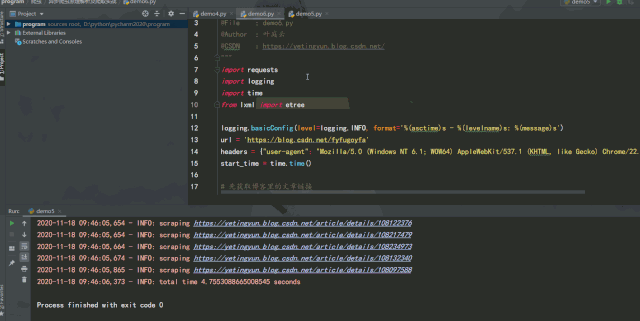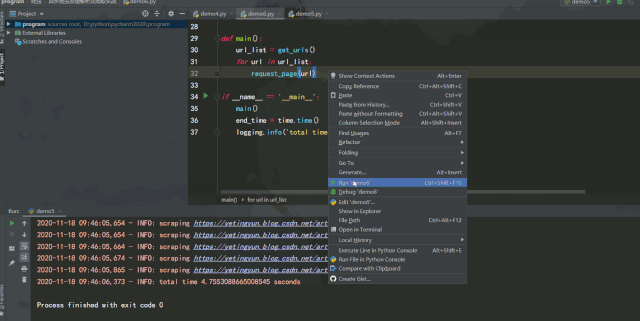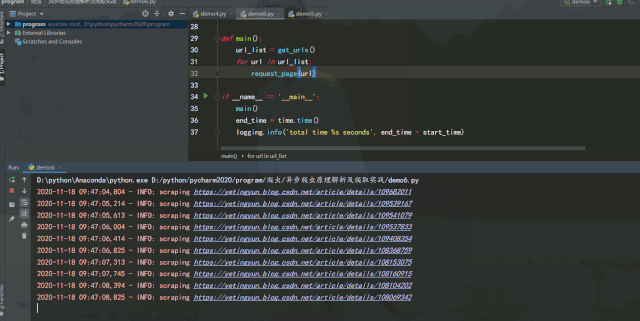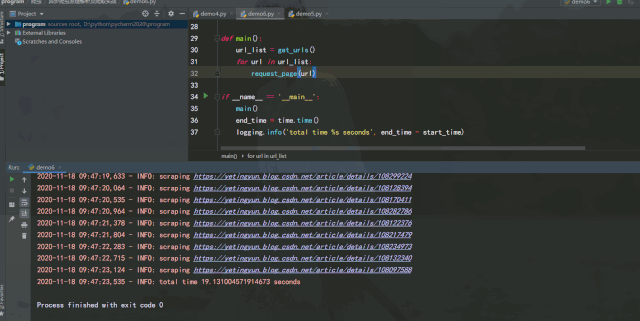
经过测试可以发现,如果能将异步请求灵活运用在爬虫中,在服务器能承受高并发的前提下增加并发数量,爬取效率提升是非常可观的。
作者简介:
叶庭云
个人格言: 热爱可抵岁月漫长
CSDN博客: https://yetingyun.blog.csdn.net
------- End -------
扫码添加早小起,进入Python技术交流群