
最详细的 Python 结合 RFM 模型实现用户分层实操案例!

作者:Cherich_sun
链接:https://www.jianshu.com/p/f020dfdce58d
本文为读者投稿
写在最前:做数据分析的小伙伴可能多多少少都知道一些分析方法,但是谈到分析思维却没有底气或者遇到业务问题,不知道如何下手。如果你有上述困惑,那么本篇文章可以作为参考。下图是整理的分析方法论及方法。如果能够灵活运用,将能够解决工作中 80% 以上问题。注意的是,方法论是思维层面,方法是执行层面。那么,重点是我们如何将其应用到实际业务中。本文将以 RFM 模型 为例,运用到实际案例中。(本文以 Python 实现,Excel 也可以。)
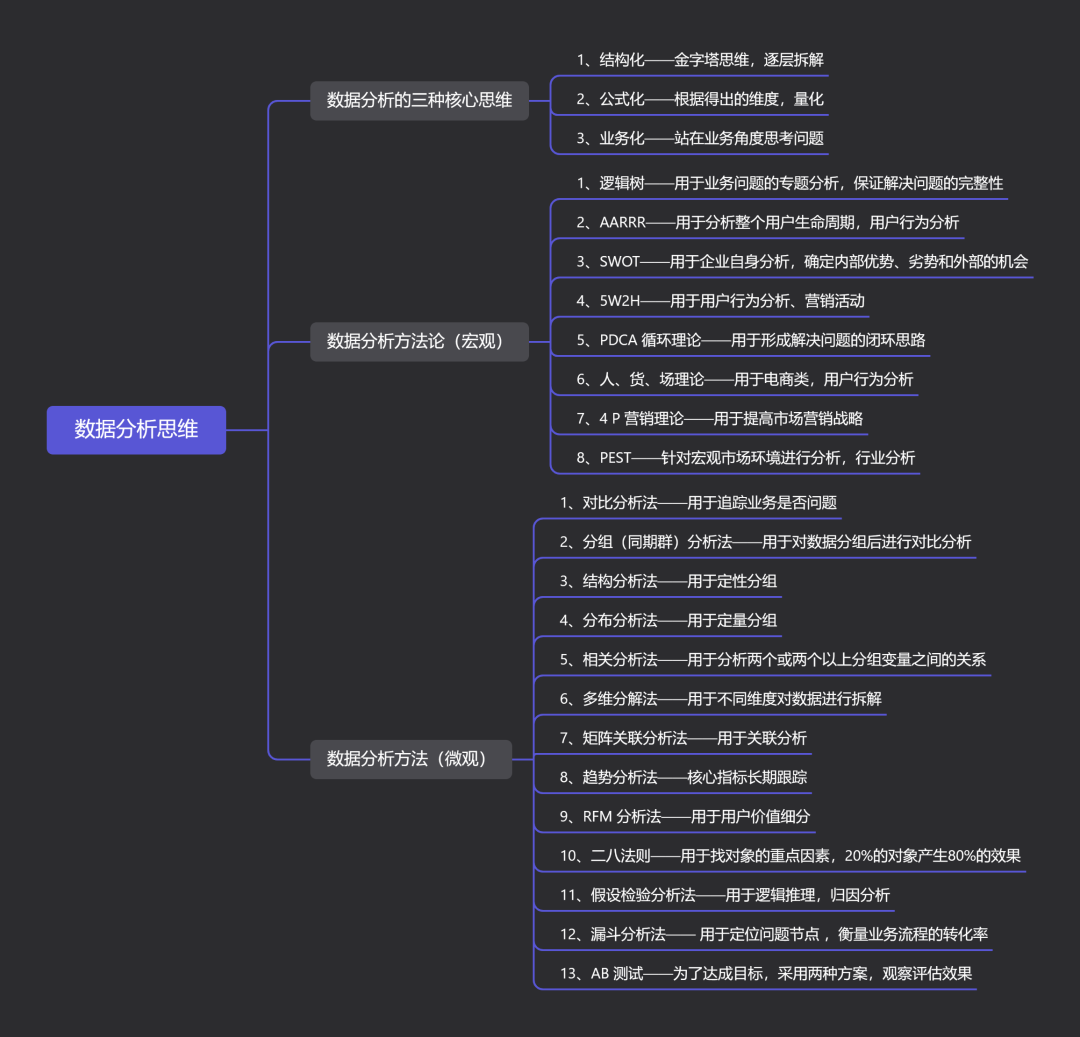 数据分析思维
数据分析思维
项目背景:某生鲜外卖APP于2018年1月1日成立,主营新鲜蔬菜瓜果,海鲜肉禽。APP上线后,市场推广期为一年。通过分析发现原来几个重要的客户被竞争对手挖走了,而这几个用户对平台贡献了80%的销售额。之前对所有用户采用一样的运营策略,为了解决这个问题,需要对用户进行分类,了解当前用户分层情况,进行精细化运营。
一、整体分析流程
1、分析目的:用户分类
2、数据获取:Excel 数据
3、清洗加工:Excel、Python
4、建立模型:RFM
5、数据可视化
6、结论与建议
二、RFM 模型的理解
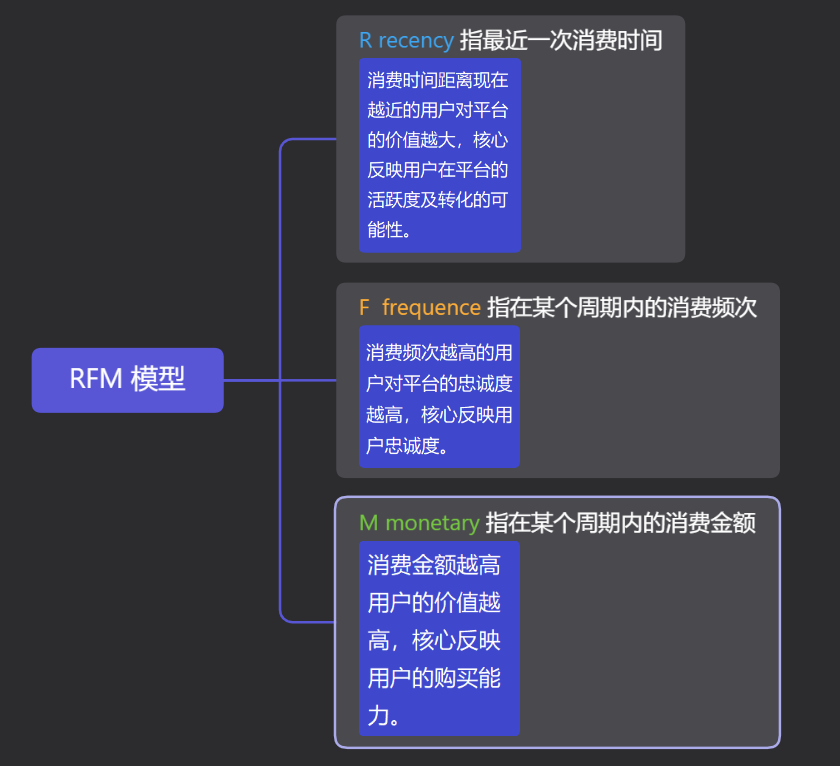

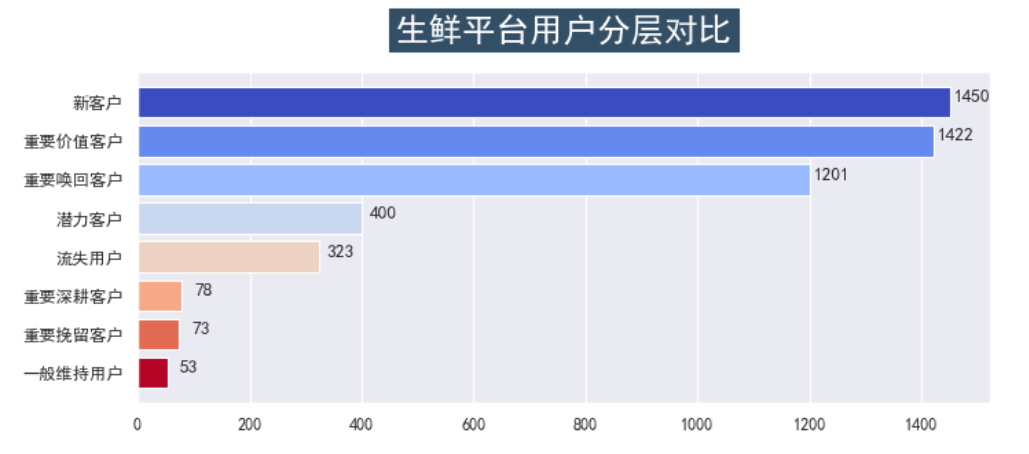
最终将 RFM 模型处理后的结果,作为用户标签,帮助运营更精准地制定活动规则以提升用户使用黏性,强化用户感知。最终实现的效果图如下:
三、利用 Python 实现 RFM 用户分层
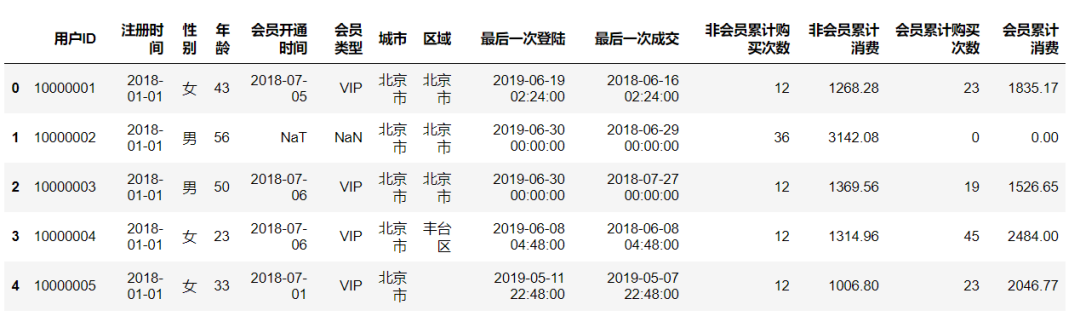
1、获取数据
import pandas as pd
data = pd.read_excel('C:/Users/cherich/Desktop/用户信息.xlsx')
data.head()
data.info()

说明:当前数据集是5000条用户数据,存在缺失值对本次分析不会造成影响。数据清洗,通常包括处理缺失值、重复值、转换数据类型三种。所以仅考虑数据类型即可。这里有个前提条件,R、F、M 应该有一个参照时间,如果活动持续到现在,可以截止到现在。但是我们的数据是历史数据,所以需要查找活动结束时间。
data.sort_values(by='最后一次成交', ascending=False)
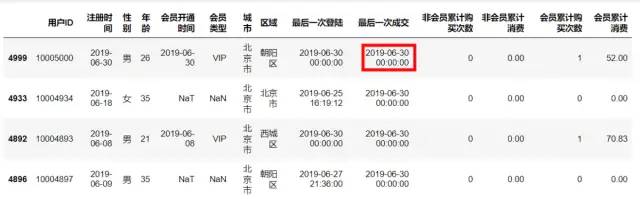
2、数据处理
# 活动结束时间 2019-06-30
data['最后一次成交']=data['最后一次成交'].astype('str')
stop_date = pd.to_datetime('2019-06-30')
datas = data.drop(columns=['注册时间','会员开通时间','会员类型','城市','区域','最后一次登陆'])
datas['最后一次成交时间'] = datas['最后一次成交'].apply(lambda x:x.split()[0])
datas['最后一次成交时间'] = pd.to_datetime(datas['最后一次成交时间'])
datas['R1'] = datas['最后一次成交时间'].apply(lambda x:stop_date-x)
datas['F1'] = datas['非会员累计购买次数']+datas['会员累计购买次数']
datas['M1'] = datas['非会员累计消费'] + datas['会员累计消费']
datas['R1']= datas['R1'].astype(str)
datas['R1']= datas['R1'].apply(lambda x:x.split()[0])
datas
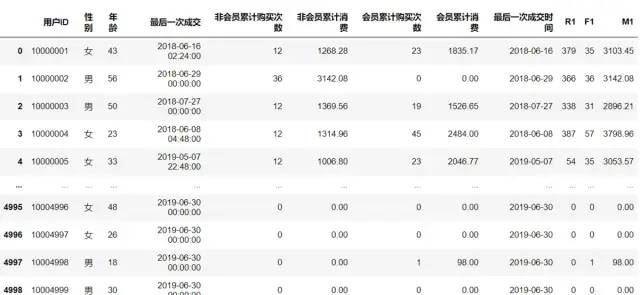
说明:以上操作目的是将R指标由时间类型转换成可计算格式,为接下来建立模型,计算时间间隔做准备。
3、建立模型
建立模型,需要分别对F、R、M 分别计算各自的平均值。但是要注意三个指标数据存在极大值、极小值的情况,这对结果会产生一定的误差,所以解决方案是将其标准化,设置分段区间,5分制,5分为最高。(数值区间可根据具体业务灵活调整或者用四分位数)

def R_score(n):
n = int(n)
if 0<n<=80:
r = 5
elif 80<n<=160:
r = 4
elif 160<n<=240:
r = 3
elif 240<n<=320:
r = 2
else:
r = 1
return r
def F_score(n):
n = int(n)
if 0<n<=14:
r = 1
elif 14<n<=28:
r = 2
elif 28<n<=42:
r = 3
elif 42<n<=56:
r = 4
else:
r = 5
return r
def M_score(n):
n = int(n)
if 0<n<=1500:
r = 1
elif 1500<n<=3000:
r = 2
elif 3000<n<=4500:
r = 3
elif 4500<n<=6000:
r = 4
else:
r = 5
return r
datas['M1_score'] =datas['M1'].apply(M_score)
datas['F1_score'] =datas['F1'].apply(F_score)
datas['R1_score'] =datas['R1'].apply(R_score)
datas.head()
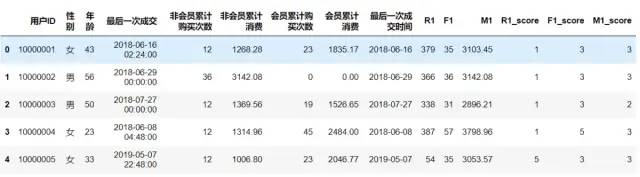
说明:这里对R、F、M 再求平均值,以平均值为标准,如果单个指标大于平均值,显示1,否则显示0。最终RFM的结果由0和1拼接组成,即可得出用户最终类型。
R_mean = datas['R1_score'].mean()
F_mean = datas['F1_score'].mean()
M_mean = datas['M1_score'].mean()
datas['R'] = datas['R1_score'].apply(lambda x: 1 if x> R_mean else 0)
datas['F'] = datas['F1_score'].apply(lambda x: 1 if x> F_mean else 0)
datas['M'] = datas['M1_score'].apply(lambda x: 1 if x> M_mean else 0)
datas
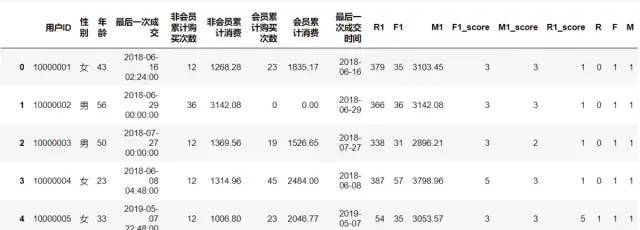
datas['RFM'] = datas['R'].apply(str)+datas['F'].apply(str)+datas['M'].apply(str)
datas
def user_tag(rfm):
if rfm=='000':
res = '流失用户'
elif rfm=='010':
res = '一般维持用户'
elif rfm=='100':
res = '新客户'
elif rfm=='110':
res = '潜力客户'
elif rfm=='001':
res = '重要挽留客户'
elif rfm=='101':
res = '重要深耕客户'
elif rfm=='011':
res = '重要唤回客户'
else:
res = '重要价值客户'
return res
datas['user_tag']=datas['RFM'].apply(user_tag)
datas
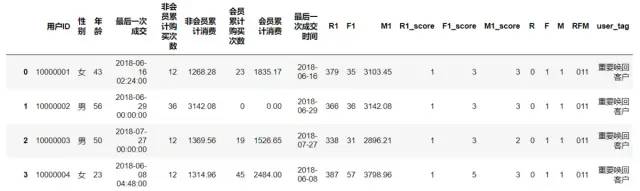
4、数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib as mpl
sns.set(font='SimHei',style='darkgrid')
user_tag = datas.groupby(datas['user_tag']).size()
plt.figure(figsize = (10,4),dpi=80)
user_tag.sort_values(ascending=True,inplace=True)
plt.title(label='生鲜平台用户分层对比',
fontsize=22, color='white',
backgroundcolor='#334f65', pad=20)
s = plt.barh(user_tag.index,user_tag.values , height=0.8, color=plt.cm.coolwarm_r(np.linspace(0,1,len(user_tag))))
for rect in s:
width = rect.get_width()
plt.text(width+40,rect.get_y() + rect.get_height()/2, str(width),ha= 'center')
plt.grid(axis='y')
plt.show()
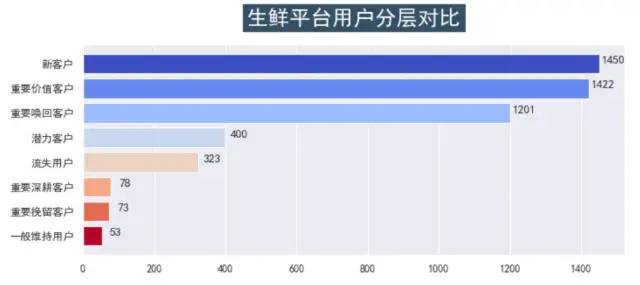
groups_b = datas.groupby(by='user_tag').size()
plt.figure(figsize = (10,6),dpi=80)
plt.title(label='生鲜平台用户分层占比',
fontsize=22, color='white',
backgroundcolor='#334f65', pad=20)
explodes = [0.6, 0, 0, 0, 0,0,0.4,0.8]
patches, l_text, p_text = plt.pie(groups_b.values,labels = groups_b.index, shadow=True,colors=plt.cm.coolwarm_r(np.linspace(0,1,len(groups_b))), autopct='%.2f%%', explode=explodes,startangle=370)
plt.legend(ins,bbox_to_anchor=(2, 1.0))
plt.show()
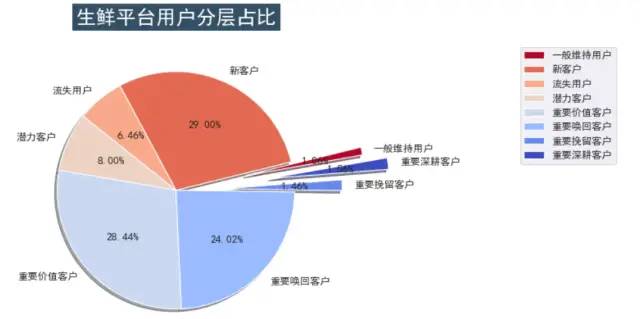
5、结论与建议
以上基本完成了RFM模型实现用户分层,可以看出新客户占比30%左右,重要价值客户占比30%左右。两者是平台的最主要用户类型。
接下来就需要结合具体业务来制定运营策略。最后分享的是,现在我们看到最多的招聘需求是具备分析思维。那什么是分析思维。
我的理解是,首先要理解业务,其次要掌握分析方法,要明确分析方法存在的意义是帮助我们将零散业务问题归类,归类的过程形成分析思路,有了分析思路,那你就具备了分析思维。
公众号「Python之每日一课」,后台回复:「RFM数据」即可获取本文完整数据。
历史投稿文章:
太秀了!用Excel也能实现和Python数据分析一样的功能!
