
数学推导+纯Python实现机器学习算法22:EM算法
Python机器学习算法实现
Author:louwill
Machine Learning Lab
从本篇开始,整个机器学习系列还剩下最后三篇涉及导概率模型的文章,分别是EM算法、CRF条件随机场和HMM隐马尔科夫模型。本文主要讲解一下EM(Expection maximization),即期望最大化算法。EM算法是一种用于包含隐变量概率模型参数的极大似然估计方法,所以本文从极大似然方法说起,然后推广到EM算法。
极大似然估计
统计学专业的朋友对于极大似然估计一定是很熟悉了。极大似然是一种统计参数估计方法,对于某个随机样本满足某种概率分布,但其中的统计参数未知,我们通过若干次试验结果来估计参数的值的方法。
举个例子来说。比如说我们想了解一下某校学生的身高分布。我们先假设该校学生身高服从一个正态分布,其中的分布参数和未知。全校大几万的学生,我们要一个个去实测肯定不现实。所以我们决定用统计抽样的方法,随机选取100名学生来看一下身高。
要通过这100人的身高来估算全校学生的身高,我们需要明确下面几个问题。第一个就是抽到这100人的概率是多少,因为每个人的选取都是独立的,所以选到这100人的概率可以表示为单个概率的乘积:
上式即为似然函数。通常为了计算方便,我们会对似然函数取对数:
第二个问题在于我们要解释一下为什么能够刚好抽到这100人。所以按照极大似然估计的理论,在学校这么多人中,我们恰好抽到这100人而不是另外的100人,正是因为这100人出现的概率极大,即其对应的似然函数极大:
第三个问题在于如何求解。这个好办,直接对求其参数的偏导数并令为0即可。
所以极大似然估计法可以看作由抽样结果对条件的反推,即已知某个参数能使这些样本出现的概率极大,我们就直接把该参数作为参数估计的真实值。
EM算法引入
上述基于全校学生身高服从一个分布的假设过于笼统,实际上该校男女生的身高分布是不一样的。其中男生的身高分布为,女生的身高分布为。现在我们估计该校学生的分布,就不能简单的一刀切了。
你可以说我们分别抽选50个男生和50个女生,对其分开进行估计。但大多数情况下,我们并不知道抽样得到的这个样本是来自于男生还是女生。如果说学生的身高的观测变量(Observable Variable),那么样本性别就是一种隐变量(Hidden Variable)。
在这种情况下,我们需要估计的问题包括两个:一个是这个样本是男的还是女的,二是男生和女生对应身高的正态分布参数分别是多少。这种情况下常规的极大似然估计就不太好使了,要估计男女身高分布,那必须先估计该学生是男还是女,反过来要估计该学生是男还是女,又得从身高来判断(男生身高相对较高,女生身高相对较矮)。但二者相互依赖,直接用极大似然估计没法算。
针对这种包含隐变量的参数估计问题,一般使用EM算法来进行求解。针对上述身高估计问题,EM算法的求解思想认为:既然两个问题相互依赖,肯定是一个动态求解过程。不如我们直接给定男生女生身高的分布初始值,根据初始值估计每个样本是男还是女的概率(E步),然后据此使用极大似然估计男女生的身高分布参数(M步),之后动态迭代调整直到满足终止条件为止。
EM算法
所以EM算法的应用场景就是要解决包含隐变量的概率模型参数估计问题。给定观测变量数据,隐变量数据,联合概率分布以及关于隐变量的条件分布,使用EM算法对模型参数进行估计流程如下:
- 初始化模型参数,进行迭代:
- E步:记为第次迭代参数的估计值,在第次迭代的E步,计算函数:
其中为给定观测数据和当前参数估计下隐变量数据的条件概率分布; - M步:求使函数最大化的参数,确定第次迭代的参数估计值:
- 重复迭代E步和M步直至收敛。
由EM算法过程我们可以看到,其关键在于E步要确定函数,E步在固定模型参数的情况下来估计隐变量分布,而M步则是固定隐变量来估计模型参数。二者交互进行,直至满足算法收敛条件。
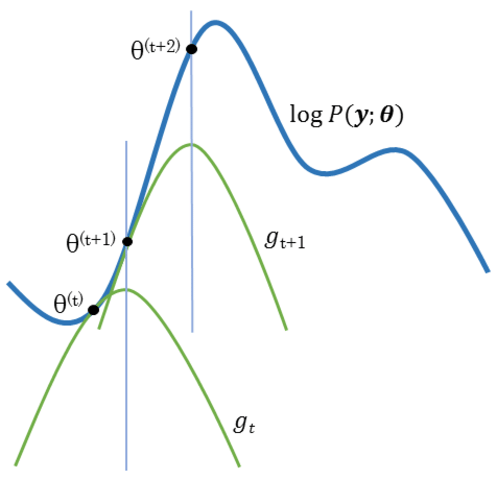
三硬币模型
EM算法的一个经典例子是三硬币模型。假设有A,B,C三枚硬币,其出现正面的概率分别为,和。使用三枚硬币进行如下试验:先抛掷硬币A,根据其结果来选择硬币B或者C,假设正面选B,反面选C,然后记录硬币结果,正面记为1,反面记为0,独立重复5次试验,每次试验重复抛掷B或者C10次。问如何估计三枚硬币分别出现正面的概率。
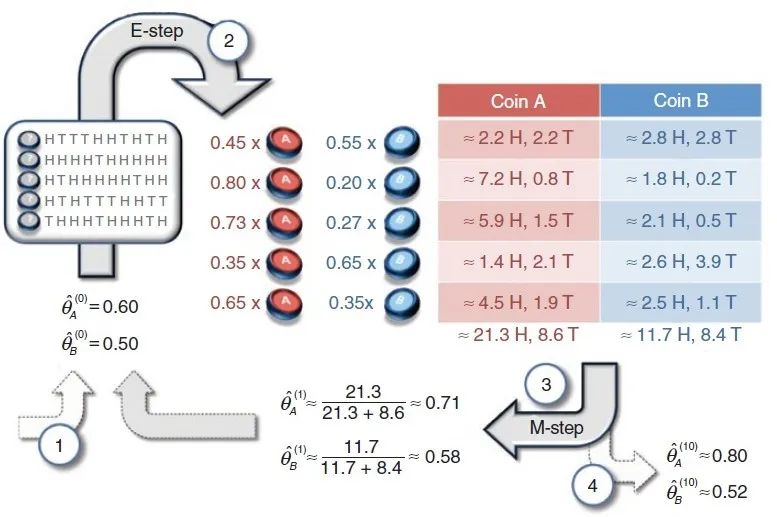
三硬币模型
由于我们只能观察到最后的抛掷结果,至于这个结果是由硬币A抛出来的还是由硬币B抛出来的,我们无从知晓。所以这个过程中依概率选择哪一个硬币抛掷就是一个隐变量。因此我们需要使用EM算法来进行求解。
E步:初始化B和C出现正面的概率为和,估计每次试验中选择B还是C的概率(即硬币A是正面还是反面的概率),例如选择B的概率为:
相应的选择C的概率为。计算出每次试验选择B和C的概率,然后根据试验数据进行加权求和。
M步:更新模型参数的新估计值。根据函数求导来确定参数值:
对上式求导并令为0可得第一次迭代后的参数值:,然后重复进行第二轮、第三轮...直至模型收敛。
EM算法简易实现
下面我们用numpy来实现一个简单的EM算法过程来求解三硬币问题。完整代码如下:
import numpy as npdef em(data, thetas, max_iter=50, eps=1e-3):'''data:观测数据thetas:估计参数max_iter:最大迭代次数eps:收敛阈值'''# 初始化似然函数值ll_old = -np.inftyfor i in range(max_iter):### E步:求隐变量分布# 对数似然log_like = np.array([np.sum(data * np.log(theta), axis=1) for theta in thetas])# 似然like = np.exp(log_like)# 求隐变量分布ws = like/like.sum(0)# 概率加权vs = np.array([w[:, None] * data for w in ws])### M步:更新参数值thetas = np.array([v.sum(0)/v.sum() for v in vs])# 更新似然函数ll_new = np.sum([w*l for w, l in zip(ws, log_like)])print("Iteration: %d" % (i+1))print("theta_B = %.2f, theta_C = %.2f, ll = %.2f"% (thetas[0,0], thetas[1,0], ll_new))# 满足迭代条件即退出迭代if np.abs(ll_new - ll_old) < eps:breakll_old = ll_newreturn thetas
基于我们编写的EM算法函数来对三硬币问题进行求解:
# 观测数据,5次独立试验,每次试验10次抛掷的正反次数# 比如第一次试验为5次正面5次反面observed_data = np.array([(5,5), (9,1), (8,2), (4,6), (7,3)])# 初始化参数值,即硬币B的正面概率为0.6,硬币C的正面概率为0.5thetas = np.array([[0.6, 0.4], [0.5, 0.5]])eps = 0.01max_iter = 50thetas = em(observed_data, thetas, max_iter=50, eps=1e-3)
迭代过程如下:
Iteration: 1theta_B = 0.71, theta_C = 0.58, ll = -32.69Iteration: 2theta_B = 0.75, theta_C = 0.57, ll = -31.26Iteration: 3theta_B = 0.77, theta_C = 0.55, ll = -30.76Iteration: 4theta_B = 0.78, theta_C = 0.53, ll = -30.33Iteration: 5theta_B = 0.79, theta_C = 0.53, ll = -30.07Iteration: 6theta_B = 0.79, theta_C = 0.52, ll = -29.95Iteration: 7theta_B = 0.80, theta_C = 0.52, ll = -29.90Iteration: 8theta_B = 0.80, theta_C = 0.52, ll = -29.88Iteration: 9theta_B = 0.80, theta_C = 0.52, ll = -29.87Iteration: 10theta_B = 0.80, theta_C = 0.52, ll = -29.87Iteration: 11theta_B = 0.80, theta_C = 0.52, ll = -29.87Iteration: 12theta_B = 0.80, theta_C = 0.52, ll = -29.87
可以看到,算法在第七次时达到收敛,最后硬币B和C的正面概率分别为0.8和0.52。
关于EM算法,本文没有太多深入的解释,关于似然函数下界的推导,EM算法的多种解释等,感兴趣的朋友可以自行查找资料学习。
参考资料:
李航 统计学习方法 第二版
https://zhuanlan.zhihu.com/p/36331115
往期精彩:
一个算法工程师的成长之路

长按二维码.关注机器学习实验室
喜欢您就点个在看!
