迈向目标跟踪大统一:一个模型解决所有主流跟踪任务,8项基准出色
机器之心报道
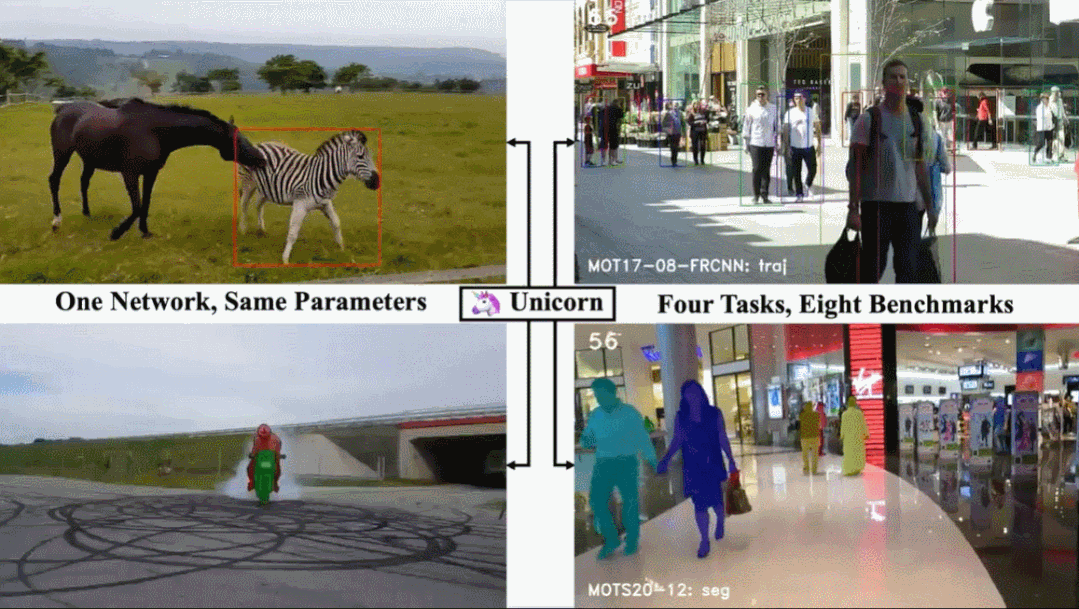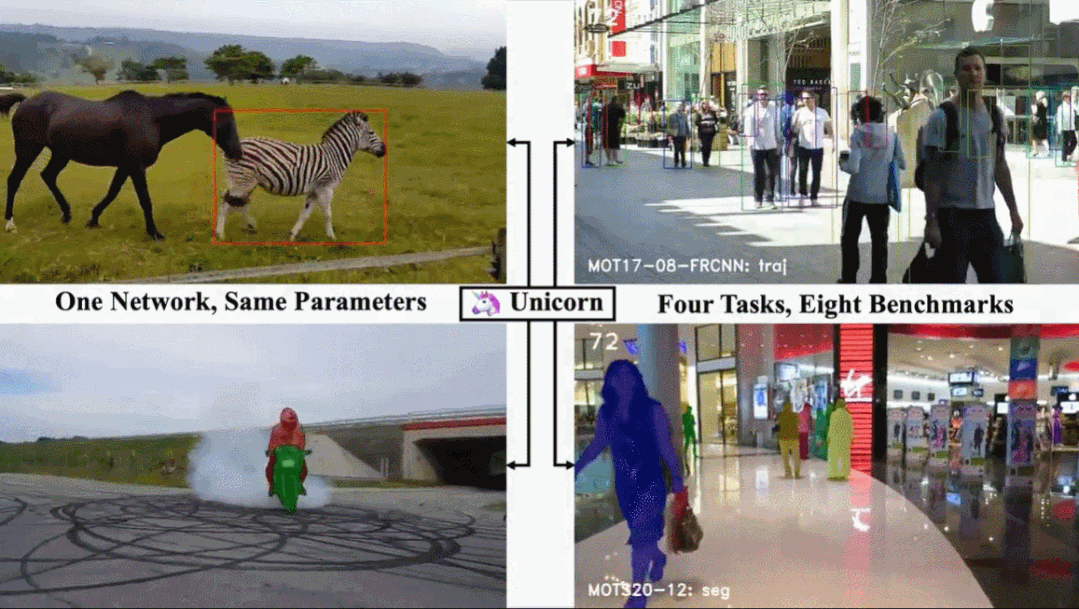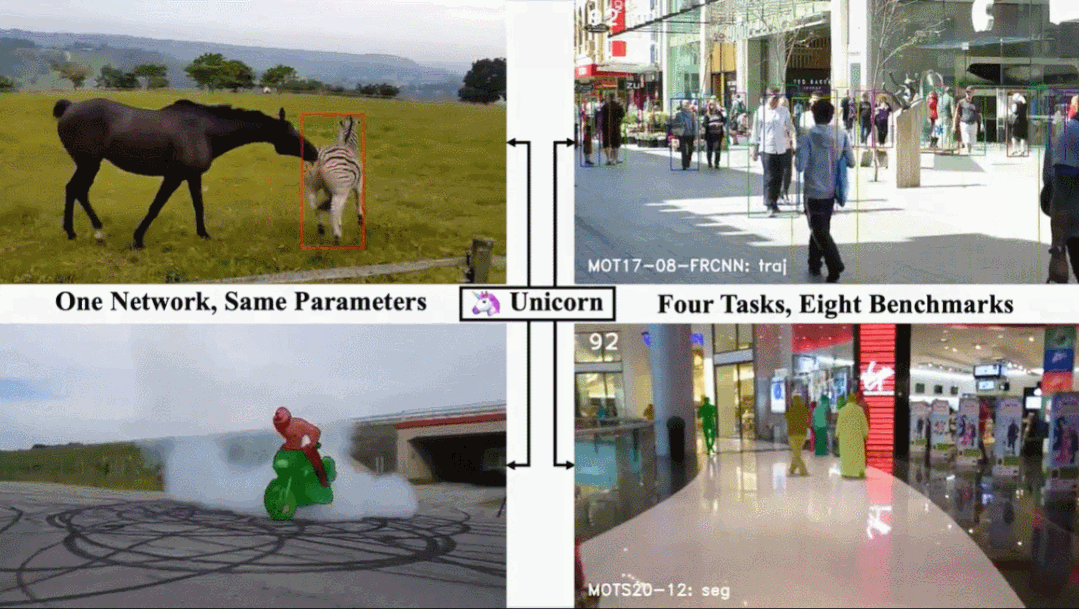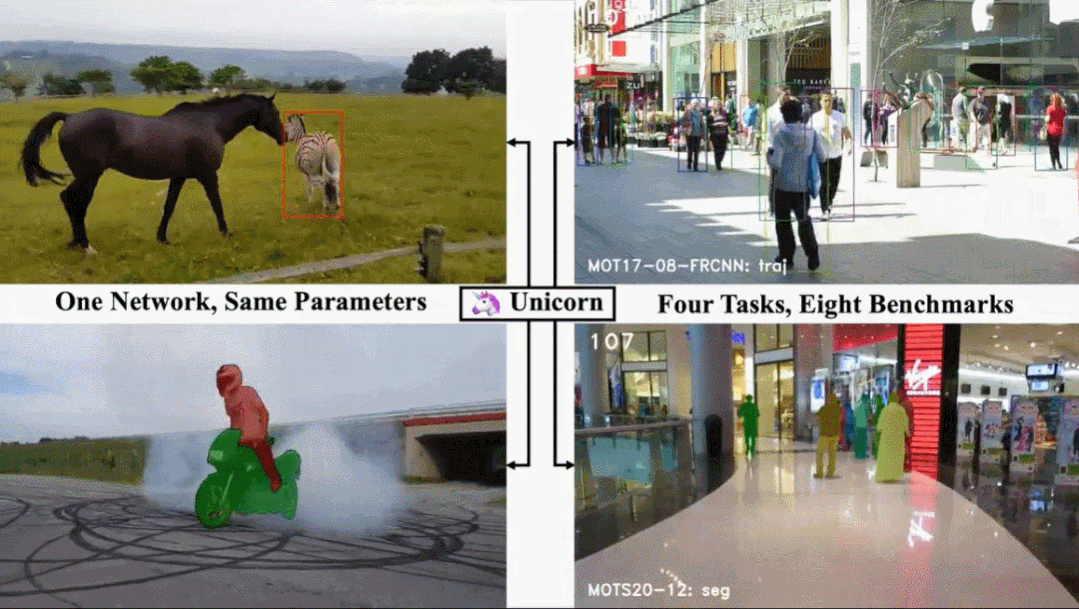
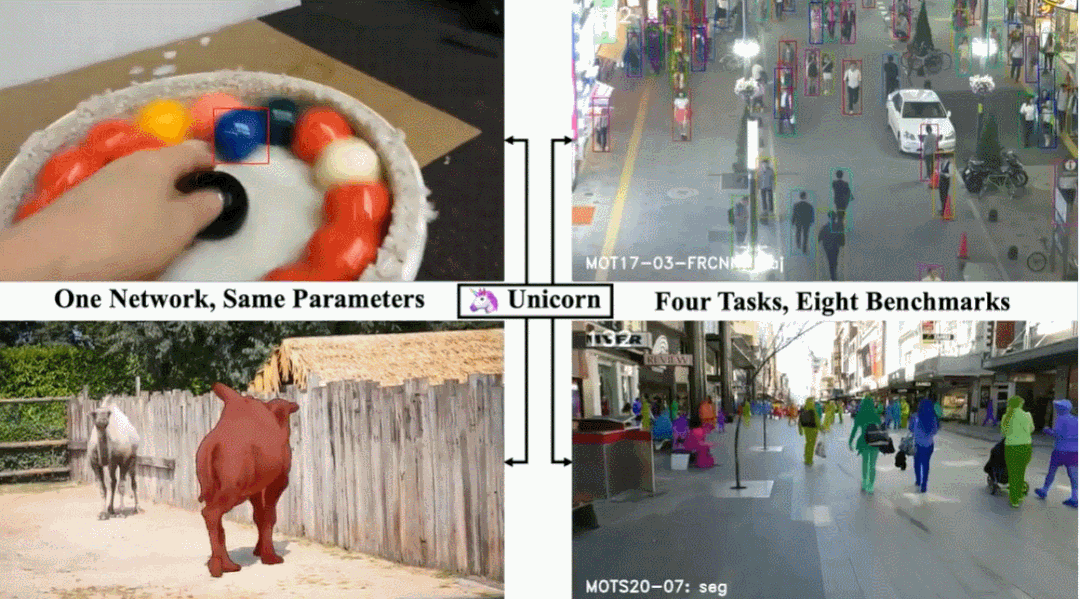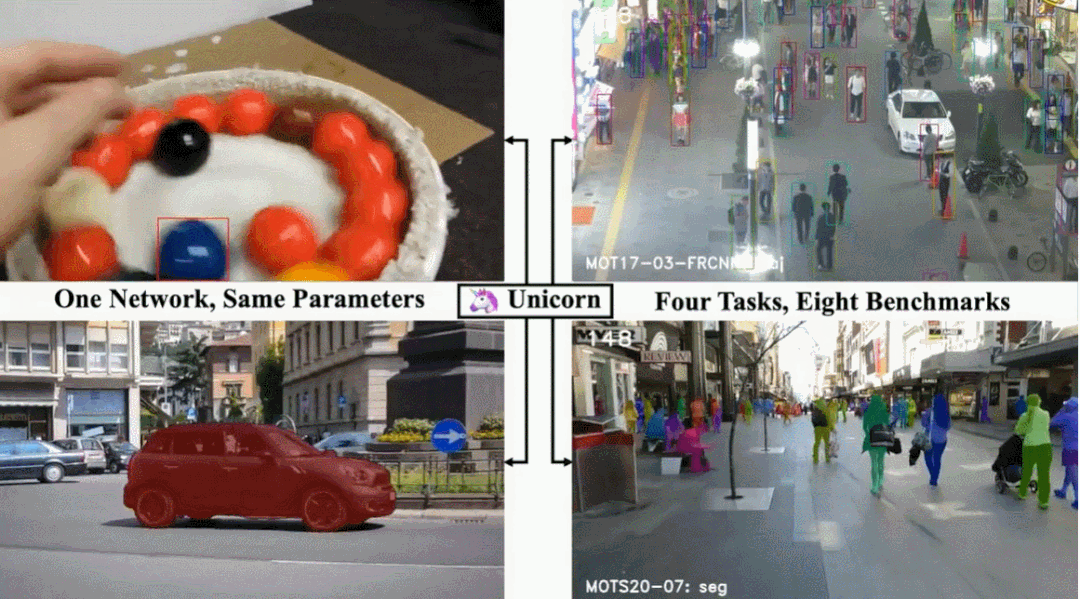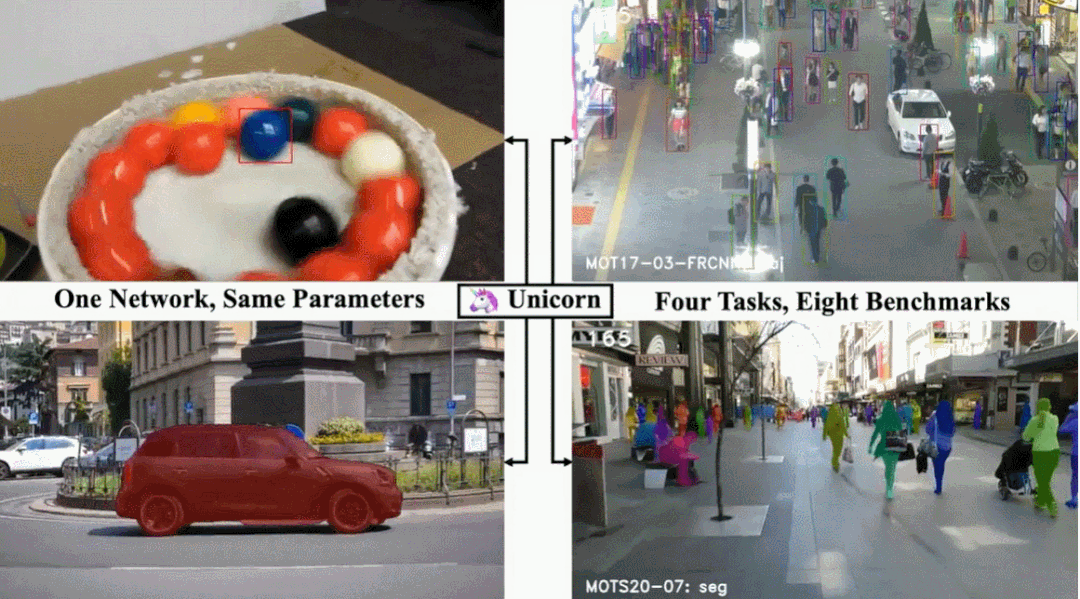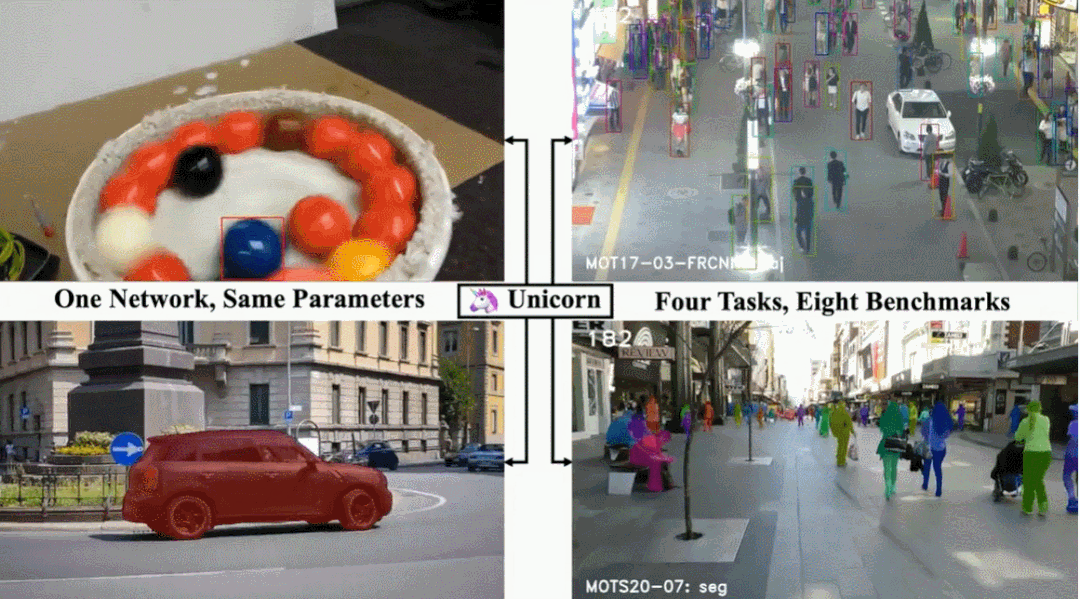
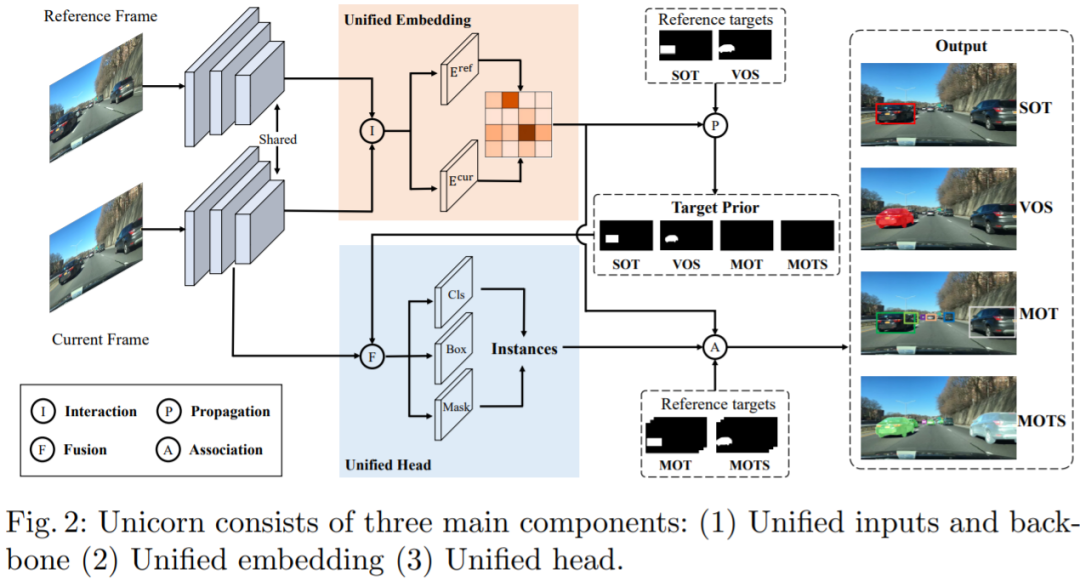
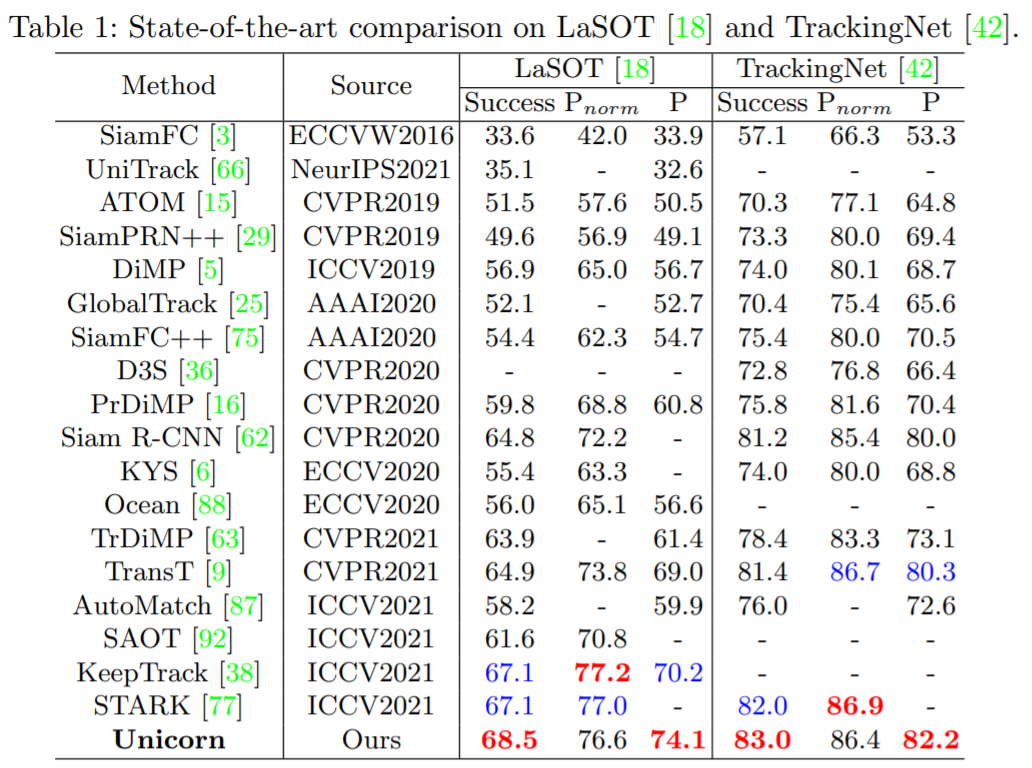
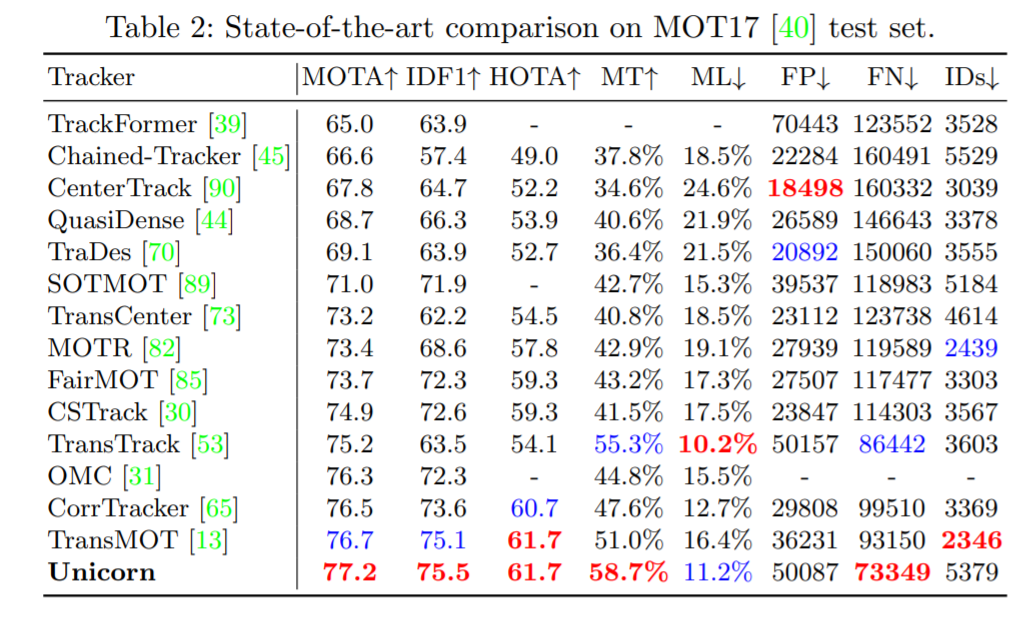
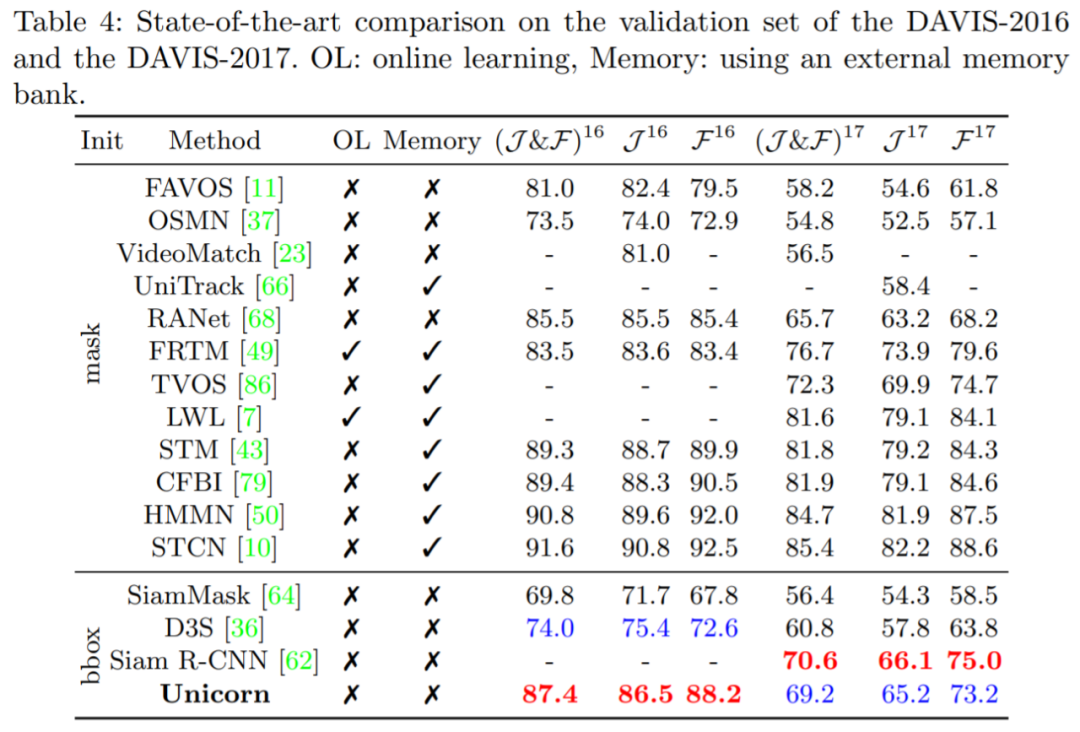
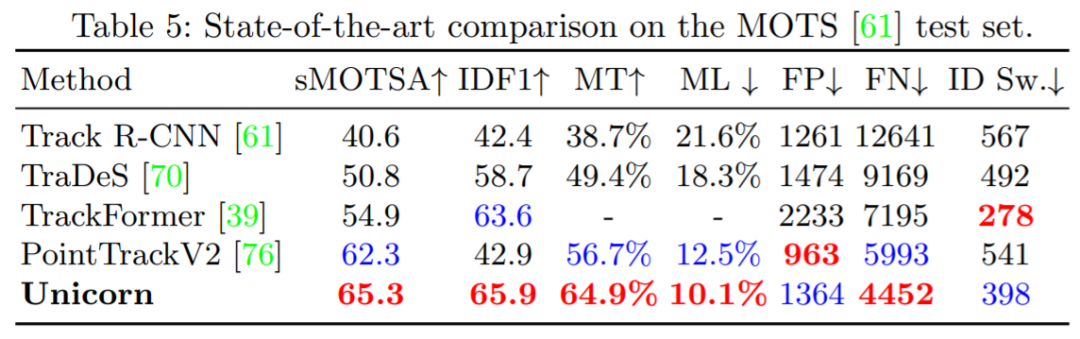
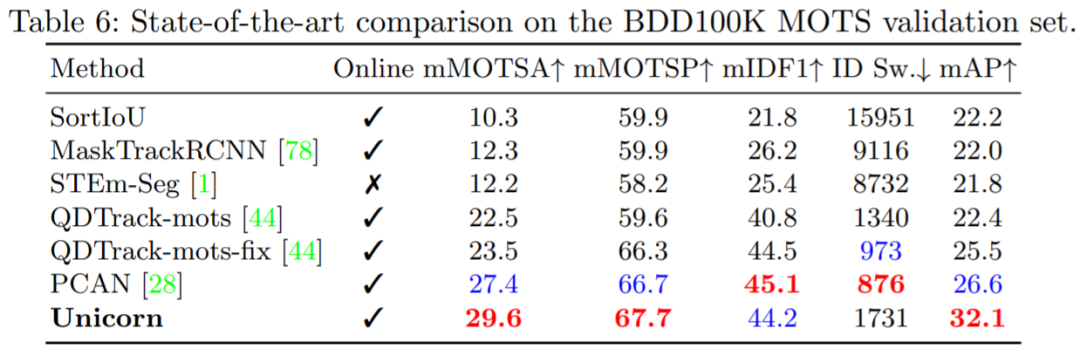
单目标跟踪、多目标跟踪、视频目标分割、多目标跟踪与分割这四个任务,现在一个架构就搞定了。

论文地址:https://arxiv.org/pdf/2207.07078.pdf 项目地址:https://github.com/MasterBin-IIAU/Unicorn

——The End——

分享
收藏
点赞
在看
评论
 下载APP
下载APP机器之心报道
单目标跟踪、多目标跟踪、视频目标分割、多目标跟踪与分割这四个任务,现在一个架构就搞定了。
——The End——
分享
收藏
点赞
在看