
【机器学习基础】3 个优秀的模型调优策略
点击关注公众号,干货及时送达
作者:Xiaoyou Wang 转自:机器之心编译
无论是 Kaggle 竞赛还是工业部署,机器学习模型在搭建起来之后都面临着无尽的调优需求。在这个过程中我们要遵循怎样的思路呢?
https://www.mage.ai/blog/definitive-guide-to-accuracy-precision-recall-for-product-developers
https://www.mage.ai/blog/product-developers-guide-to-ml-regression-model-metrics



创建一个功能来计算文本中的字母数。
创建一个功能来计算文本中的单词数。
创建一个理解文本含义的特征(例如词嵌入)。
过去 7 天、30 天或 90 天的聚合用户事件计数。
从日期或时间戳特征中提取「日」、「月」、「年」和「假期后的天数」等特征。

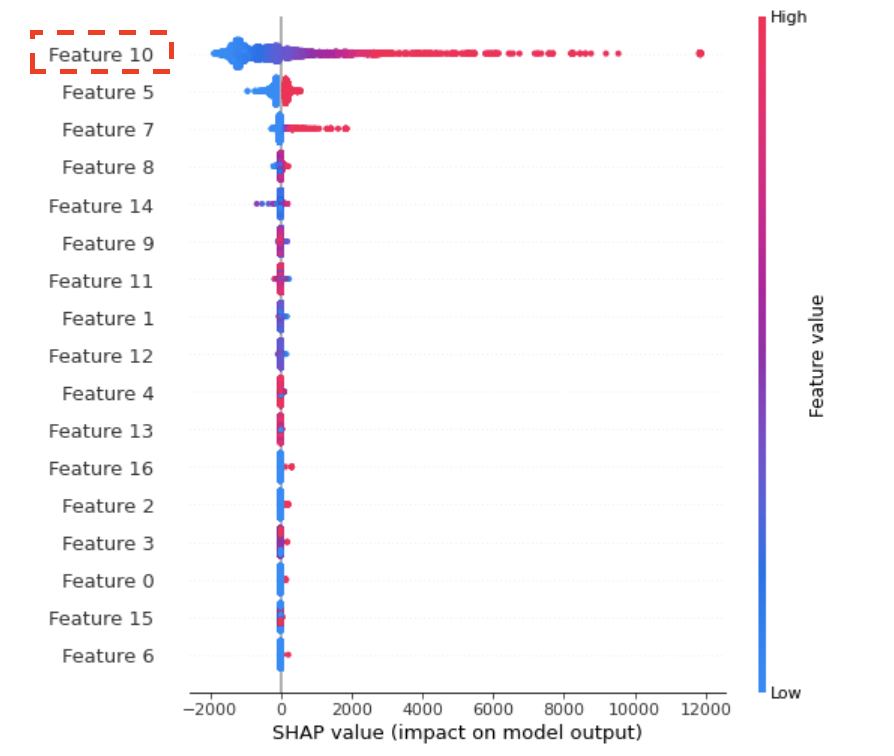

尝试所有改进模型的策略。
将模型性能与你必须验证的其他一些指标进行比较,以验证模型是否有意义。
在进行了几轮模型调整后,评估一下继续修改和性能提升百分点之间的性价比。
如果模型表现良好,并且在尝试了一些想法后几乎没有继续改进,请将模型部署到生产过程中并测量实际性能。
如果真实条件下的性能和测试环境中类似,那你的模型就算可以用了。如果生产性能比训练中的性能差,则说明训练中存在一些问题,这可能是因为过拟合或者数据泄露。这意味着还需要重新调整模型。
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论