
实战:使用 OpenCV 和 PyTesseract 对文档进行OCR
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


随着世界各地的组织都希望将其运营数字化,将物理文档转换为数字格式是非常常见的。这通常通过光学字符识别 (OCR) 完成,其中文本图像(扫描的物理文档)通过几种成熟的文本识别算法之一转换为机器文本。当在干净的背景下处理打印文本时,文档 OCR 的性能最佳,具有一致的段落和字体大小。
在实践中,这种情况远非常态。发票、表格甚至身份证明文件的信息分散在整个文件空间中,这使得以数字方式提取相关数据的任务变得更加复杂。
在本文中,我们将探索一种使用 Python 为 OCR 定义文档图像区域的简单方法。我们将使用信息分散在整个文档空间的文档示例——护照。以下样本护照放置在白色背景中,模拟复印的护照副本。
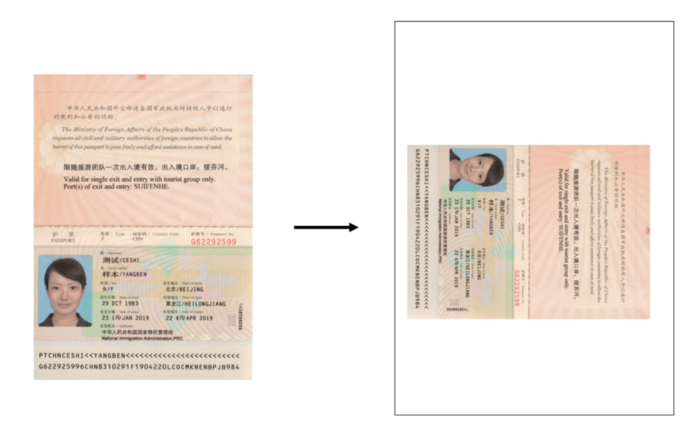
从此护照图像中,我们希望获得以下字段:
名字/名字姓氏中文名汉字的姓氏护照号码
首先,我们将导入所有必需的包。最重要的包是用于计算机视觉操作的OpenCV和PyTesseract,它是强大的 Tesseract OCR 引擎的 Python 包装器。
from cv2 import cv2import pytesseractimport pandas as pdimport numpy as npimport mathfrom matplotlib import pyplot as plt
接下来,我们将使用 cv2.imread 读取我们的护照图像。我们的第一个任务是从这个伪扫描页面中提取实际的护照文件区域。我们将通过检测护照的边缘并将其从图像中裁剪出来来实现这一点。
img = cv2.imread('images\Passport.png',0)img_copy = img.copy()img_canny = cv2.Canny(img_copy, 50, 100, apertureSize = 3)
OpenCV 库中包含的Canny 算法使用多阶段过程来检测图像中的边缘。使用的最后三个参数是较低阈值和较高阈值(分别为 minVal 和 maxVal),以及内核大小。
运行 Canny 算法会产生以下输出。请注意,由于选择了低阈值,因此保留了最少的边缘。

img_hough = cv2.HoughLinesP(img_canny, 1, math.pi / 180, 100, minLineLength = 100, maxLineGap = 10)接下来,我们在边缘检测图像上使用另一种称为霍夫变换的算法,通过检测线绘制出护照区域的形状。minLineLength 参数定义了一个形状必须包含多少像素才能被视为“线”,而 maxLineGap 参数表示像素序列中被视为相同形状的最大允许间隙。
(x, y, w, h) = (np.amin(img_hough, axis = 0)[0,0], np.amin(img_hough, axis = 0)[0,1], np.amax(img_hough, axis = 0)[0,0] - np.amin(img_hough, axis = 0)[0,0], np.amax(img_hough, axis = 0)[0,1] - np.amin(img_hough, axis = 0)[0,1])img_roi = img_copy[y:y+h,x:x+w]
我们的护照四面都是直线——文件的边缘。因此,有了我们的线条信息,我们可以选择通过检测到的线条的外边缘来裁剪我们的护照区域:

将护照竖直旋转后,我们开始在图像中选择要捕获数据的区域。几乎所有国际护照都符合ICAO 标准,该标准概述了护照页的设计和布局规范。这些规范之一是机读区 (MRZ),即护照文件底部有趣的两行。你们的文件的视觉检查区 (VIZ) 中的大部分关键信息也包含在机读区中,机器可以读取这些信息。在我们的练习中,那台机器是我们值得信赖的 Tesseract 引擎。
img_roi = cv2.rotate(img_roi, cv2.ROTATE_90_COUNTERCLOCKWISE)(height, width) = img_roi.shapeimg_roi_copy = img_roi.copy()dim_mrz = (x, y, w, h) = (1, round(height*0.9), width-3, round(height-(height*0.9))-2)img_roi_copy = cv2.rectangle(img_roi_copy, (x, y), (x + w ,y + h),(0,0,0),2)
让我们使用四个维度定义护照图像中的 MRZ 区域:水平偏移(从左侧)、垂直偏移(从顶部)、宽度和高度。对于 MRZ,我们将假设它包含在我们护照的底部 10% 内。因此,使用 OpenCV 的矩形函数,我们可以在区域周围绘制一个框来验证我们的尺寸选择。

img_mrz = img_roi[y:y+h, x:x+w]img_mrz =cv2.GaussianBlur(img_mrz, (3,3), 0)ret, img_mrz = cv2.threshold(img_mrz,127,255,cv2.THRESH_TOZERO)
在新图像中裁剪所选区域。我们将对裁剪后的图像进行一些基本的图像预处理,以促进更好的读出——高斯模糊和简单阈值。

mrz = pytesseract.image_to_string(img_mrz, config = '--psm 12')我们现在准备应用 OCR 处理。在我们的 image_to_string 属性中,我们配置了“带有方向和脚本检测(OSD)的稀疏文本”的页面分割方法。这旨在捕获我们图像中的所有可用文本。

将 Pytesseract 输出与我们的原始护照图像进行比较,我们可以观察到读取特殊字符时的一些错误。为了获得更准确的读数,可以使用 Pytesseract 的白名单配置进行优化;然而就我们的目的而言,电流读数的准确性就足够了。
mrz = [line for line in mrz.split('\n') if len(line)>10]if mrz[0][0:2] == 'P<':lastname = mrz[0].split('<')[1][3:]else:lastname = mrz[0].split('<')[0][5:]firstname = [i for i in mrz[0].split('<') if (i).isspace() == 0 and len(i) > 0][1]pp_no = mrz[1][:9]
根据 ICAO 关于 MRZ 代码结构的指导原则应用一些字符串操作,我们可以提取护照持有人的姓氏、名字和护照号码:

不是英文的文本怎么办?没问题——Tesseract 引擎已经为100 多种语言训练了模型(尽管每种支持的语言的 OCR 性能的稳健性不同)。
img_roi_copy = img_roi.copy()dim_lastname_chi = (x, y, w, h) = (455, 1210, 120, 70)img_lastname_chi = img_roi[y:y+h, x:x+w]img_lastname_chi = cv2.GaussianBlur(img_lastname_chi, (3,3), 0)ret, img_lastname_chi = cv2.threshold(img_lastname_chi,127,255,cv2.THRESH_TOZERO)dim_firstname_chi = (x, y, w, h) = (455, 1300, 120, 70)img_firstname_chi = img_roi[y:y+h, x:x+w]img_firstname_chi = cv2.GaussianBlur(img_firstname_chi, (3,3), 0)ret, img_firstname_chi = cv2.threshold(img_firstname_chi,127,255,cv2.THRESH_TOZERO)
使用相同的区域选择方法,我们再次为目标数据字段定义维度(x、y、w、h),并对裁剪后的图像提取应用模糊和阈值处理。

lastname_chi = pytesseract.image_to_string(img_lastname_chi, lang = 'chi_sim', config = '--psm 7')firstname_chi = pytesseract.image_to_string(img_firstname_chi, lang = 'chi_sim', config = '--psm 7')
现在,在我们的 image_to_string 参数中,我们将添加输入文本的语言脚本,简体中文。

要完成练习,请将所有收集的字段传递给字典并输出到表格以供实际使用。

OCR 感兴趣区域的显式定义只是在OCR 中获取所需数据的众多方法之一。根据你们的用例,使用其他方法(例如轮廓分析或对象检测)可能最有效,正如我们的护照练习所示,在应用 OCR 之前对图像进行适当的预处理是关键。在处理具有不同图像质量的真实文档时,尝试不同的预处理技术以找到最适合你们的文档类型的方法非常重要。
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~