
某银行应用接地气的容器云平台是什么样子?

【作者】
彭尚峰,目前就职银行企业,深耕云计算领域多年,深度参与银行PaaS私有云建设与推广,拥有丰富的容器云平台设计和落地经验。
张少博,目前就职银行企业,从事云计算领域技术研究和技术支持工作。对Kubernetes高可用架构、Windows容器、云原生安全等有较深的理解,现致力于Operator的定制化开发工作。
郑宇光,目前就职银行企业,从事云计算领域相关技术研究、工程实施运维与技术支撑工作。任职期间主导完成云计算架构设计,制定容器云安全基线等指导性规范。

一、银行容器云平台建设的需求分析
伴随着 Docker 容器、Kubernetes、微服务、DevOps 等热门技术的兴起和逐渐成熟,利用云原生(Cloud Native)解决方案为企业数字化转型,已成为主流趋势。云原生解决方案通过使用容器、Kubernetes、微服务等这些新潮且先进的技术,能够大幅加快软件的开发迭代速度,提升应用架构敏捷度,提高 IT 资源的弹性和可用性,帮助企业客户加速实现数字化转型。通过容器技术搭建的云原生 PaaS(Platform-as-a-Service)平台,可以为企业提供业务的核心底层支撑,同时能够建设、运行、管理业务应用或系统,使企业能够节省底层基础设施和业务运行系统搭建、运维的成本,将更多的人员和成本投入到业务相关的研发上。
银行数字化转型的一大关键内容就是如何通过利用容器云平台为应用开发人员和基础设施建设运维人员赋能。除了利用容器云平台带来容器编排调度、故障自检自愈、资源弹性供给等基本能力外,还需要更加关注容器云平台的稳定性、安全性、以及如何融入已有开发运维体系。
二、银行容器云平台的总体架构设计
某银行容器云平台定位为以应用为中心的平台,总体上分为容器云平台和云管理平台两大部分,为跨服务器运行的容器化应用提供一站式完备的分布式应用系统开发、运行和支撑平台。平台内提供内建负载均衡、强大的故障发现和自我修复机制、服务滚动升级和在线扩容、可扩展的资源自动调度机制、多租户应用支撑、透明的服务注册、服务发现、多层安全防护准入机制、多粒度的资源配额管理能力,此外提供完善的管理工具,包括开发、测试、发布、运维监控。
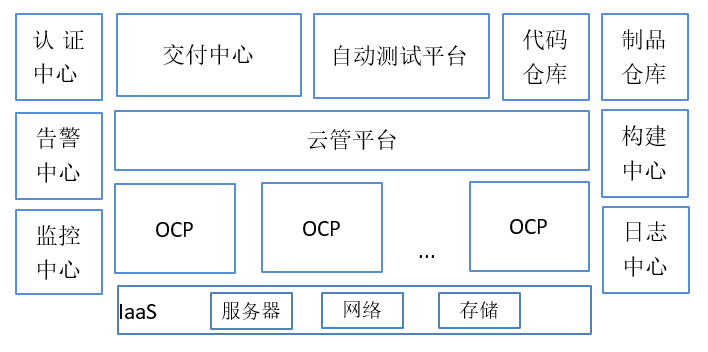
某银行容器云平台包含多个 Redhat Openshift Container Platform 集群,并通过云管理平台统一管理。使用行内IaaS提供的基础资源,通过对接项目管理系统实现自动化的资源分配,通过对接变更管理系统实现变更信息获取,通过对接行内代码库和依赖包仓库来实现代码的持续集成和镜像构建,同时对接行内的统一认证、统一日志、监控告警和应用管理平台来实现相应的认证、日志、监控和应用变更功能。
Openshift基于英特尔®至强®可扩展处理器、英特尔®傲腾™固态盘等硬件产品,针对虚拟化、大数据和人工智能工作负载进行性能验证和优化,可支持裸机或者虚拟机。英特尔®傲腾™固态盘在SSD设备加入了新的存储层,能够提升存储层持久化的效率和可靠性。
OpenShift容器云单集群主要由Master管理节点、Slave计算节点及其他功能节点组成,其配置样例如下:
角色 | 最小数量 | 单节点配置 | 资源类型 | 操作系统 | 结构 |
控制台操作机 | 1 | 4C 8G | 虚拟机 | RHEL 7.5 | 单机多用户 |
Master管理节点 | 3 | 8C 16G | 虚拟机 | RHEL 7.5 | 奇数,1主多从 |
Master软负载 | 2 | 4C 8G | 虚拟机 | RHEL 7.5 | 双机,1主1备 |
路由 | 3 | 8C 16G | 虚拟机 | RHEL 7.5 | 多活 |
路由软负载 | 2 | 4C 8G | 虚拟机 | RHEL 7.5 | 双机,1主1备 |
监控 | 3 | 8C 32G | 虚拟机 | RHEL 7.5 | 多活 |
日志 | 3 | 8C 32G | 虚拟机 | RHEL 7.5 | 多活 |
镜像仓库 | 2 | 8C 16G | 虚拟机 | RHEL 7.5 | 双活互备 |
镜像仓库软负载 | 2 | 8C 16G | 虚拟机 | RHEL 7.5 | 双机,1主1备 |
YUM源 | 1 | 4C 8G | 虚拟机 | RHEL 7.5 | 单机 |
文件服务器 | 1 | 4C 8G | 虚拟机 | RHEL 7.5 | 单机 |
DNS服务器 | 2 | 4C 8G | 虚拟机 | RHEL 7.5 | 双活互备 |
Slave计算节点 | ≥3 | 32C 64G | 虚拟机/物理机 | RHEL 7.5 | 多活,由Master管理调度 |
以上是一个经典的Openshift容器云集群配置案例,所有节点均可以采用虚拟机方案,但不同角色节点对应的资源配置量不同,搭配起来可以充分利用资源,其中计算节点也可以使用Intel x86物理机,在日常运维过程中,计算节点扩充频率最高,其次是路由节点,是自动化运维的重要管理内容。
某银行随着容器云平台的引入,经过几年的蓬勃发展,平台规模日益扩大,当前容器云平台已建设超过30个集群,容器总数上万个。已经承载行内接近200个应用系统,包括使用资源需求庞大的AI平台系统、“双11”期间峰值TPS超1.1万的消息服务系统、日均千万笔交易的金融交易系统等。
三、容器云平台运维痛点
随着容器云平台建设规模的增长和使用场景的增多,容器云平台运维方面逐步显露出了很多全新的问题与挑战,由于容器技术本身与传统虚拟机技术存在一定的差别,容器云平台中使用自治网络用于容器通信,而且容器的调度由平台完成,容器的IP分配等场景无法人为地进行干预,以往针对虚拟机的运维管理经验不能有效覆盖平台化的容器场景。以下针对某银行这几年在容器云平台运维方面存在的痛点作一些说明。
(1)资产信息无法有效聚合。某银行建设容器云的思路是按照网络分区部署容器云平台。一方面考虑平台规模可以做到分区控制,避免超大规模平台的出现;另一方面依托现有的网络分区安全管理制度,有效抑制跨区带来的网络安全问题。最后在每一个网络区域部署一套容器云平台,容器云平台做到不跨区。由于行内的各应用系统等级保护要求不一样,需要在各个不同的等保网络区独立部署容器云平台来承载行内应用,容器云平台数量在不断地增加,建设初期对平台中各项资源收集整合就成为一项繁重的工作,没有配置管理无法有效做到各平台资产信息的集中可视化展示,包括平台内节点数量、节点名称、节点角色、节点IP、节点配置、平台内承载应用等信息。不仅导致周期性统计工作量的上升,而且容器云的资产定义与现有其他平台对资产的定义标准不统一,不利于其他平台与容器云平台整体联动,扩展性也不尽如人意。
(2)运维复杂度与平台规模呈正相关性。上一点已经提到,容器云平台规模的扩张不但使资产信息统计工作量上升,而且针对平台的运维工作量也出现井喷之势。容器云的运维工作大致可以分为两类,一类是日常维护工作,包括平台例行巡检、平台容量扩容、安全加固、组件更新、交付应用账户及相应的授权等;另一类是应急处置工作,包括故障应急处理、例行应急演练等。当承载容器云平台的总节点数超过一定规模后,尤其是日常维护工作如果不采用自动化处理会变得非常繁重,与此同时由于运维人员技术水平参差不齐,传统手工运维往往难以高效执行,出错率也变的很高。
(3)容器云平台运行监控数据不完善,不能有效获取平台运行状态,资源管控能力薄弱。容器云平台对底层服务器进行整合并形成弹性资源池,在没有一套完整的监控体系下,对容器云平台的状态掌握无异于盲人摸象,虽然可以通过原有的虚拟机监控方法人工统计容器云平台的整体负载情况,但实时性和针对性差。
(4)突发的大量资源交付周期长。在我们的实际工作中会出现某一季度或者某一个业务条线出现大量上云的应用,现有平台资源剩余量无法承载的情况。这种情况的发生虽然跟业务激增有一定的关系,但更多的问题是在不能实时掌握平台运行状态、不能对资源消耗情况进行追踪,不能自动化开展高效资源交付。
(5)异常事件跟踪能力薄弱。这部分能力主要依靠告警和日志查询功能来实现,在建设初期,往往还没有建立起一套完善的监控告警机制来实现及时精确的告警,各个容器云集群的日志没有做到统一收集,通常是云上应用系统的业务发生异常后,才向平台运维方申请排查,在没有准确的告警及日志的帮助下无法第一时间定位问题点,排查耗时长且响应不及时。
四、容器云平台自动化运维的实现
自动化运维是容器云平台建设中期开始逐步完善的,大概分为五块内容:配置管理、监控告警、自动发布、流程管理、批量执行。
配置管理分为两部分,一是平台级的配置信息管理,体现在平台所在区域、平台节点数量、平台节点角色等信息的采集入库,并通过统一视图进行展示;二是平台内的应用容器的信息采集入库,包括应用系统名称、应用系统容器镜像版本、应用容器IP地址、应用容器运行环境等信息。
监控告警分为四块,一是资源监控,包括平台资源总量、己使用量、可分配量;二是系统监控,包括节点级CPU/内存/磁盘实际使用率、平台流量入口业务请求速率、节点就绪状态等,并通过设置安全阈值在异常时触发告警;三是业务监控,包括应用系统数量统计、运行应用容器数量、项目资源配额、项目维度容器实际CPU/内存使用率、应用容器异常状态告警等;四是日志监控,主要体现在日志的集中采集分析。CPU资源监控需要适应容器环境的特点,具备灵活性和自动化。
自动发布针对是云上应用系统,通过CICD支持应用的自动发布及回滚。
流程管理体现在利用工单系统、标准流程实现资源的按期交付,应用投产上线流程标准化。
批量执行将繁琐的平台巡检工作、平台扩容工作利用自动化工具实现批量执行,缩短周期,提高整体效率,减少人工成本。
基于容器云平台本身所带来的好处以及其高效性、灵活性的特点,某银行设计了一套针对容器云平台的自动化运维架构。容器云平台本身针对应用开发团队来说已经实现了所测即所投、应用快速发布、应用健康检查、应用故障自愈、基于持续交付系统的自动发布等能力。自动化运维所做的更多是偏向平台运维本身,大致内容如下。
(1) 建设云管平台。云管平台建设的目的在于,一方面纳管所有的容器云平台,通过标准Kubernetes API进行纳管,云管平台中记录各容器云平台网络分区信息、节点数量、应用项目相关信息等并通过统一视图进行展示,基于这些信息组成一套容器云平台的CMDB。另一方面提供统一API接口供外部系统调用,后续新建设的容器云平台信息由云管平台API进行封装,提高可扩展性。同时实现统一用户认证、权限集中控制和审计,满足管理要求。
(2)对接配置管理系统(CMDB)。除了云管平台自身的CMDB外,行内配置管理系统通过云管平台API遍历所有容器云平台的应用系统配置信息并入库,包括应用系统名称、应用系统容器镜像版本、应用容器IP地址、应用容器运行环境、应用项目组管理成员等信息。通过完善的配置信息管理可以快速定位故障应用的相关属性。
(3)建立统一用户体系。云管平台通过对接行内统一用户平台实现单点登录,这样做的好处是:首先应用项目成员可以完成自行登录,不需要容器云平台侧进行用户分配;其次可以实现基于用户角色的权限绑定并进行操作审计;最后可以基于真实用户实现和其他平台之间的联动,比如外部的交付平台。
(4)对接日志中心。在所有容器云平台的节点上部署日志采集工具对接行内日志中心,通过日志中心实现日志集中查询分析。
(5)建立监控体系。监控体系由容器云平台监控系统和行内监控中心组成。监控系统我们采用Prometheus监控组件和Grafana监控展示组件,对监控指标、告警规则和展示面板进行定制开发,各容器云平台分别对接行内监控中心,将结构化监控数据及告警规则传递至监控中心,整体实现了资源监控、系统监控、业务监控,异常事件短信告警。提升异常事件跟踪、资源管控能力,并且根据资源使用率的监控可以提前对资源枯竭进行预警,提前完成节点扩容,缩短资源交付周期。基础设施资源建议选择能够支持开源主流监控技术栈的产品,包括CPU、内存、磁盘等等,例如英特尔云原生 Telemetry Software Stack 技术支持一系列信息采集、监控、展示组件 (Collectd, Prometheus, node-exporter, Grafana)。
(6)批量执行工具。平台巡检、平台扩容等操作固化、频繁的工作采用自研 Ansible playbook 结合 Openshift 本身的 Ansible playbook 合并成一个自动化工具,可以实现一键化完成平台巡检并生成巡检报告、平台扩容前针对虚拟机的准备工作、执行平台扩容等内容。直接缩短维护时间、降低使用技术门槛,提高运维效率。
(7)流程管理。目前有两套流程,一个是围绕应用项目自动发布的,另一个是应对容器云平台故障应急的。应用项目自动发布流程基于DevOps流程,行内代码仓库、交付中心对接云管平台,各容器云平台对接制品仓库,结合投产工单系统整体实现从源码到镜像制品再到自动发布的应用构建发布流水线,其中包含代码基线管理、应用代码单元测试、应用镜像制品晋级管理等管理流程,能够使应用项目组自行完成应用的快速交付。容器云平台故障应急流程则是通过行内监控中心派单机制结合行内应急故障处置流程来实现,监控中心会根据容器云平台监控系统报送的监控数据和告警规则来决策故障事件等级并下发告警短信通知,如果等级过高则触发应急故障处理流程,值班人员根据容器云平台应急手册中命中的场景展开应急处置工作。这里需要注意的一个问题就是应急手册场景要细、操作步骤可靠可行,现有的这套流程提高了容器云平台应急事件处理的效率,大大缩短了应急响应时间。
五、实现自动化运维带来的效果及总结
通过基于OpenShift的自动化运维机制,并与行内科技管理、配置、应用支持等系统对接,很好地支撑了资源量大、并发量高的应用场景,同时稳定地支持了行内重要交易系统的运行。基于容器云平台的自动化运维主要带来了如下三方面好处:一是为开发人员减负、聚焦于业务功能实现和创新,实现分钟级的应用快速部署,提升应用研发和运维效率;二是实现云上应用的全生命周期管理,提供了应用运行全景视图;三是实现资源按需自动供给、弹性扩容、空闲自动回收,资源使用效率提升三倍以上。
容器云平台在某银行的应用已经日渐成熟,其作为容器化底座的基础平台,今后将为基于Service Mesh的微服务治理平台、基于Serverless的应用开发平台提供有力的保障。

欢迎点击文末阅读原文,到社区提问讨论