
半导体芯片:NVIDIA、AMD和Intel三雄逐鹿全球


赛灵思近年布局的自适应计算加速平台ACAP以FPGA+AI 引擎的方式实现异构加速。两家公司在深度学习项目均有合作,包括赛灵思Alveo 加速技术+AMD EPYC 服务器的协同方案;此外赛灵思收购深鉴科技获得的深度学习处理器DPU 方案也能赋能AMD 在云和边缘计算的AI 计算实力,与英伟达进一步抗衡。
FPGA 可在系统制造完成后依据期望的功能进行重新编程,具备配置灵活、设计时间短、物料成本低的优点。它是作为专用集成电路(ASIC)领域中的一种半定制电路而出现的,既能解决了定制电路的不足,又能克服了原有可编程器件门电路数有限的缺点。FPGA 的基本特点包括:
1、采用FPGA 设计ASIC 电路,用户不需要投片生产,就能得到合用的芯片;
2、FPGA 可做其它全定制或半定制 ASIC 电路的中试样片;
3、FPGA内部有丰富的触发器和 I/O 引脚;
4、FPGA 是 ASIC 电路中设计周期最短、开发费用最低、 风险最小的器件之一;
5、FPGA 采用高速 CMOS 工艺,功耗低,可以与 CMOS、TTL 电平兼容。
可以说,FPGA 芯片是小批量系统用来提高系统集成度、可靠性的最佳选择之一。FPGA 是由存放在片内 RAM 中的程序来设置其工作状态的,因此工作时需要对片内的 RAM 进 行编程。用户可以根据不同的配置模式,采用不同的编程方式。
英伟达今年刚完成跟Mellanox 的并表,以强化高性能计算壁垒,触及数据中心通信传输和处理领域。英伟达数据中心业务在今年重拾动力,2016 年以来,AI 云端训练需求虽已达到更新迭代的周期,但新AI 应用才是需求放量的关键。未来AI 将应用于医药、金融和无人驾驶等方面,需求正在爆发。近日更推出DPU(数据处理器),把Arm 处理器核、VLIW 矢量计算引擎和智能网卡进行集成,提升在分布式存储、网络计算和网络安全领域的性能。
英伟达早前提出以400 亿美元收购移动处理器巨头Arm,希望加入CPU 以扩大在GPU 以外的版图,但能否收入囊中仍存疑。若能成功收购Arm,英伟达不但能巩固移动端的产品线,也能打造一套完整的GPU+Arm 的服务器计算架构。我们认为这架构有望成为低端x86 CPU 服务器市场的新进者。然而,我们认为有两个问题需要关注:
1)Arm 先天架构劣势导致其在高性能计算市场尚无成功方案,计算生态也暂时难以与英特尔/AMD 的x86 CPU服务器相匹敌。
2)行业对于英伟达并购Arm 存在异议,而有关监管机构亦或会对收购施加压力。
英特尔也在经历了管理层变革后展现出相对锐意改革的决心,我们认为公司继续重点打造CPU+FPGA+存储+GPU 的完整计算生态,还是能受益于全球云计算需求成长周期。目前来看,英特尔依托其庞大的产品组合可及市场,仍然是云计算、AI、5G、智能驾驶、物联网等市场发展的锚。另外从估值层面看,英特尔2021 年PS 3x,对比英伟达19x、AMD 9x,叠加返现,估值也相对较低。
赛灵思的产品矩阵由三类基于FPGA 的平台产品构成:传统的FPGA 及3D IC 产品;全可编程的SoC、MPSoC、和RFSoC 系列产品以及2019 下半年推出的自适应计算平台ACAP 产品。三类平台产品均随着纳米制程的不断缩小(45nm、28nm、20nm、16nm 到7nm)进行升级,公司的技术演进也一直走在行业前列。
2013 年-2014 年,赛灵思在突破20nm 工艺节点的基础上,发布业内首款ASIC 级可编程架构UltraScale,不仅标志着Xilinx 再次从纳米制程上实现突破,也标志着赛灵思不再局限于以前的FPGA 行业,而是面向更广阔的PLD+ASIC 市场。
2015-2016 年,赛灵思在UltraScale 架构上完成20nm 平面晶体管结构工艺向16nm晶体管工艺的技术扩展,还推出了第二代Zynq 全可编程SoC——Zynq UltraScale+多处理SoC (MPSoC)。该产品采用了16nm FinFET+工艺技术,异构多核处理的MPSoC 标志着赛灵思SoC 系列产品再次完成重大技术演进。
2017 年,赛灵思推出第三代Zynq 全可编程SoC——Zynq UltraScale+ RFSoC,通过将直接RF 采样技术取代分立数据转换器,并将稳定可靠的Arm 级处理系统以及FPGA架构整合到单芯片器件中,在集成度方面实现重大突破,削减了50-75%的功耗和封装尺寸。通过 Zynq UltraScale+ RFSoC,无线基础设施制造商可实现显著的占板面积及功耗减少,为5G 建设中大规模部署MIMO 提供重要保障;同时作为面向可扩展、多功能、相控阵雷达的单芯片TRX 解决方案,Zynq UltraScale+ RFSoC 也能够满足军工应用场景下复杂的需求并实现高效的响应。
2018 年,赛灵思采用最新的7nm FinFET 工艺技术,在RFSoC 的基础上演进出业界首款自适应计算加速平台(ACAP)Versal,将标量引擎、自适应引擎和AI 引擎相结合,实现显著的性能提升,主要面向数据中心、有线网络、5G 无线和汽车驾驶辅助应用,并在2019 下半年正式出货。此后赛灵思进一步扩充Versal ACAP 产品组合,先后发布了Versal AI Core、Versal Prime 和Versal Premium 系列,针对超大规模数据中心工作负载加速。

目前,赛灵思将28nm、20nm、16nm、7nm 等制程产品归类为先进产品,其他制程的产品归类为核心产品,先进产品的销售稳步增长。
赛灵思若能并入 AMD,对于AMD的AI 数据中心业务来说将会是如虎添翼。以往AMD在数据中心市场主要以服务器CPU 为主营业务,而GPU 方面也主要应用于图像处理,在AI 加速计算市场目前尚难与英伟达正面交锋。如若合并后AMD 有望能抢占云计算数据中心以及 AI 推理端份额,有效形成协同效应,也让 AMD 产品线可进一步跟 Intel 和英伟达看齐。
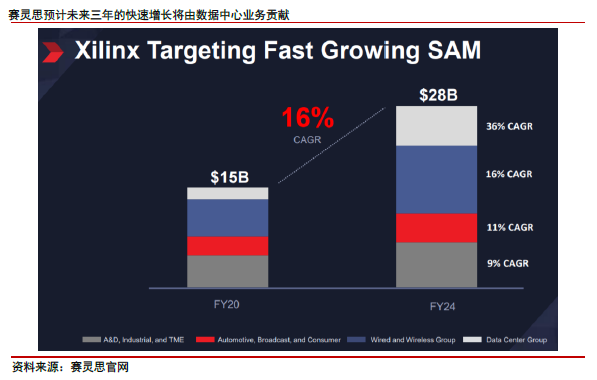
赛灵思预计,未来三年公司整体市场规模空间的CAGR 增长将达到16%,从2020财年的150 亿美元到2024 财年的280 亿美元。
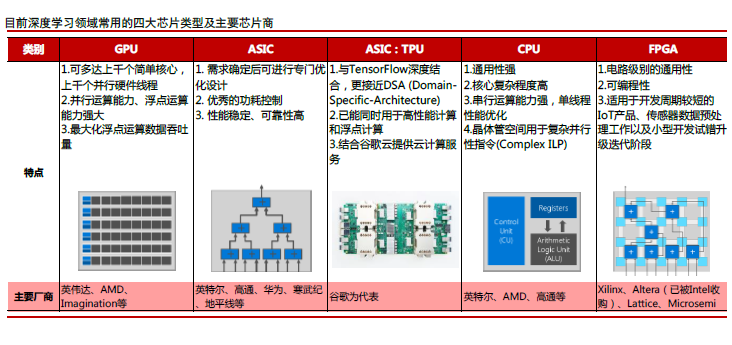
在云计算深度学习上游训练端,GPU是当仁不让的第一选择,但以 ASIC 为底芯片的包括谷歌的 TPU、寒武纪的 MLU 等,也如雨后春笋。以 TPU 为代表的 ASIC 定制化芯片,针对特定算法深度优化和加速。我们认为深度学习 ASIC 芯片,将依靠特定优化和效能优势,未来在细分市场领域发挥所长。而下游推理端更接近终端应用,需求更加细分。逐步形成 GPU 向推理端渗透,与 ASIC 和 FPGA 共同繁荣发展的格局。
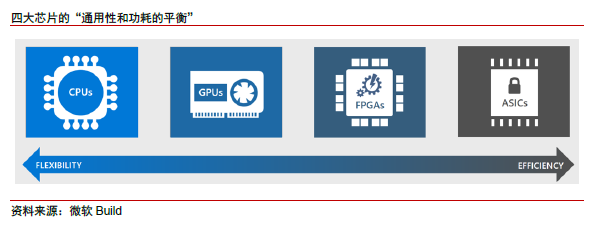
此外,FPGA 依靠电路级别的通用性,加上可编程性,适用于开发周期较短的 IoT 产品、传感器数据预处理工作,以及小型开发试错升级迭代阶段等。
在自动驾驶行业中,赛灵思目前主要定位在 ADAS 层面,车载前置摄像头处理单元出货量仅次于Mobileye。虽然 2018 年全球无人驾驶行业出现阵痛期,但 2020 年的全球疫情一定程度上催化了智能驾驶行业的发展。而随着 L3 以下智能驾驶需求的加速渗透,也有望在未来为赛灵思带来新的成长空间。
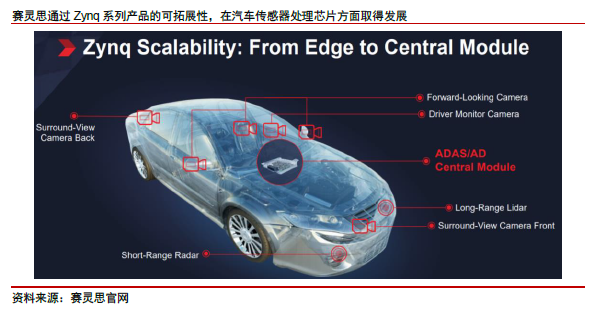
2020 年 9 月,赛灵思宣布将通过 Zynq UltraScale+ MPSoC 平台支持大陆开发新款高级雷达传感器(ARS)540,联手打造汽车行业首款量产版 4D 成像传感器。4D 成像雷达能够通过距离(Range)、方位(Azimuth)、仰角(Elevation)和相对速度确定物体位置, 助力 L2 到 L5 等级功能。赛灵思的 Zynq MPSoC 可达到车规级,为 4D 雷达提供 DSP功能、网络接口和天线数据处理能力。Yole Dévelopement 预测 4D 雷达将首先出现在豪华轿车和自动驾驶出租车上,市场规模将达到 5.5 亿美元。
英伟达在AI 训练端基本占垄断地位,有赖于自身强劲的计算能力。而推理端则更重视低功耗和低延迟,对算力的要求虽然较低,但 GPU 的高适应性则体现在它的通用性和可编程性。在市场蛋糕变大的同时,逐步形成 GPU 向推理端渗透,与 ASIC 和 FPGA 共同繁荣发展的格局。
另外,英伟达通过收购 Mellanox 触及数据中心通信传输和处理领域。近日更推出DPU(Data Processing Unit,数据处理器),把 Arm 处理器核、VLIW 矢量计算引擎和智能网卡进行集成,提升在分布式存储、网络计算和网络安全领域的性能。
Mellanox 在数据中心服务器方面的核心产品InfiniBand 网络互联,用于数据中心、超级计算机的数据传输和网络互联,包括与微软数据中心的合作方案中,将网络堆栈处理从CPU 卸载到网络,成为面向数据库处理、人工智能机器学习等高存储需求工作负载的最佳解决方案。InfiniBand凭借其低延迟和高吞吐量互联特性,在高性能计算HPC 市场成为网络标准,目前这个市场主要供应商为Mellanox 和英特尔。此前传出包括微软、英特尔、赛灵思的竞购,体现了公司在数据中心服务器市场中的战略卡位地位,也让英伟达有机会打造“计算+传输”产品闭环。
InfiniBand 具有低延迟、高吞吐量的特点,近两年TOP10 高性能计算机用户有60-70%装载InfiniBand,对比英特尔Omini-Path 的10%。基于这两条产品线之上的Mellanox ConnectX-6 Dx 智能网卡可增强系统安全性并降低延迟,在边缘提供更加安全的实时AI处理。FY21Q2 起Mellanox 开始计入英伟达财报,5 月英伟达发布7nm 的Ampere 新架构GPU,性能提升20 倍。当季性能计算芯片和网络连接贡献收入创下历史新高,数据中心业务收入同比提升167%、环比增长54%。
英伟达近日发布的BlueField DPU 系列便是基于Mellanox 的产品,通过以数据为中心、数据处理与传输同时进行的模式,希望能代替原有的以计算单元为中心、数据处理滞后于数据传输的过时范例,从而减轻CPU和GPU的运行负担,实现整体计算性能的优化。

BlueField 2 搭载8 颗64bit 的Arm A72 CPU 内核,2 VLIM 加速器和Connect X6 Dx智能网卡,可以提供双端口最高100Gps 和单端口200Gps 的网络连接。BlueField 可以快速有效地捕获、分析、分类、管理和存储海量数据,实现RDMA/RoCE、DPUDirect、弹性存储、分块存储加密和恶意外部应用自动检测等功能,从而实现单颗DPU 芯片对125个CPU 内核的释放。BlueField 2X 在此基础上集成了5 月新发布的7 nm 级Ampere 架构GPU 和第三代Tensor 内核,可通过AI 加速数据中心的安全、网络连接、数据存储等任务。

此外,英伟达还发布了面向开发者的平台DOCA SDK,通过集成Ampere GPU 和BlueField2 DPU 优化EGX AI 平台,向流媒体、智能驾驶、医疗等终端场景扩展。BlueField 2 DPU目前处于样品阶段,预计2021 年将在服务器制造商的新系统中使用。BlueField 2X DPU正在开发中,预计将在2021年上市。
英伟达预计BlueField 3 和BlueField 4 将于22/23年发布,预计性能可提升1000 倍,达到75/400TOPS,400Gbps,吞吐量有望较BlueField2提升1000 倍。英伟达希望凭借GPU 和Mellanox 智能网卡技术壁垒的协同效应,再辅以Arm 处理器整合协同后的性能提升,有望进一步抗衡英特尔/AMD 的x86 CPU 体系。
英特尔坚定以“数据导向”为战略,重新上路聚焦主营。英特尔早在2015 年已收购了FPGA 行业第二的Altera,在2017 年收购ADAS 龙头Mobileye,以扩大自身在人工智能和数据中心的版图。值得注意的是,若AMD 完成对赛灵思收购,市场上只剩下Microchip和莱迪斯两家FPGA 公司。此外近日SK 海力士宣布将以90 亿美元收购英特尔NAND 闪存及存储业务,也让英特尔能更为聚焦主营业务。
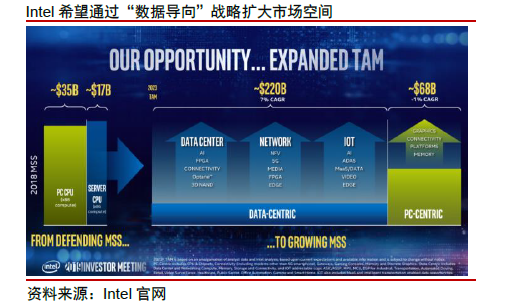
Intel 虽然计划今年投资150 亿美元和扩建晶圆厂,但关键在于公司能否跟上台积电的先进制程脚步。对于先进产能的追求变成负担,以及是否将7nm 产能外包给台积电的犹豫反复,都可能让英特尔在高性能计算竞争中日渐式微。
参考文献:中信证券 半导体产业的三分天下:英伟达、AMD、英特尔
电子书<服务器基础知识全解(终极版)>更新完毕,知识点深度讲解,提供182页完整版下载。
获取方式:点击“阅读原文”即可查看详情,提供PPT可编辑版本和PDF阅读版本。
温馨提示:
请搜索“AI_Architect”或“扫码”关注公众号实时掌握深度技术分享,点击“阅读原文”获取更多原创技术干货。
