
Python实现ARMA模型
1.导入相关包,查看数据情况
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = 'SimHei'
%matplotlib inline
df = pd.read_csv('./RFM分析1.csv')
df.info()
输出:

可以看出这里的数据比较完整,没有缺失值不用清洗缺失值。
2.请洗数据
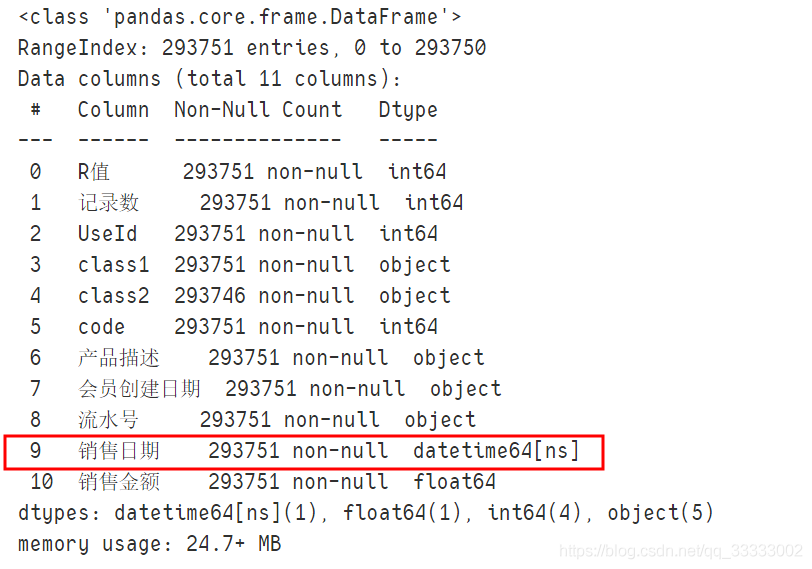
2.1将销售日期转换成datetime类型
df['销售日期'] = pd.to_datetime(df['销售日期'])
# 查看是否修改成功
df.info()
输出:
2.2 使用describe查看均值、最大、最小值情况
df.describe()输出:
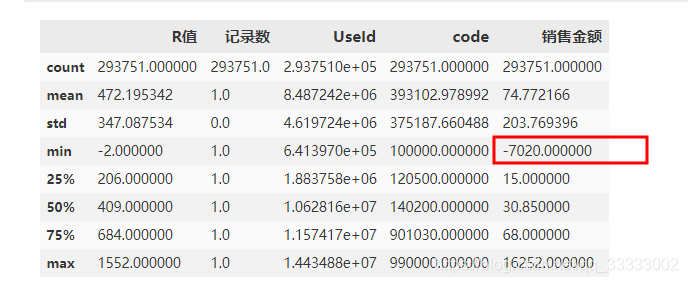
支付金额有负数。查看负数的数据有多少条。
df[df['销售金额'] < 0]

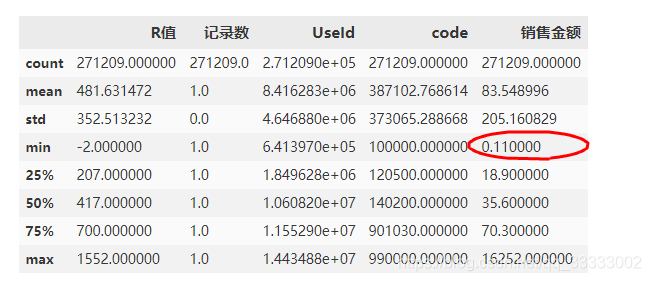
这里有6946条,相对于总数293751,数据比较小,直接当异常值来处理。这里直接获取销售金额大于0的数据来进行分析。
df = df[df['销售金额'] > 0]
# 重新看销售金额的最小值
df.describe()
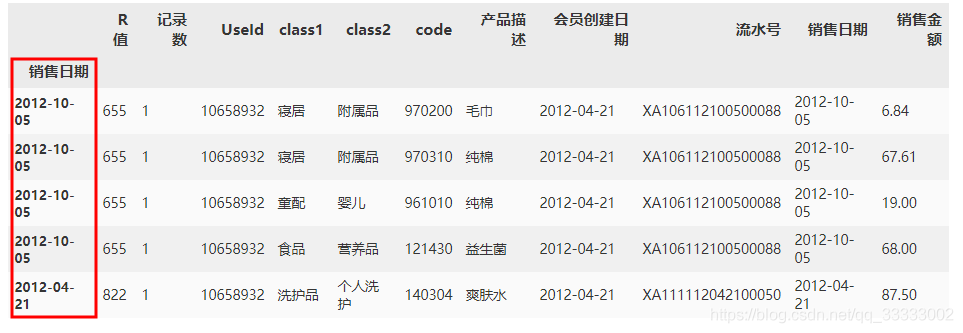
2.3 设置销售日期为index
df.index = df['销售日期']
df.head()
输出:
3.利用ARMA模型进行预测
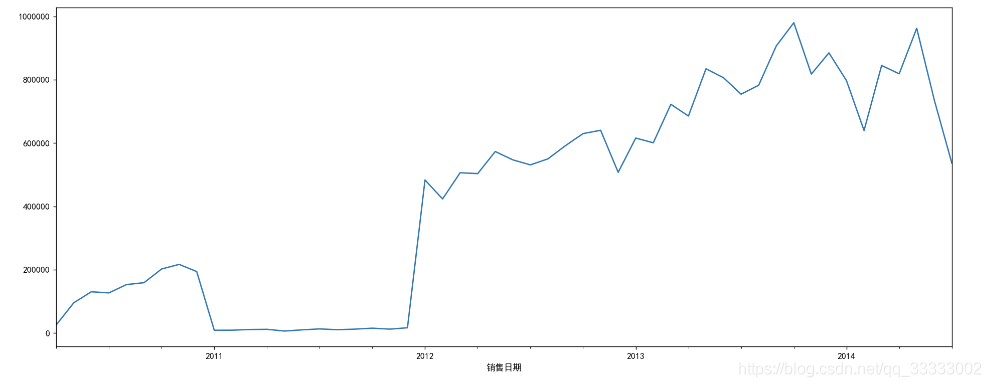
3.1 先查看现有的销售趋势
df_Month = df.resample('M').sum()
plt.figure(figsize=(18, 7), dpi=128)
df_Month['销售金额'].plot()
输出:
3.2 对数据进行训练
from statsmodels.tsa.arima_model import ARMA
from datetime import datetime
from itertools import product
# 设置p阶,q阶范围
# product p,q的所有组合
# 设置最好的aic为无穷大
# 对范围内的p,q阶进行模型训练,得到最优模型
ps = range(0, 6)
qs = range(0, 6)
parameters = product(ps, qs)
parameters_list = list(parameters)
best_aic = float('inf')
results = []
for param in parameters_list:
try:
model = ARMA(df_Month['销售金额'], order=(param[0], param[1])).fit()
except ValueError:
print("参数错误:", param)
continue
aic = model.aic
if aic < best_aic:
best_model = model
best_aic = model.aic
best_param = param
results.append([param, model.aic])
results_table = pd.DataFrame(results)
results_table.columns = ['parameters', 'aic']
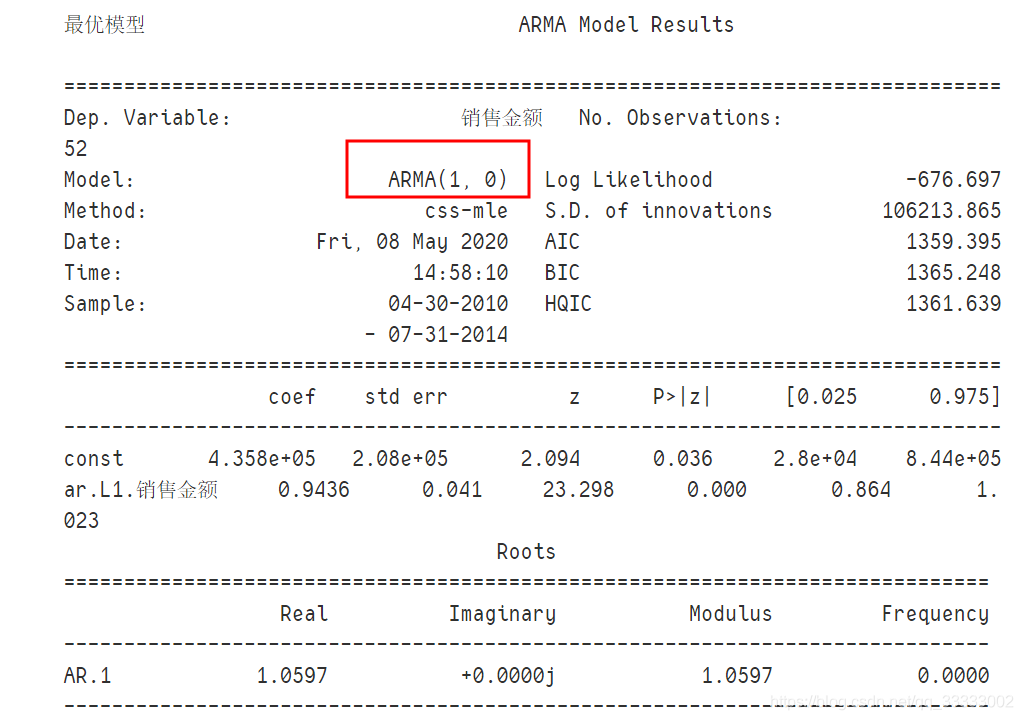
print("最优模型", best_model.summary())
输出:
3.3 预测
# 先增加后几个月的时间日期,进行合并
date_list = [datetime(2014, 8, 31), datetime(2014, 9, 30), datetime(2014, 10, 31),
datetime(2014, 11, 30), datetime(2014, 12, 31),
datetime(2015, 1, 31)]
df_Month = df_Month[['销售金额']]
future = pd.DataFrame(index=date_list, columns= df_Month.columns)
df_Month = pd.concat([df_Month, future])
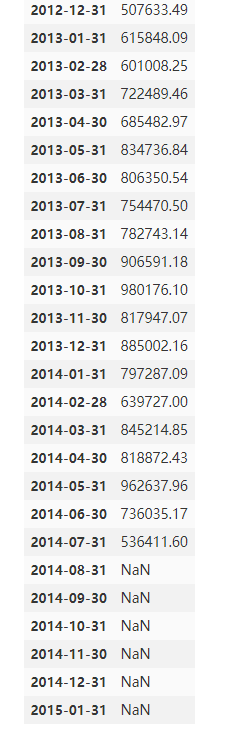
df_Month输出:
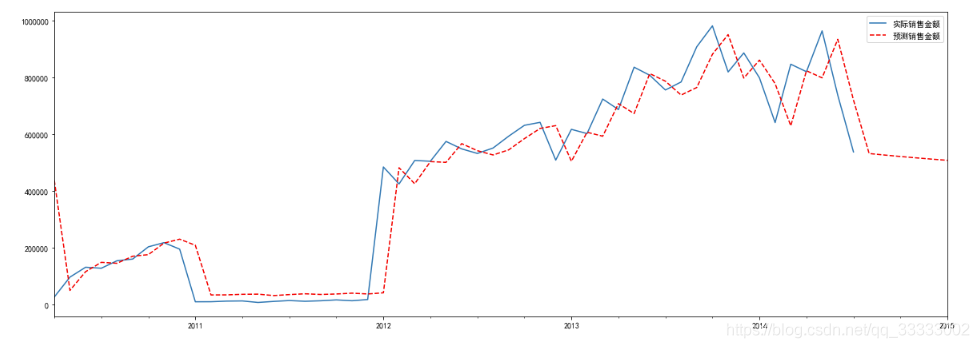
进行预测,可视化df_Month['forecast'] = best_model.predict(start=0, end=58)
plt.figure(figsize=(20, 7))
df_Month['销售金额'].plot(label='实际销售金额')
df_Month['forecast'].plot(color='r', ls='--', label='预测销售金额')
plt.legend()
plt.show()
公众号推荐:数据思践
数据思践公众号记录和分享数据人思考和践行的内容与故事。
《数据科学与人工智能》公众号推荐朋友们学习和使用Python语言,需要加入Python语言群的,请扫码加我个人微信,备注【姓名-Python群】,我诚邀你入群,大家学习和分享。
关于Python语言,有任何问题或者想法,请留言或者加群讨论。
评论