
使用深度优先搜索算法解决迷宫问题

下面是一个简单的小迷宫,其中蓝色方块代表墙壁,白色方块代表道路,你能找到从这个迷宫的入口到出口的路径吗?
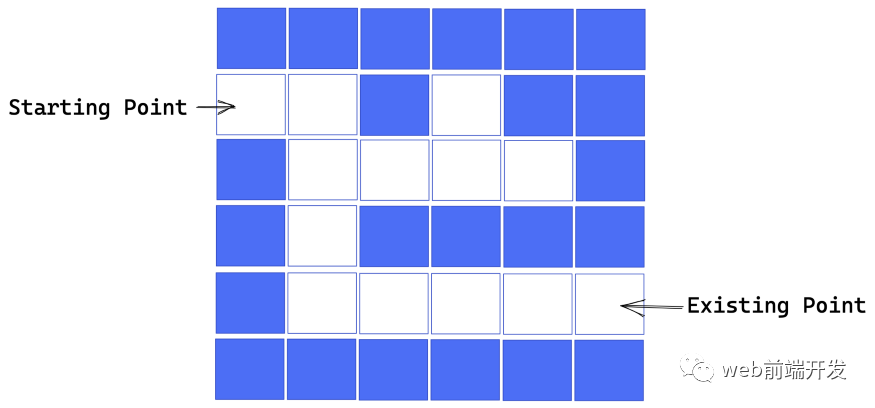
你可能会说:这太简单了,迷宫的解法我一眼就能搞定。
确实,上面的迷宫很简单。但是,如果给你这样一个迷宫,你还能找到它的解决方案吗?

面对这样的迷宫,你可能无法一眼就得到迷宫的解法,对你来说可能还需要考虑一段时间。
现在,如果您要编写一个程序来自动解决迷宫,您将如何编写代码?
分析
事实上,当我们解决这类问题时,我们不能想当然。我们应该使用标准化的语言来描述我们的想法,然后将这个想法编程为代码。
对于所有的迷宫问题,可以用一个很简单的思路来解题,那就是遍历。
我们可以从起点开始:
首先,判断当前点是否为已有点。如果是,就意味着我们已经找到了终点;如果不是,那么我们需要继续遍历。
然后去正确的地方,并重复步骤 1。
然后转到它的下面点,并重复步骤 1。
然后去它的左边点,并重复步骤 1。
然后转到上面的点,并重复步骤 1。
如果这个过程是用伪代码描述的,它看起来像这样
function solvePoint(x, y) {if Point(x, y) is the existing point:we get the existing point.else:solvePoint(x + 1, y)solvePoint(x, y - 1)solvePoint(x - 1, y)solvePoint(x, y + 1)}
我们可以发现,这个过程实际上包含了一个递归过程。
当然,上述步骤中没有考虑边界条件和重复访问。但这是次要的,我们可以稍后添加。
但不管怎样,通过以上步骤,我们可以遍历整个迷宫,找到出口的位置。
这样的步骤看似繁琐,其实是最有效的方法。而对于计算来说,穿越迷宫的任务非常简单,可以很快完成。
解决小迷宫
我们可以将上述想法应用到小迷宫中。
首先,我们从起点出发,发现这个点不是现有的点,所以我们需要在这个点的上下左右上下左右。然后我们发现起点的上、下、左都不是合法道路,所以只能往右走。
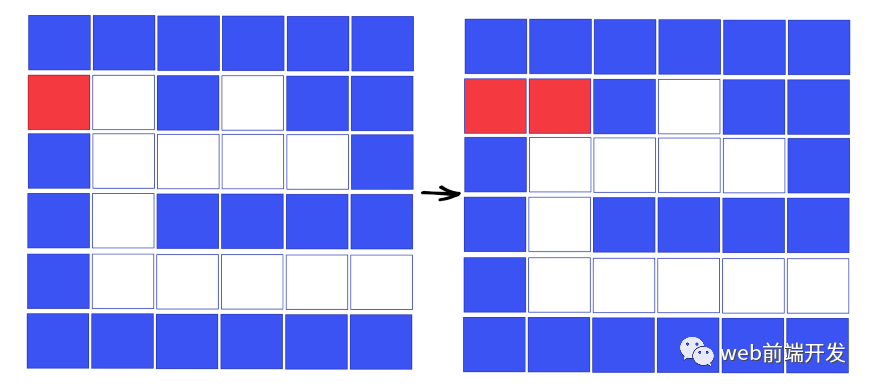
然后我们需要往下走:
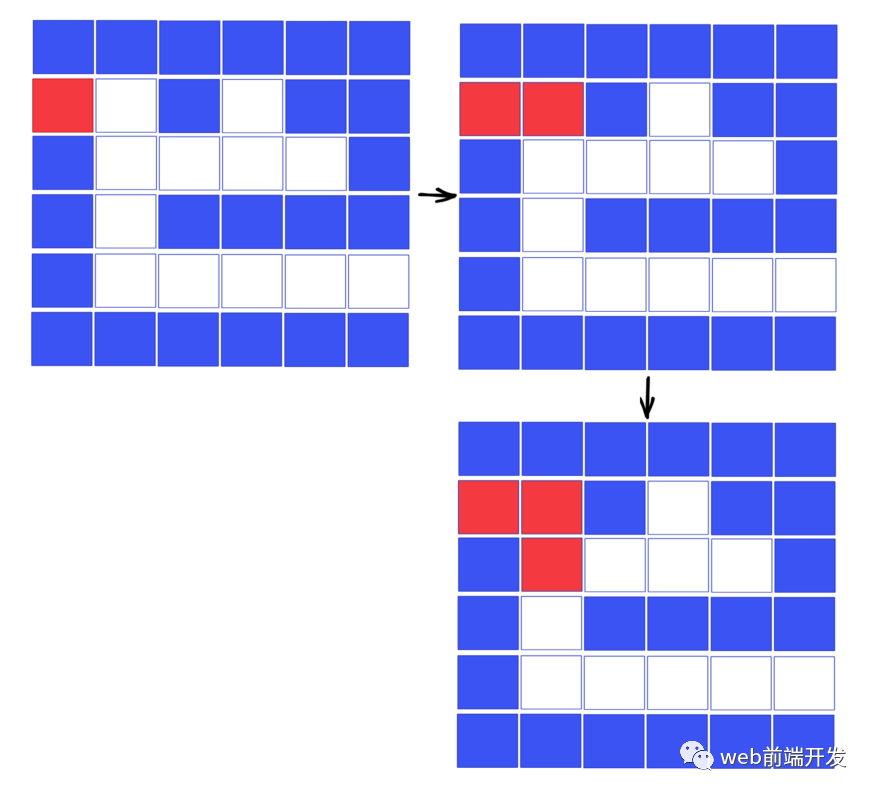
这时候,我们发现其实有两个选择:可以向右走,也可以向下走。而只要我们尝试所有可能的路径,最终我们一定会找到解决方案。
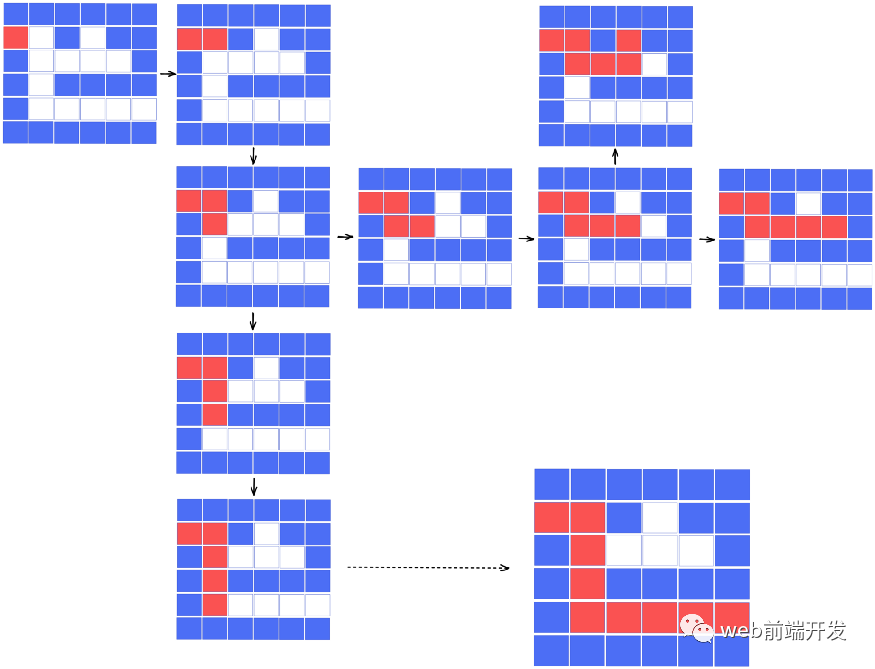
代码实现
以上是我们的想法,很简单。一句话总结就是:按照一定的顺序遍历整个迷宫的所有可能路径,你一定会到达存在点并找到解决方案。
通过这个算法解迷宫的代码放在目录solution/DFS-Recursive中:https://github.com/BytefishMedium/MazeGame
然后,为了方便读者更好的理解相关代码,我将代码分为v1到v7版本。v1是基本代码框架,v7是最终完整代码。
在本文中,我介绍了如何使用数组来表示迷宫,以及如何使用 Canvas 来渲染迷宫。
v1
首先,我们要明确一件事,那就是我们的终极目标。
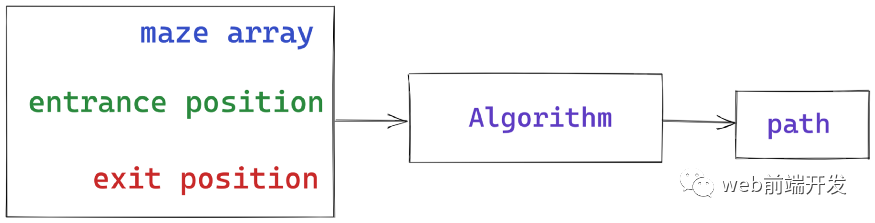
在我们的迷宫求解问题中,我们需要以下数据作为输入:迷宫数组、入口坐标和出口坐标。那么,我们的算法应该返回一个点数组,这个数组表示从入口到出口的路径:
正如我之前所说,我们使用二维数组来表示迷宫。既然我们的目标是解迷宫,那么我们肯定需要一个迷宫数组作为参数。
然后我们需要知道入口坐标。为方便起见,本项目始终使用第二行第一列的点,即坐标为(0, 1)的点作为迷宫的入口。
我们还需要知道现有点的坐标。为方便起见,本项目始终使用倒数第二行和最后一列中的点作为出口。即坐标为{mazeArray[0].length — 1, mazeArray.length — 2}的点。
最后,我们使用编程语言 JavaScript。JavaScript 支持函数式编程和面向对象的编程。在我的实践中,我发现这个项目的代码会涉及到很多变量和实用函数,所以我认为使用类表示法更方便。
好的,基本的代码框架是:
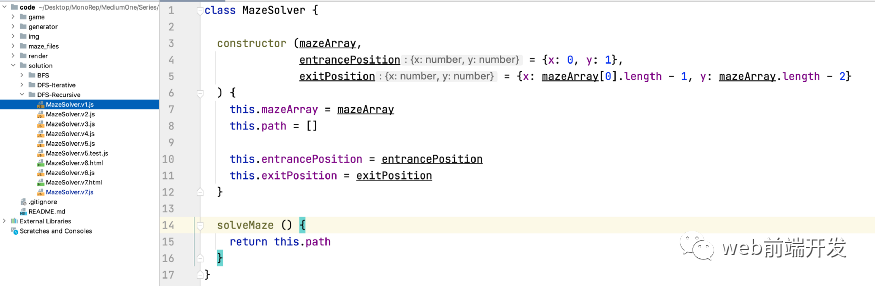
class MazeSolver {constructor (mazeArray,entrancePosition = {x: 0, y: 1},exitPosition = {x: mazeArray[0].length - 1, y: mazeArray.length - 2}) {this.mazeArray = mazeArraythis.path = []this.entrancePosition = entrancePositionthis.exitPosition = exitPosition}solveMaze () {return this.path}}
因为我们的目的是解决迷宫问题,所以我们定义了一个名为 MazeSolver 的类。在构造函数中,我们要求调用者传入迷宫数组、入口坐标、出口坐标等信息。由于我们之前约定一般使用固定的出入口,所以我们会给这两个参数一个默认值。
然后我们用this.path来存储迷宫的最终解法,然后solveMaze就是解迷宫的方法。
v2
然后我们在之前的伪代码中说过,解迷宫的本质就是遍历迷宫。如果某个点不是现有点,则尝试访问该点周围的点:上、下、左、右。
所以当我们的代码的v2版本是用递归来解决它的上、下、左、右点时:
class MazeSolver {constructor (mazeArray,entrancePosition = {x: 0, y: 1},exitPosition = {x: mazeArray[0].length - 1, y: mazeArray.length - 2}) {this.mazeArray = mazeArraythis.path = []this.entrancePosition = entrancePositionthis.exitPosition = exitPosition}solvePoint(x, y){this.solvePoint(x + 1, y)this.solvePoint(x, y + 1)this.solvePoint(x - 1, y)this.solvePoint(x, y - 1)}solveMaze () {this.solvePoint(0, 1)return this.path}}
在这里,我们从起点solvePoint(0,1)开始,然后将四个点向左、上、右、下循环。
其实这里有个小问题,就是我们遍历周围四个点的时候,是按什么顺序来的?是上、下、左、右,还是下、左、右、上?这不影响最终的结果,但确实影响了具体的过程。我们将在可视化部分讨论差异,并在此处留下悬念。
那么上面的代码中没有考虑边界问题和终止条件,我们现在继续。
v3
这种遍历的终止条件是到达出口。所以我们只需要简单的添加一个判断来判断当前点是否是现有点。
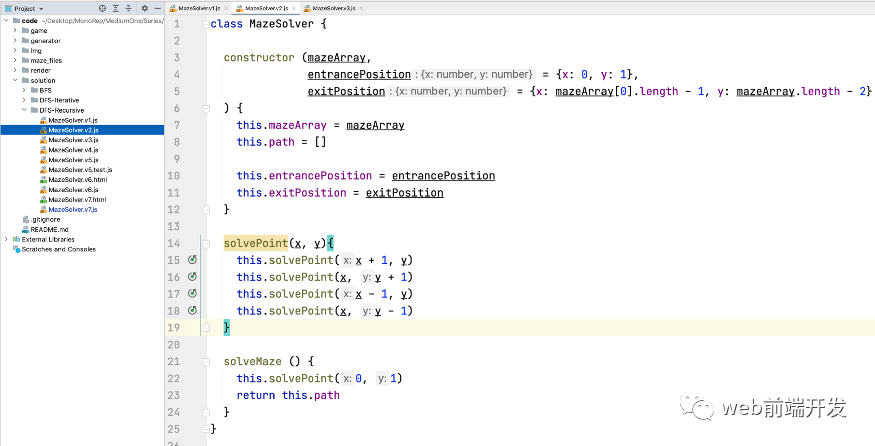
class MazeSolver {constructor (mazeArray,entrancePosition = {x: 0, y: 1},exitPosition = {x: mazeArray[0].length - 1, y: mazeArray.length - 2}) {this.mazeArray = mazeArraythis.path = []this.entrancePosition = entrancePositionthis.exitPosition = exitPosition}solvePoint(x, y){if (x === this.exitPosition.x && y === this.exitPosition.y) {console.log('you win')return}this.solvePoint(x + 1, y)this.solvePoint(x, y + 1)this.solvePoint(x - 1, y)this.solvePoint(x, y - 1)}solveMaze () {this.solvePoint(0, 1)return this.path}}
v4
但是一个点周围的四个点不一定都是合法的道路,有可能是越界,或者这个点是一堵墙。所以我们在递归的时候,还是需要判断一个点是否是合法的路。
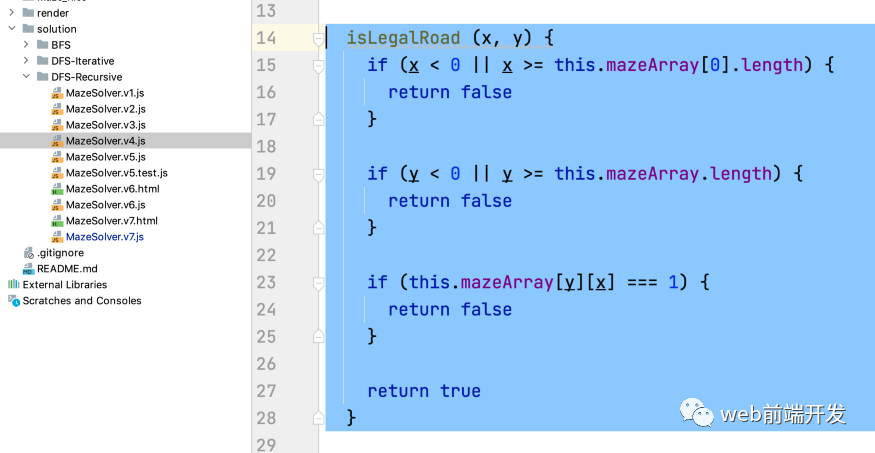
判断条件很简单:
横坐标是否越界
纵坐标是否超出范围
这个点是不是墙
然后在递归之前,判断下一点是否合法:
class MazeSolver {constructor (mazeArray,entrancePosition = {x: 0, y: 1},exitPosition = {x: mazeArray[0].length - 1, y: mazeArray.length - 2}) {this.mazeArray = mazeArraythis.path = []this.entrancePosition = entrancePositionthis.exitPosition = exitPosition}isLegalRoad (x, y) {if (x < 0 || x >= this.mazeArray[0].length) {return false}if (y < 0 || y >= this.mazeArray.length) {return false}if (this.mazeArray[y][x] === 1) {return false}return true}solvePoint(x, y){if (x === this.exitPosition.x && y === this.exitPosition.y) {console.log('you win')return}if(this.isLegalRoad(x + 1, y)){this.solvePoint(x + 1, y)}if(this.isLegalRoad(x, y + 1)){this.solvePoint(x, y + 1)}if(this.isLegalRoad(x - 1, y)){this.solvePoint(x - 1, y)}if(this.isLegalRoad(x, y - 1)){this.solvePoint(x, y - 1)}}solveMaze () {this.solvePoint(0, 1)return this.path}}
v5
除了判断点是否合法外,我们还要处理重复访问的问题。在上面的代码中,我们没有考虑重复访问某个点的问题,所以在递归过程中可能会导致重复访问某个点,导致死循环。
为了解决这个问题,我们必须记录访问过的点,然后在递归到下一个点之前进行判断。
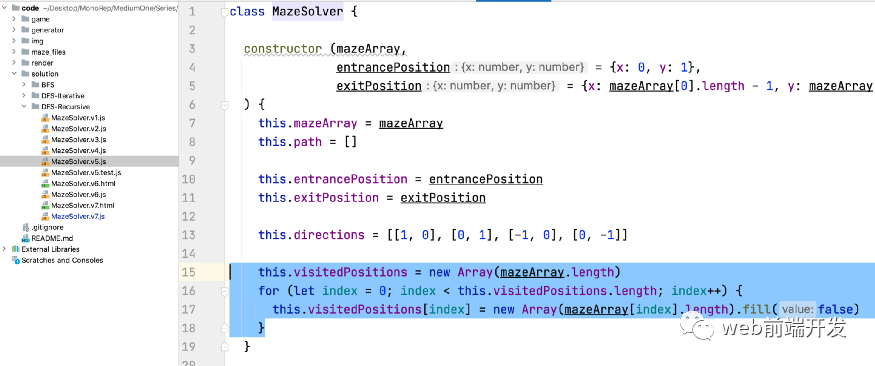
visitedPosition 是一个与迷宫数组中的点对应的二维数组,它的值是一个布尔值。如果为false,则表示迷宫中的对应点没有被访问过;如果为真,则说明迷宫中的对应点已经被访问过。
稍后,当我们遍历下一个点时,我们可以做一个额外的判断:

在这里,我们正在讨论一种用于优化代码的附加技术。我们之前的代码是这样的:

如果直接修改这段代码,需要修改4个地方。
但是我们可以发现,这四个点的坐标变化非常规律。
横坐标不变,纵坐标加1
横坐标加1,纵坐标不变
横坐标不变,纵坐标减1
横坐标减1,纵坐标不变
就数字而言,它可能如下所示:
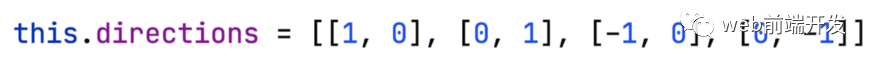
然后我们可以像这样优化代码:

因为后面我们对里面的代码还有很多的优化,这个小技巧可以方便我们以后改代码。
完整代码可以查看相关源文件:
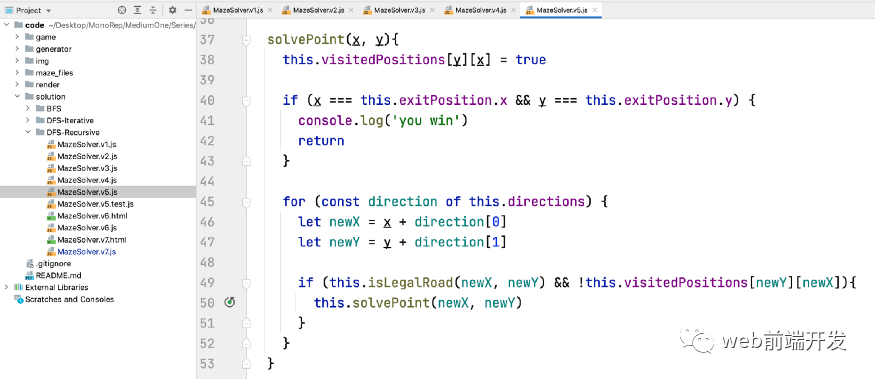
class MazeSolver {constructor (mazeArray,entrancePosition = {x: 0, y: 1},exitPosition = {x: mazeArray[0].length - 1, y: mazeArray.length - 2}) {this.mazeArray = mazeArraythis.path = []this.entrancePosition = entrancePositionthis.exitPosition = exitPositionthis.directions = [[1, 0], [0, 1], [-1, 0], [0, -1]]this.visitedPositions = new Array(mazeArray.length)for (let index = 0; index < this.visitedPositions.length; index++) {this.visitedPositions[index] = new Array(mazeArray[index].length).fill(false)}}isLegalRoad (x, y) {if (x < 0 || x >= this.mazeArray[0].length) {return false}if (y < 0 || y >= this.mazeArray.length) {return false}if (this.mazeArray[y][x] === 1) {return false}return true}solvePoint(x, y){this.visitedPositions[y][x] = trueif (x === this.exitPosition.x && y === this.exitPosition.y) {console.log('you win')return}for (const direction of this.directions) {let newX = x + direction[0]let newY = y + direction[1]if (this.isLegalRoad(newX, newY) && !this.visitedPositions[newY][newX]){this.solvePoint(newX, newY)}}}/**** @return {*}*/solveMaze () {this.solvePoint(0, 1)return this.path}}module.exports = MazeSolver
v5.test
上面的代码已经可以找到迷宫的解法了,我们可以测试一下。具体代码在 MazeSolver.v5.test.js
const MazeSolver = require('./MazeSolver.v5')function test () {let mazeArray = [[1, 1, 1, 1, 1, 1],[0, 0, 1, 0, 1, 1],[1, 0, 0, 0, 0, 1],[1, 0, 1, 1, 1, 1],[1, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1],]let mazeSolver = new MazeSolver(mazeArray)mazeSolver.solveMaze()}test()function test2 () {let mazeArray2 = require('../../maze_files/mazeArray101.node.js')let mazeSolver = new MazeSolver(mazeArray2)mazeSolver.solveMaze()}test2()
我们有两个测试用例,一个是解决小迷宫,另一个是maze_files中的大迷宫。
然后,我们新建一个 MazeSolver 实例,然后调用它的solveMaze 方法来解迷宫。
最后,我们执行完代码后,在控制台看到你win打印了两次,说明我们的程序确实到了结尾。
v6
虽然已经走到了尽头,但具体的过程我们还是不知道。这时候我们需要添加一些代码:在遍历的过程中,记录解路径中的点,然后记录到this.path数组中。
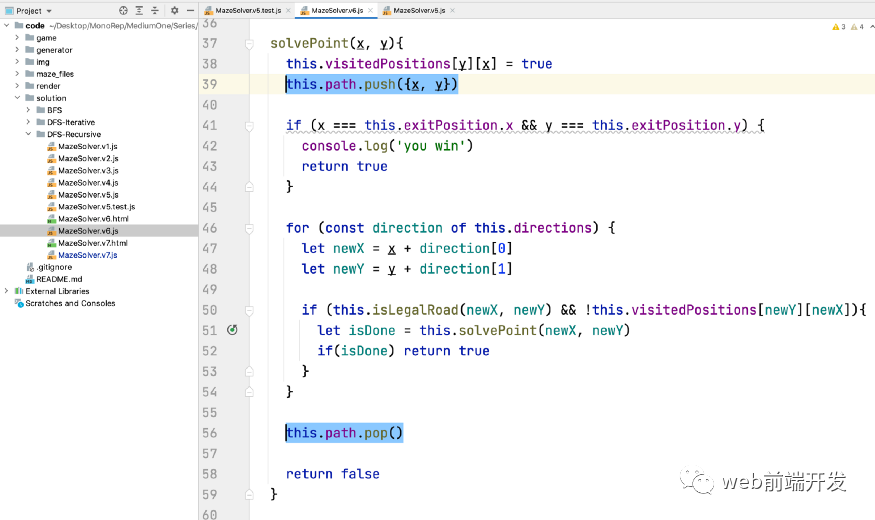
思路也很简单,就是开始求解某个点的时候,把这个点压进this.path,记录下这个位置。
但同时,每个人都需要意识到,有些道路是死胡同。比如上面的小迷宫,在第三个点,它会先向右走,然后发现是死路,然后又往回走。
所以会有一个回滚过程。回滚时,我们需要通过 this.path.pop() 从路径数组中移除这个点。
最后,如果我们的程序到了出口,就不需要继续往下遍历了,我们还要给我们的递归加上一个终止条件。

好的,这些是我们最终的递归代码:
有终止条件
有边界判断
然后返回一个路径
class MazeSolver {constructor (mazeArray,entrancePosition = {x: 0, y: 1},exitPosition = {x: mazeArray[0].length - 1, y: mazeArray.length - 2}) {this.mazeArray = mazeArraythis.path = []this.entrancePosition = entrancePositionthis.exitPosition = exitPositionthis.directions = [[1, 0], [0, 1], [-1, 0], [0, -1]]this.visitedPositions = new Array(mazeArray.length)for (let index = 0; index < this.visitedPositions.length; index++) {this.visitedPositions[index] = new Array(mazeArray[index].length).fill(false)}}isLegalRoad (x, y) {if (x < 0 || x >= this.mazeArray[0].length) {return false}if (y < 0 || y >= this.mazeArray.length) {return false}if (this.mazeArray[y][x] === 1) {return false}return true}solvePoint(x, y){this.visitedPositions[y][x] = truethis.path.push({x, y})if (x === this.exitPosition.x && y === this.exitPosition.y) {console.log('you win')return true}for (const direction of this.directions) {let newX = x + direction[0]let newY = y + direction[1]if (this.isLegalRoad(newX, newY) && !this.visitedPositions[newY][newX]){let isDone = this.solvePoint(newX, newY)if(isDone) return true}}this.path.pop()return false}/**** @return {*}*/solveMaze () {let result = this.solvePoint(0, 1)if (result === false) {console.log('no solution for this maze')}return this.path}}function test () {let mazeArray = [[1, 1, 1, 1, 1, 1],[0, 0, 1, 0, 1, 1],[1, 0, 0, 0, 0, 1],[1, 0, 1, 1, 1, 1],[1, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1],]let mazeSolver = new MazeSolver(mazeArray)let path = mazeSolver.solveMaze()console.log(path)}// test()function test2 () {let mazeArray2 = require('../../maze_files/mazeArray101.node.js')let mazeSolver = new MazeSolver(mazeArray2)let path = mazeSolver.solveMaze()console.log(path)}// test2()
v6.html
现在,我们可以绘制迷宫和路径:
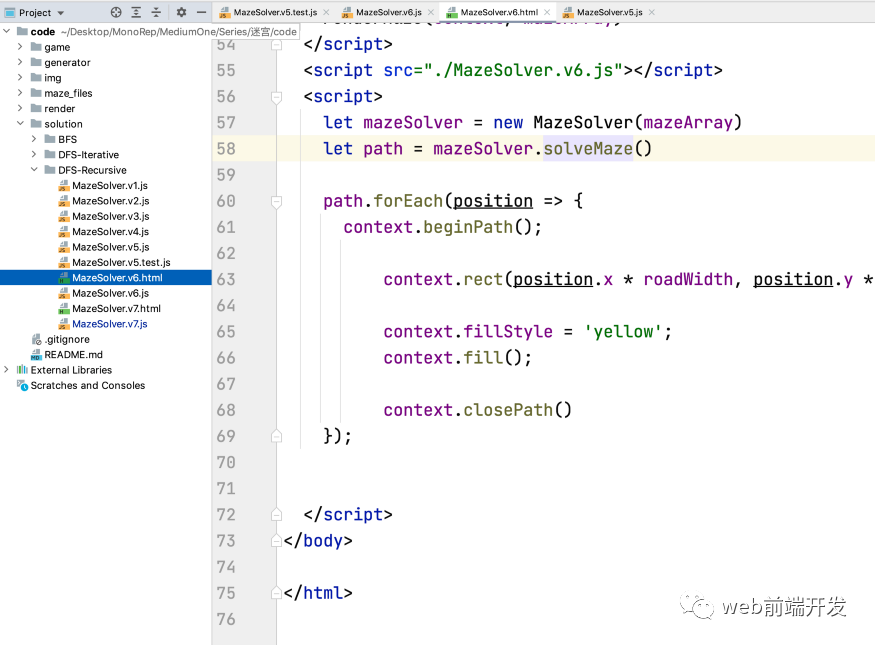
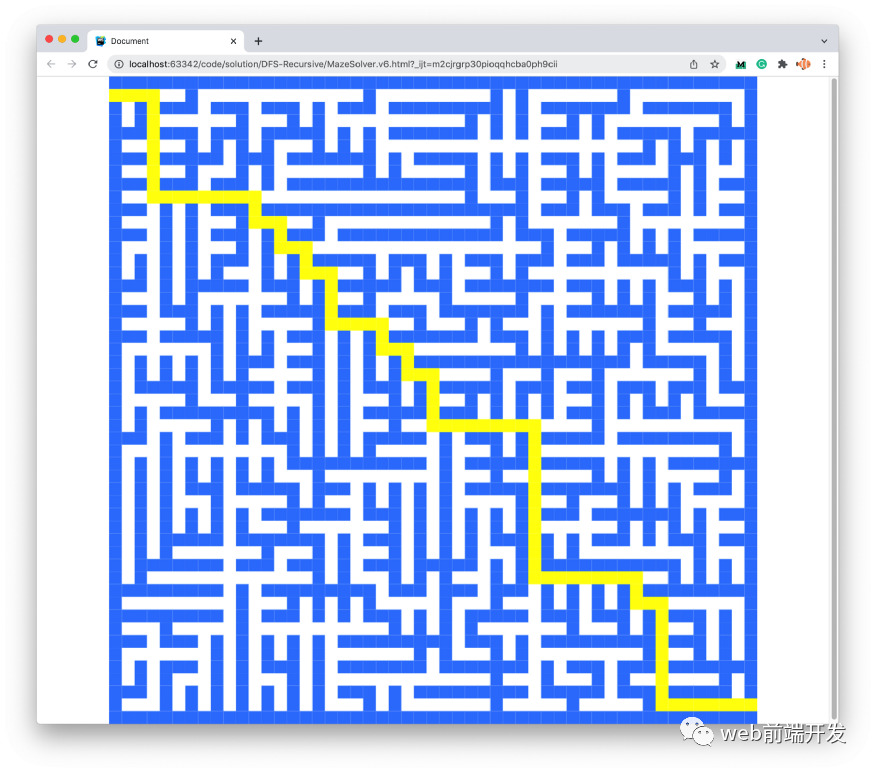
v7
但是上面的代码只展示了静态的结果,并没有展示动态的过程。
我们还想知道的是:算法访问了哪些点,经过了哪些死胡同,最后是如何回归的。
为了解决这个问题,我们需要继续添加代码。我们添加一个数组:
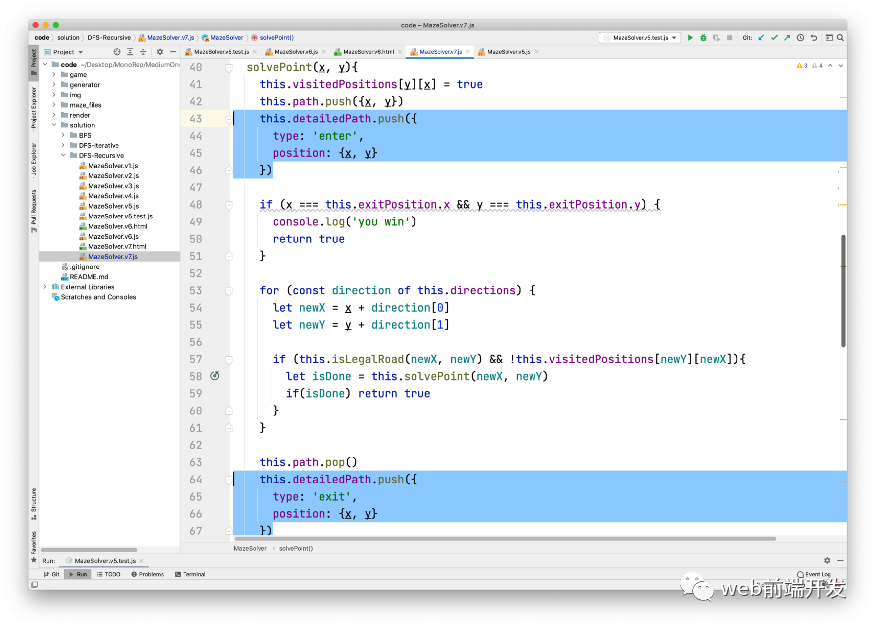
//[{type:'enter' , position:{x:0 , y:1}} , {type: 'exit' , position:{x:0 , y:1}}]this.detailedPath = []
截图如下:
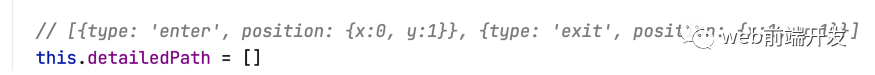
这个数组不仅记录了访问过哪些点,还记录了是进入还是离开这些点。enter 表示进入,exit 表示离开。
然后,我们在solvePoint方法开始执行后标记进入该点,并在结束前标记离开该点。最终代码如下:
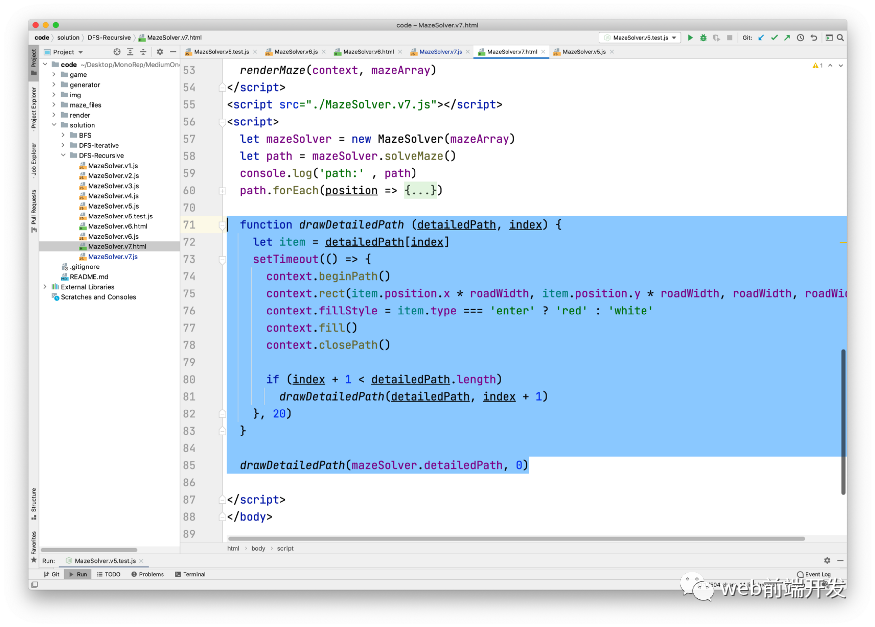
现在,detaillePath 可以记录算法的具体执行过程。
让我们渲染它:
不是很酷吗?
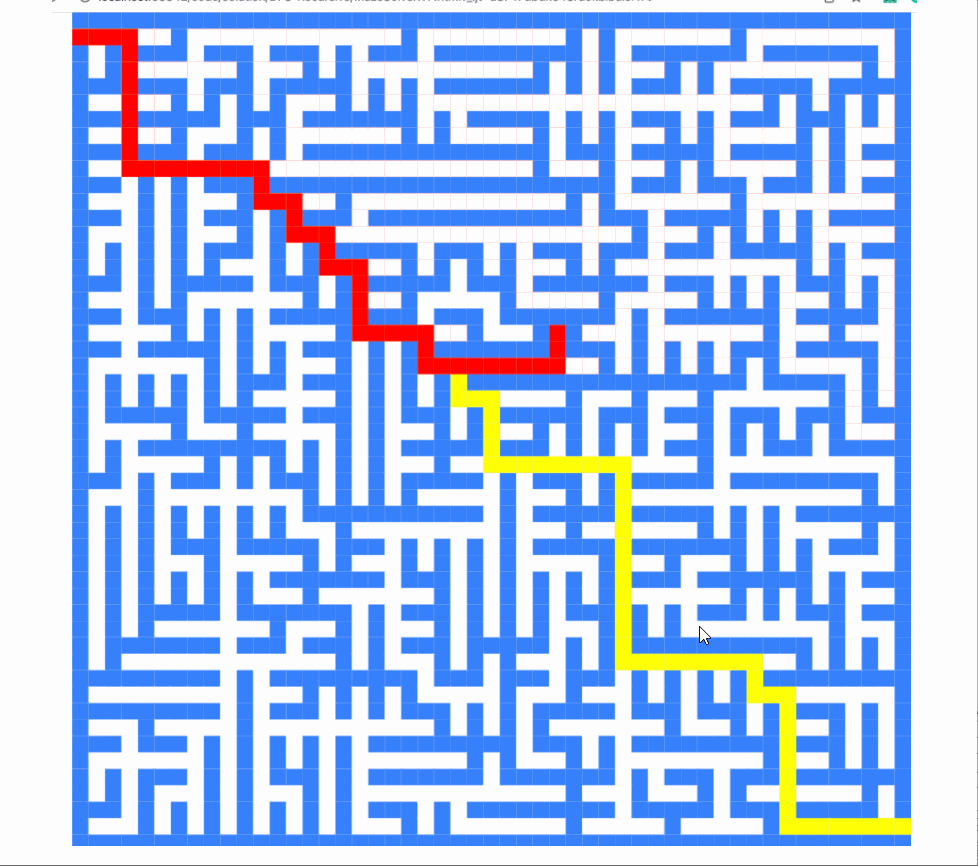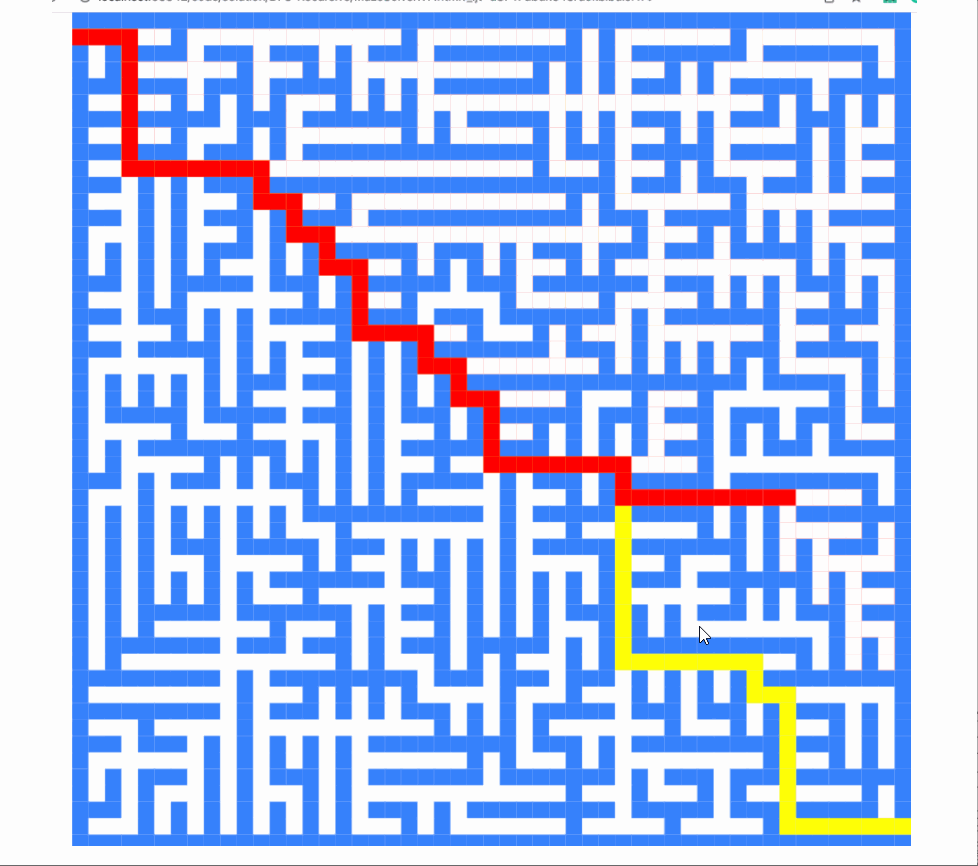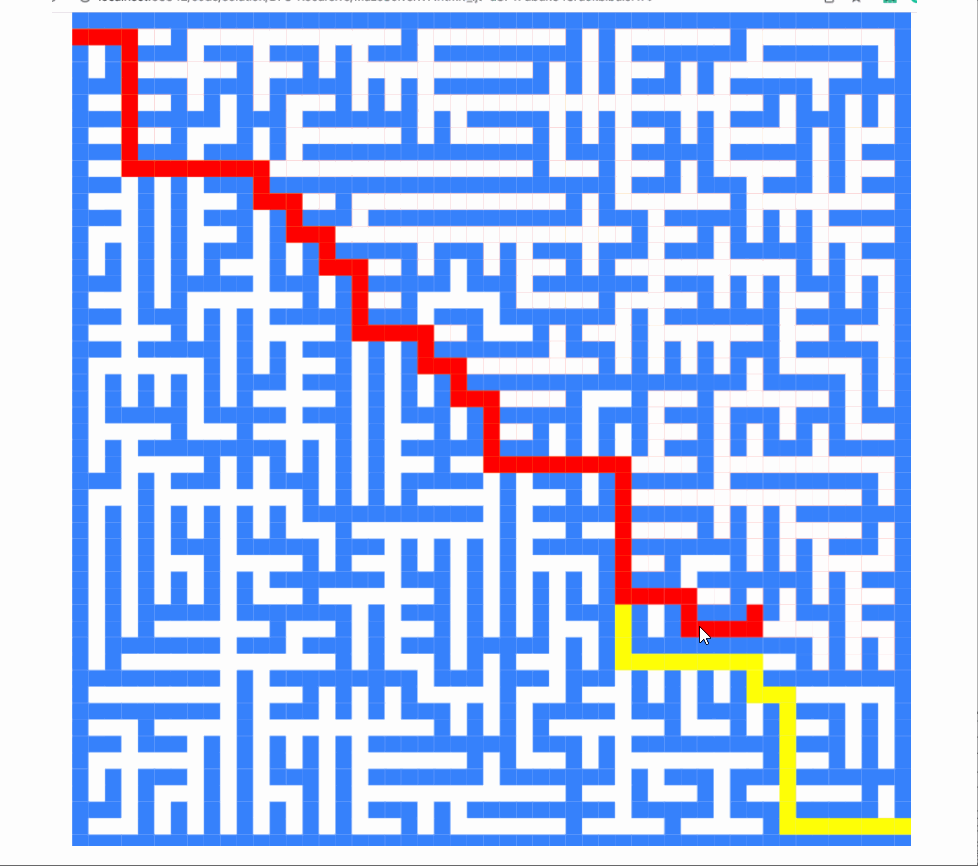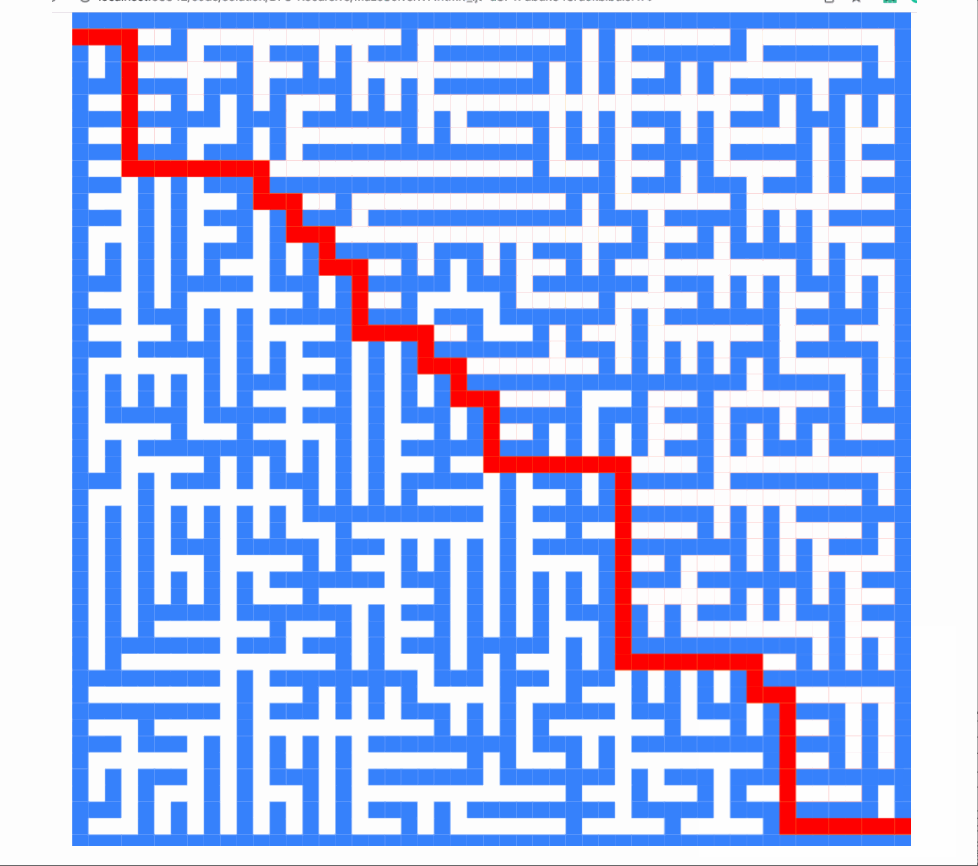
v8
那么,你有没有注意到算法总是先向左尝试?
这实际上符合我们之前提到的代码:

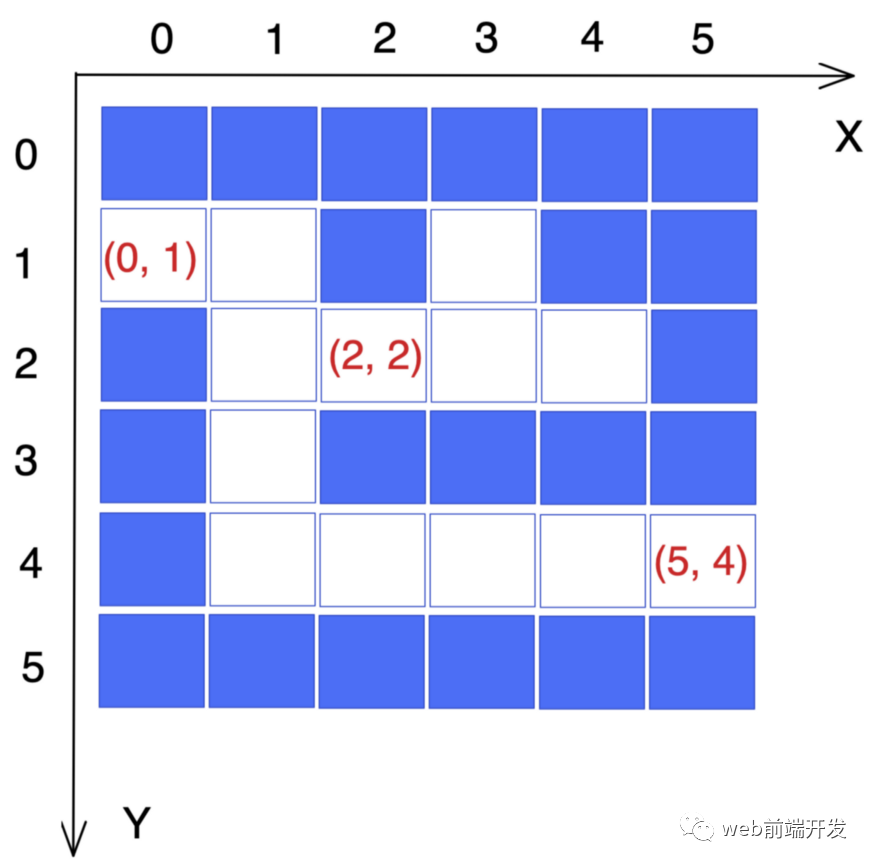
而我们的坐标系是这样的:
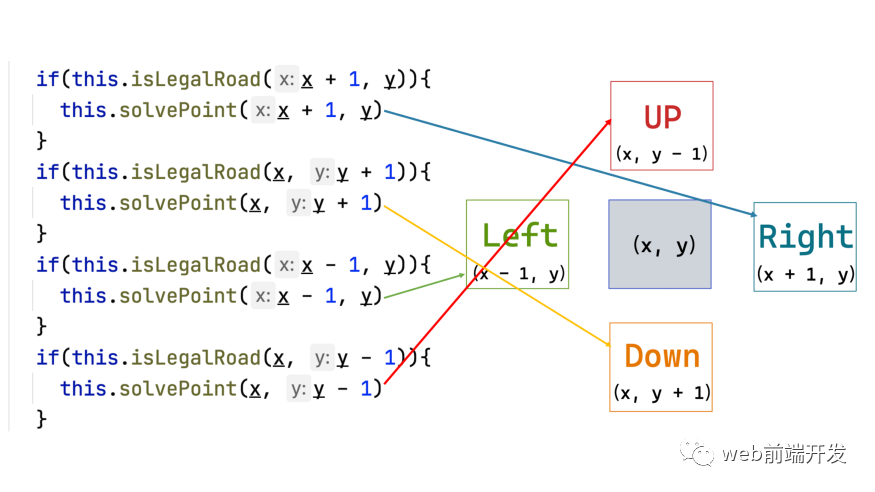
所以在之前的搜索路径中,我们的算法总是优先向右走。
如果要调整搜索顺序,只需要改变以上几行代码的顺序即可。但是正如我们之前提到的,我们用 this.directions 修改了代码,所以我们现在可以像这样修改它:
this.directions = [[-1,0],[0,1],[1,0],[0,-1]]截图如下:

现在它是:
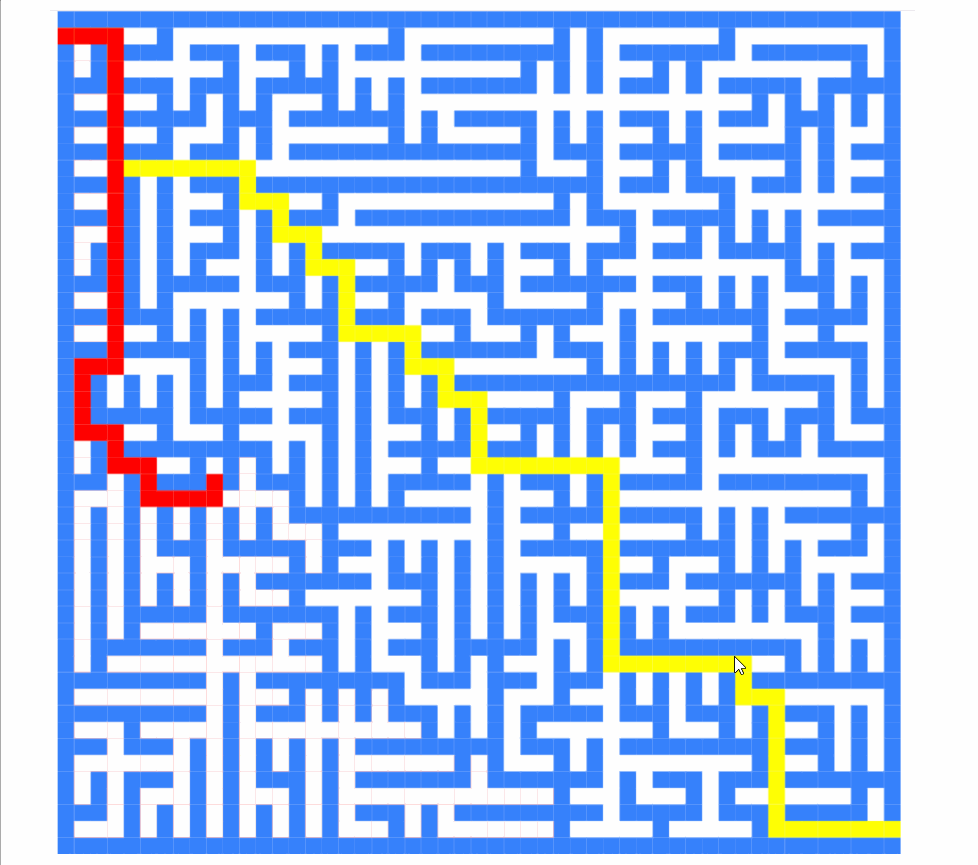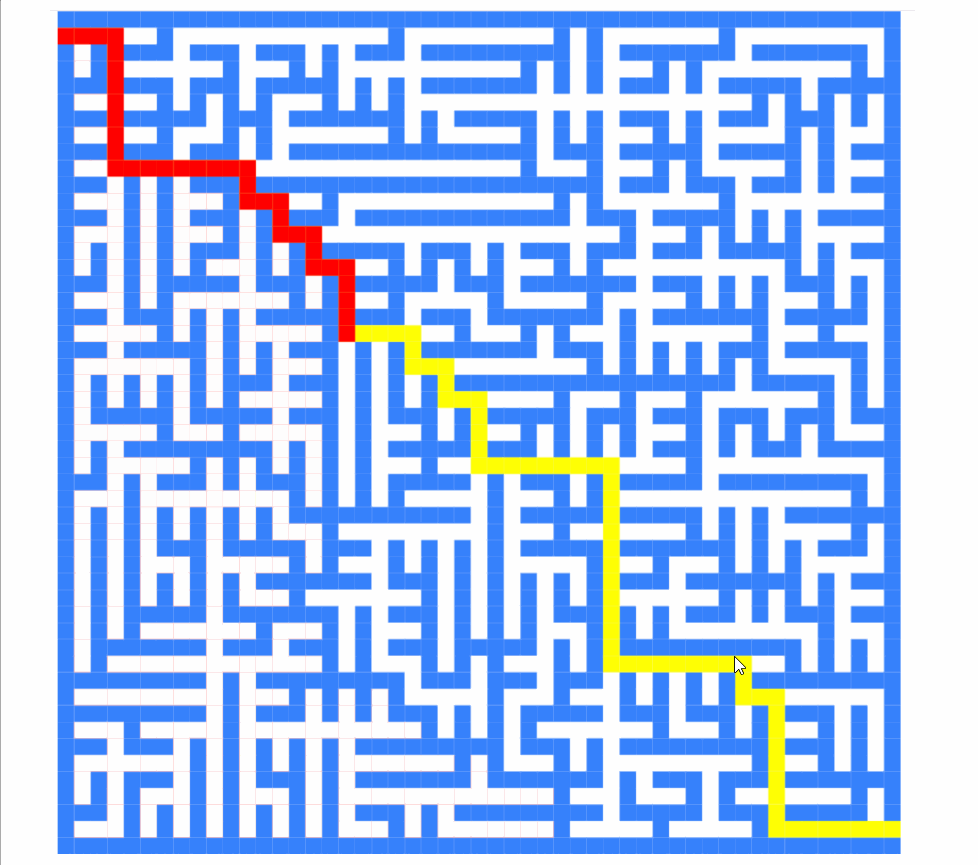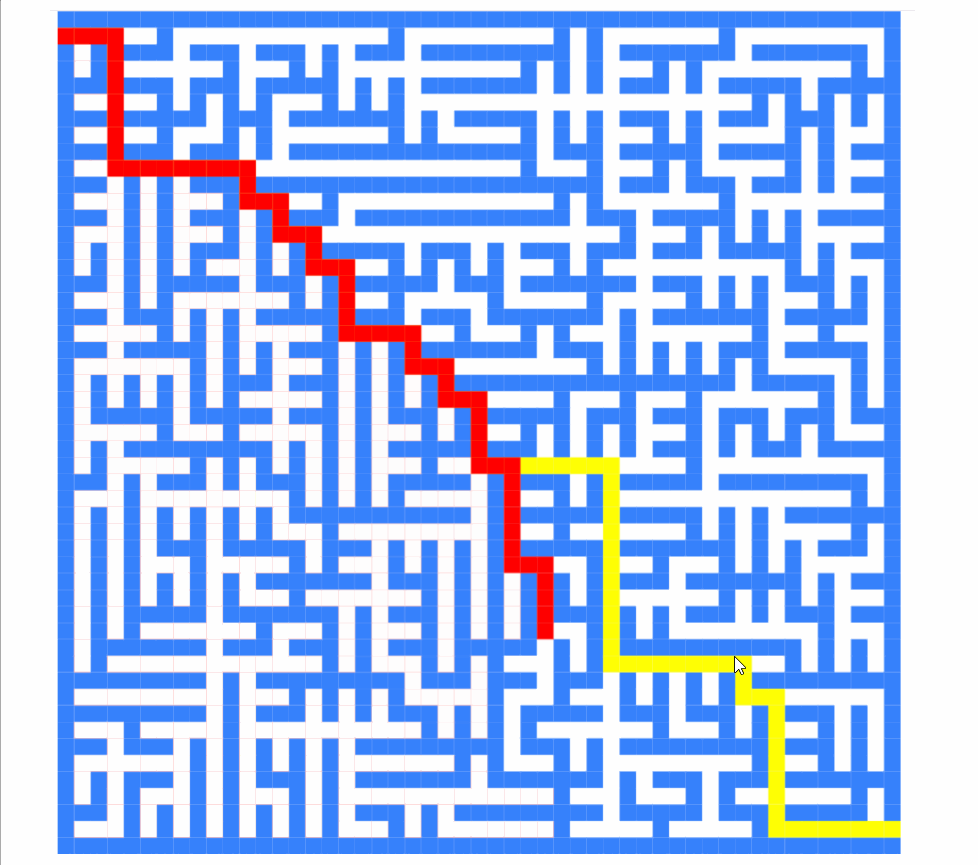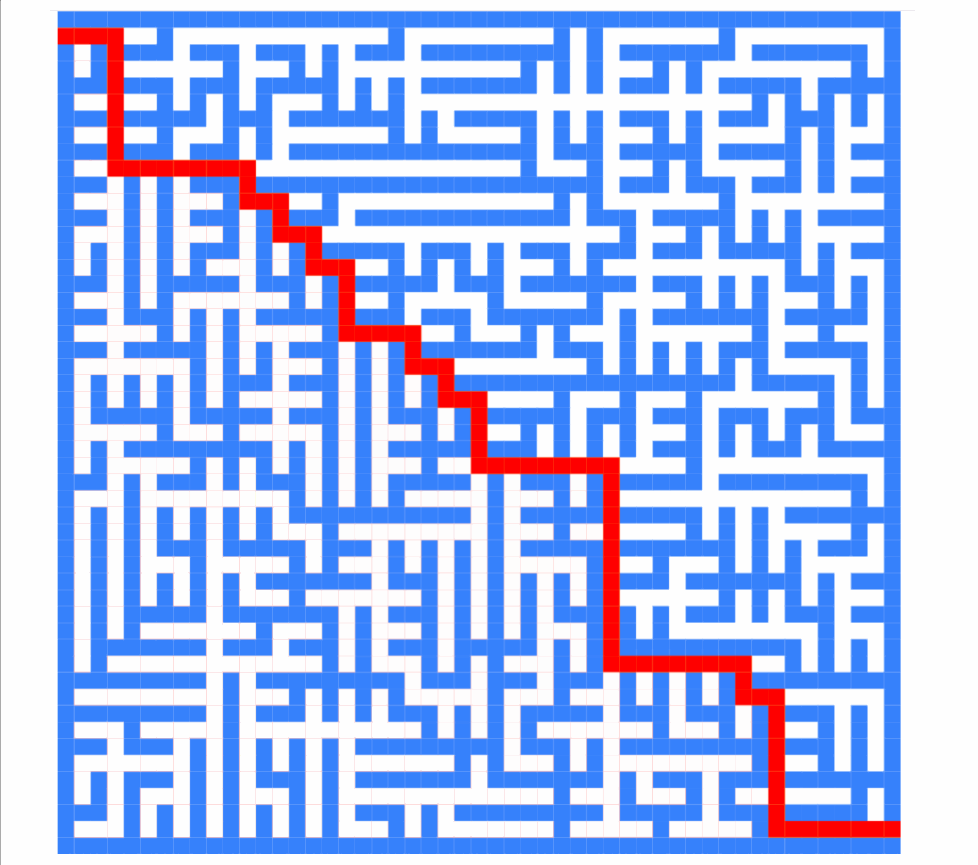
如您所见,算法求解的顺序完全不同。
深度优先搜索
在这种遍历算法中,它会先尝试一条路径,然后继续深入,直到到达死胡同或找到最终解决方案。如果遇到死胡同,将退回到上一点。这种遍历方法称为深度优先搜索,对应的还有广度优先搜索,后面的文章会讲到。
结论
好了,今天的内容迷宫,我们就先成功解到这里,我也把整个过程可视化了,希望这个对你学习算法内容有帮助,同时也希望通过这个案例,让你对深度优先搜索有了更直观的认识。
最后,如果你觉得今天的内容有用的话,请记得点赞我,关注我,并将它分享给你身边做开发的朋友,也许能够帮助到他。
感谢你的阅读,祝编程愉快!
学习更多技能
请点击下方公众号
![]()
