
最新的NLP开源神器来了!

PaddleNLP 是兼具科研学习和产业实践能力的 Python NLP 工具包,提供中文领域丰富的预训练模型和部署工具,被高校、企业开发者广泛应用。近日,PaddleNLP v2.1正式发布,为开发者带来三项重要更新:
开箱即用的产业级NLP预置任务能力Taskflow:八大经典场景一键预测。
预训练时代的微调新范式应用:三行代码显著提升小样本学习效果。 高性能预测加速:文本生成任务28倍加速效果。

PaddleNLP整体开源
能力速览
PaddleNLP是飞桨生态的自然语言处理开发库,旨在提升文本领域的开发效率,为开发者带来模型构建、训练及预测部署的全流程优质体验。

PaddleNLP功能全景图
PaddleNLP项目自发布以来,就受到广大NLPer的关注。在2021年6月PaddleNLP官方直播打卡课中,有7000+ 用户参加PaddleNLP的项目学习和实践,加速了自身科研和业务实践进程,同时也带动PaddleNLP多次登上GitHub Trending榜单。
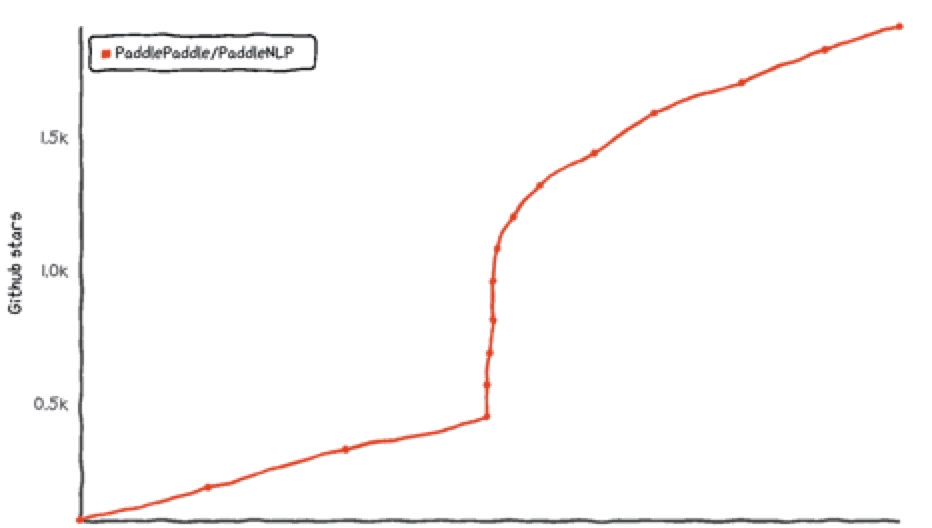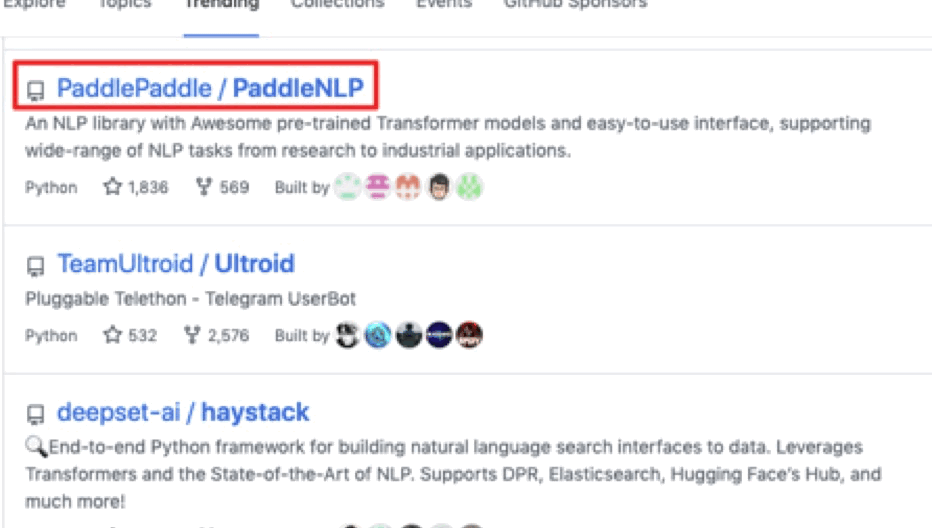


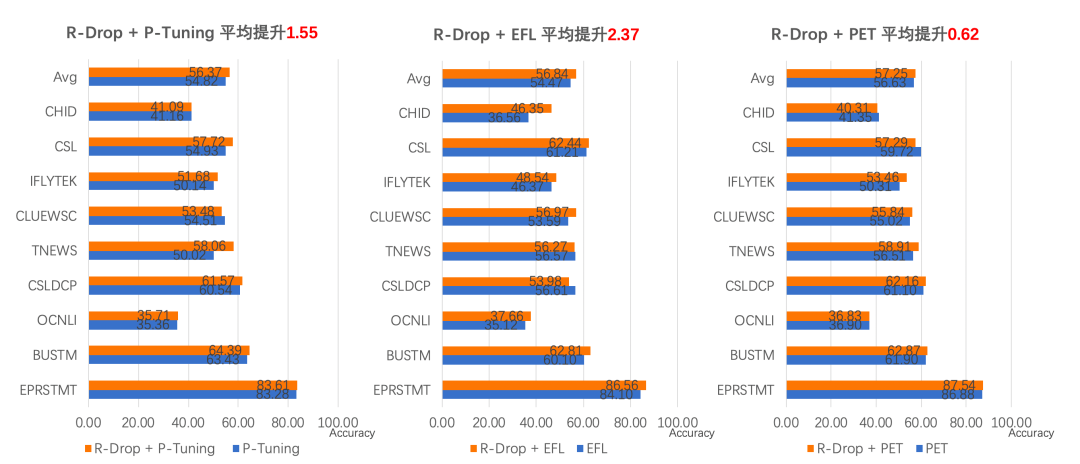
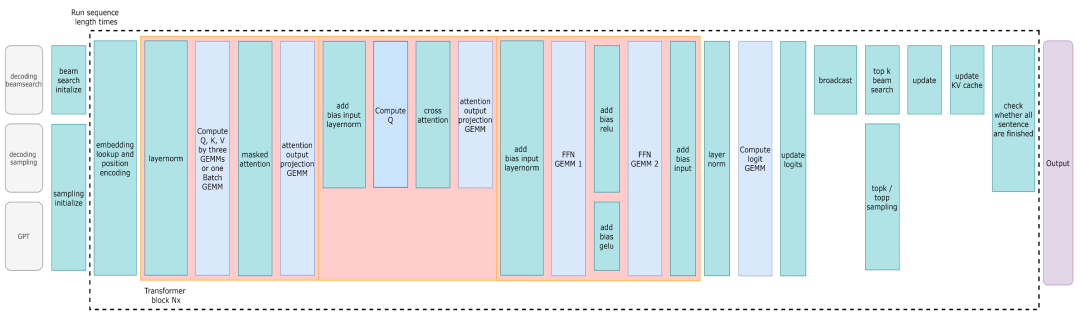
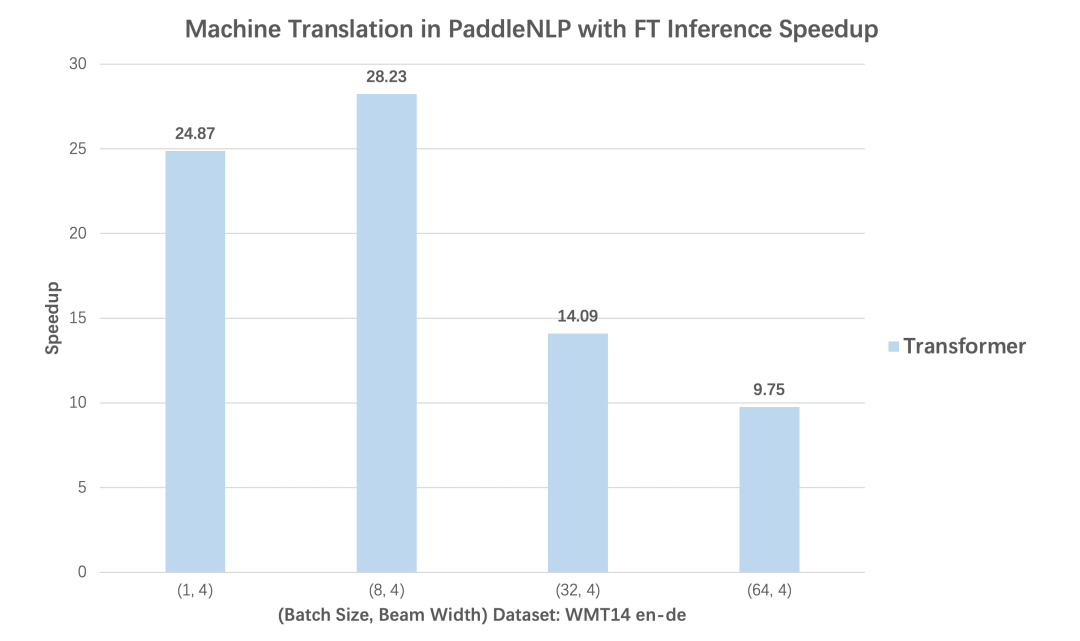
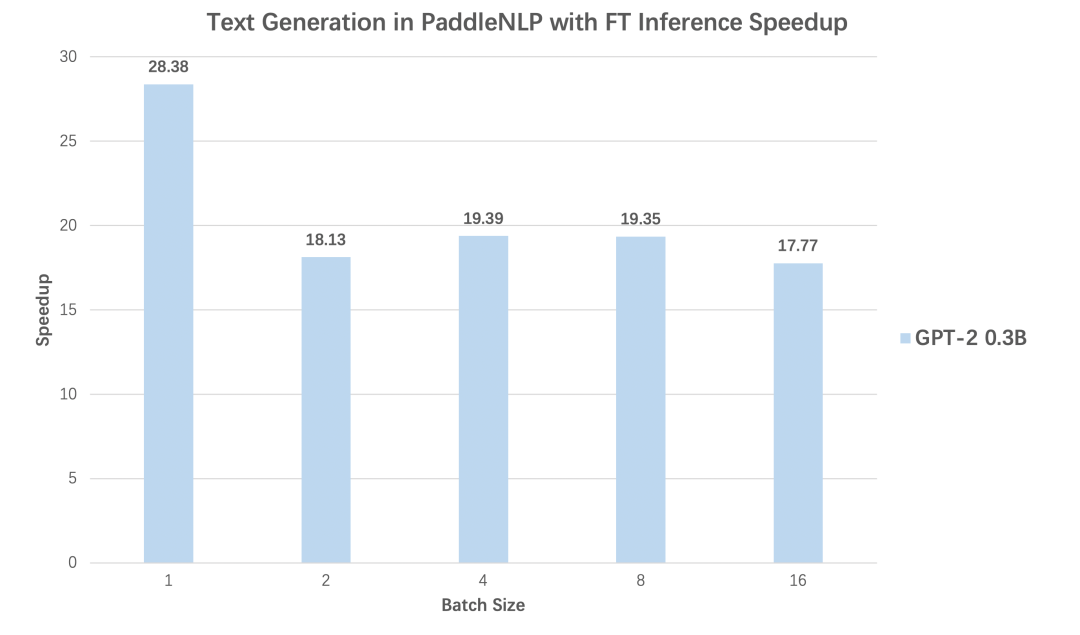


表1:PaddleNLP 2.1 支持加速的模型结构与解码策略



官网地址:https://www.paddlepaddle.org.cn
评论