
小模型大趋势!Google 提出两个逆天模型:体积下降7倍,速度提升10倍
新智元报道
新智元报道
来源:Google AI
编辑:LRS
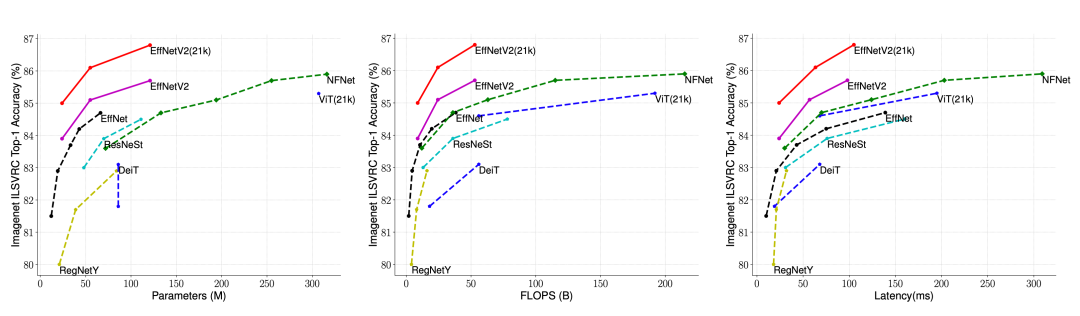
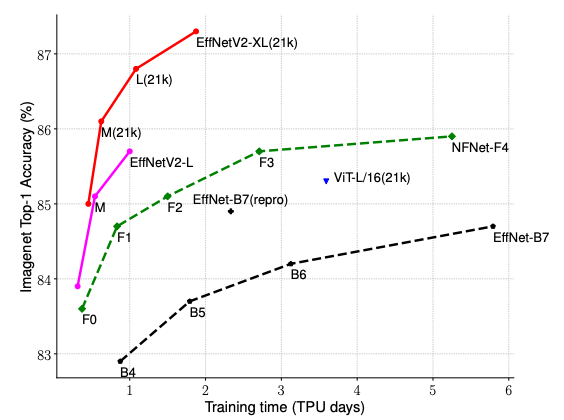
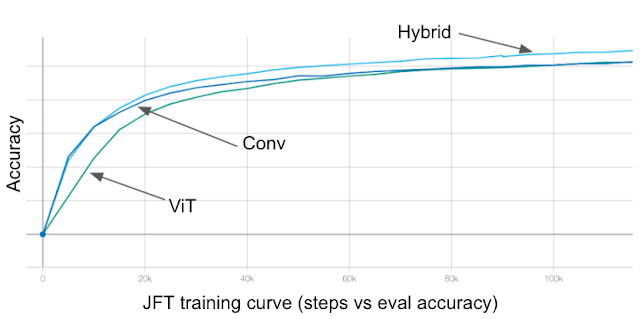
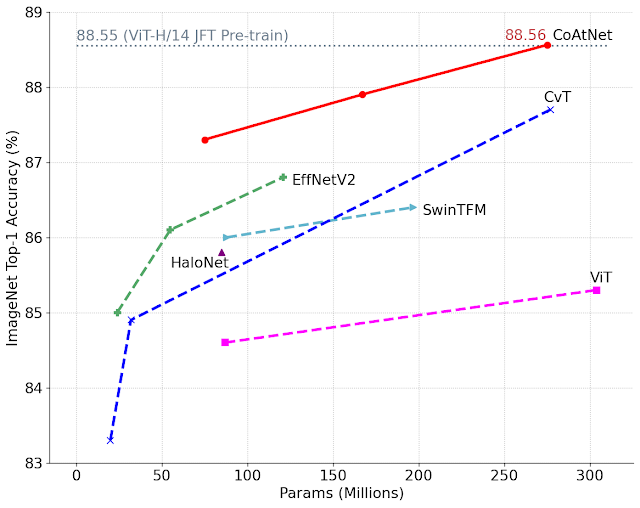
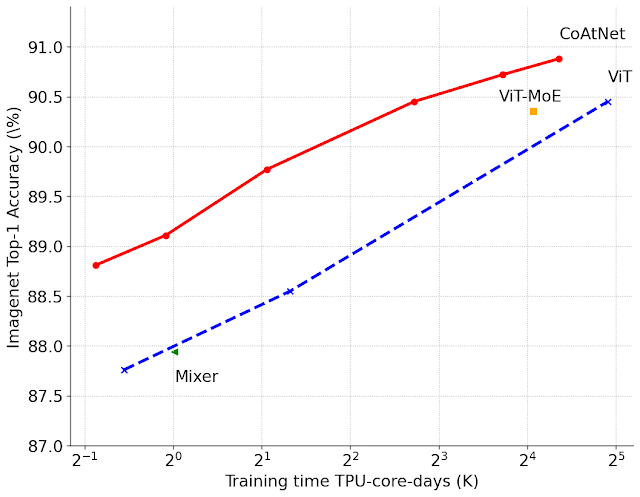
【新智元导读】模型在更小、更快和更准之间矛盾吗?能同时达到这几个效果吗?Google Research提出两个模型EfficientNetV2和CoAtNet,竟然同时做到了这三点,模型下降7倍,训练速度提升10倍,还能拿到sota!




参考资料:
https://ai.googleblog.com/2021/09/toward-fast-and-accurate-neural.html?m=1

评论