
利用pandas模块处理学生成绩
说在前面

利用pandas模块处理学生成绩
已有素材:存储了学生成绩信息的csv文件“stu_info.csv”。
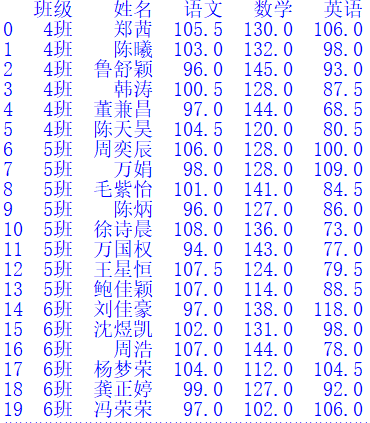
class_name = [] #存储班级名称stu_name = [] #存储学生姓名cn_score = [] #语文成绩math_score = [] #数学成绩en_score = [] #英语成绩with open("stu_info.csv", "r", encoding='utf-8') as file:num = 0for line in file: #获取每一行的数据num += 1if num == 1: #丢弃第一行标题continuetemp = line.strip().split(",")class_name.append(temp[0])stu_name.append(temp[1])cn_score.append(float(temp[2]))math_score.append(float(temp[3]))en_score.append(float(temp[4]))#使用字典构造包含了班级、姓名和各科成绩列的DataFrame对象(不含标题)data = {"班级":class_name, "姓名":stu_name, "语文":cn_score, "数学":math_score, "英语":en_score}df = pd.DataFrame(data) #构造DataFrame对象print(df)
输出结果如下:
#逐行计算各学生总分,并增加“总分”列df["总分"] = 0.0 #试试将值改为0看看for r in df.index:df.at[r,"总分"] = sum(df.loc[r,["语文", "数学", "英语"]])#rank()函数的应用:根据总分排名,并增加“排名”列df['排名'] = df['总分'].rank(ascending=False)print(df)
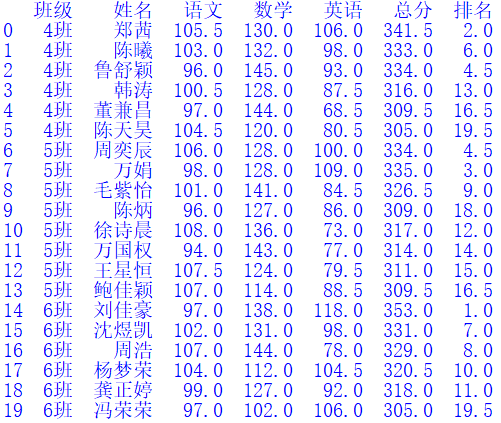
df.sort_values("总分", ascending=False, inplace=True) #根据人数降序排序print(df)
输出结果如下:

print(df[df["姓名"]=="周奕辰"])print(df[(df["语文"]>105) | (df["数学"]>135)])print(df[(df["语文"]>100) & (df["英语"]>100)])print(df[(df["语文"]>100) & (df["英语"]>100)].count()) #输出满足条件的学生数量

五、对pandas DataFrame对象做分组和聚合操作
groupby()函数的应用:将数据按“班级”分组,计算每个班级各有多少人,或计算各班平均分。代码如下:
class_df = df.groupby("班级").count() # 按关键词分组计数class_df.sort_values('姓名', ascending=False, inplace=True) #根据人数降序排序print(class_df)print("#" * 50)#将数据按“班级”分组,计算各班平均分ave_df = df.groupby("班级").mean()print(ave_df)
输出结果如下:

需要本文PPT、源代码和课后练习答案的,可以加入“Python算法之旅”知识星球参与讨论和下载文件,“Python算法之旅”知识星球汇集了数量众多的同好,更多有趣的话题在这里讨论,更多有用的资料在这里分享。
我们专注Python算法,感兴趣就一起来!
相关优秀文章:
评论