
python分析春节档票房黑马《发财日记》,探索没上映却收获4亿票房的奥秘
看了半天电影,发现宋小宝的处女座《发财日记》才是春节档的票房黑马!

这部电影没在电影院上映,而是选择在腾讯视频首播(需付费),目前播放量是七千多万,单轮播放量的话,妥妥的第一名
今天,我从电影弹幕入手,和大家一起分析一下这部电影的看点在哪?
首先,我用python爬取了电影的所有弹幕,这个爬虫比较简单,就不细说了,直接上代码:
import requests
import pandas as pd
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
}
url = 'https://mfm.video.qq.com/danmu?otype=json&target_id=6480348612%26vid%3Dh0035b23dyt'
# 最终得到的能控制弹幕的参数是target_id和timestamp,tiemstamp每30请求一个包。
comids=[]
comments=[]
opernames=[]
upcounts=[]
timepoints=[]
times=[]
n=15
while True:
data = {
"timestamp":n}
response = requests.get(url,headers=headers,params=data,verify=False)
res = eval(response.text) #字符串转化为列表格式
con = res["comments"]
if res['count'] != 0: #判断弹幕数量,确实是否爬取结束
n+=30
for j in con:
comids.append(j['commentid'])
opernames.append(j["opername"])
comments.append(j["content"])
upcounts.append(j["upcount"])
timepoints.append(j["timepoint"])
else:
break
data=pd.DataFrame({'id':comids,'name':opernames,'comment':comments,'up':upcounts,'pon':timepoints})
data.to_excel('发财日记弹幕.xlsx')
首先用padans读取弹幕数据
import pandas as pd
data=pd.read_excel('发财日记弹幕.xlsx')
data
近4万条弹幕,5列数据分别为“评论id”“昵称”“内容”“点赞数量”“弹幕位置”
将电影以6分钟为间隔分段,看每个时间段内弹幕的数量变化情况:
time_list=['{}'.format(int(i/60))for i in list(range(0,8280,360))]
pero_list=[]
for i in range(len(time_list)-1):
pero_list.append('{0}-{1}'.format(time_list[i],time_list[i+1]))
counts=[]
for i in pero_list:
counts.append(int(data[(data.pon>=int(i.split('-')[0])*60)&(data.pon'-')[1])*60)]['pon'].count()))
import pyecharts.options as opts
from pyecharts.globals import ThemeType
from pyecharts.charts import Line
line=(
Line({"theme": ThemeType.DARK})
.add_xaxis(xaxis_data=pero_list)
.add_yaxis("",list(counts),is_smooth=True)
.set_global_opts(
xaxis_opts=opts.AxisOpts(axislabel_opts=opts.LabelOpts(rotate=-15),name="电影时长"),
title_opts=opts.TitleOpts(title="不同时间弹幕数量变化情况"),
yaxis_opts=opts.AxisOpts(name="弹幕数量"),
)
)
line.render_notebook()
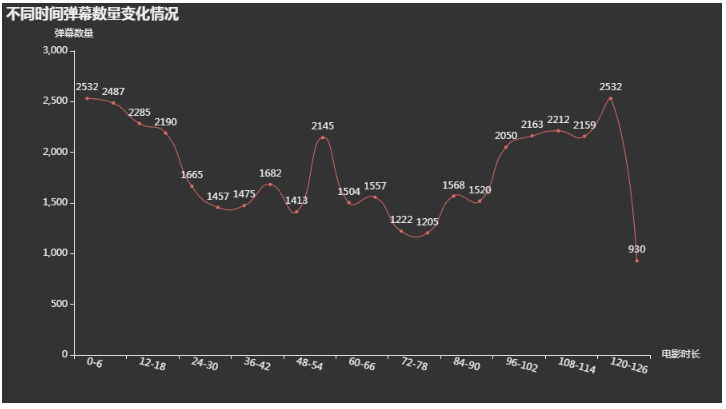
从弹幕数量变化来看,早60分钟、120分钟左右分别出现2个峰值,说明这部电影至少有2个高潮
为了满足好奇心,我们一起分析一下前6分钟(不收费)以及2个峰值大家都在说什么
1.看看前六分钟大家在说什么:
#词云代码
import jieba #词语切割
import wordcloud #分词
from wordcloud import WordCloud,ImageColorGenerator,STOPWORDS #词云,颜色生成器,停止
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
from pyecharts import options as opts
def ciyun(content):
segment = []
segs = jieba.cut(content) # 使用jieba分词
for seg in segs:
if len(seg) > 1 and seg != '\r\n':
segment.append(seg)
# 去停用词(文本去噪)
words_df = pd.DataFrame({'segment': segment})
words_df.head()
stopwords = pd.read_csv("stopword.txt", index_col=False,
quoting=3, sep='\t', names=['stopword'], encoding="utf8")
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
words_stat = words_df.groupby('segment').agg(count=pd.NamedAgg(column='segment', aggfunc='size'))
words_stat = words_stat.reset_index().sort_values(by="count", ascending=False)
return words_stat
data_6_text=''.join(data[(data.pon>=0)&(data.pon<360)]['comment'].values.tolist())
words_stat=ciyun(data_6_text)
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
words = [(i,j) for i,j in zip(words_stat['segment'].values.tolist(),words_stat['count'].values.tolist())]
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="{}".format('前6分钟')))
)
c.render_notebook()

排名第一的是“小宝”,还出现了“好看”“支持”等字样,看来还是小宝还是挺受欢迎的
2.第一个高潮:
data_60_text=''.join(data[(data.pon>=54*60)&(data.pon<3600)]['comment'].values.tolist())
words_stat=ciyun(data_60_text)
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
words = [(i,j) for i,j in zip(words_stat['segment'].values.tolist(),words_stat['count'].values.tolist())]
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="{}".format('第一个高潮')))
)
c.render_notebook()

排在前面的分别是“小宝”“二哥”“哈哈哈”“好看”等,说明肯定是小宝和二哥发生了什么搞笑的事
3.第二个高潮:
data_60_text=''.join(data[(data.pon>=120*60)&(data.pon<128*60)]['comment'].values.tolist())
words_stat=ciyun(data_60_text)
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
words = [(i,j) for i,j in zip(words_stat['segment'].values.tolist(),words_stat['count'].values.tolist())]
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="{}".format('第二个高潮')))
)
c.render_notebook()

高频词中,发现“好看”“泪点”“哭哭”等字样,说明电影的结尾很感人
我们接着再挖一下发弹幕最多的人,看看他们都在说什么,因为部分弹幕没有昵称,所以需要先踢除:
data1=data[data['name'].notna()]
data2=pd.DataFrame({'num':data1.value_counts(subset="name")}) #统计出现次数
data3=data2.reset_index()
data3[data3.num>100] #找出弹幕数量大于100的人
data_text=''
for i in data3['name'].values.tolist():
data_text+=''.join(data[data.name==i]['comment'].values.tolist())
words_stat=ciyun(data_text)
from pyecharts import options as opts
from pyecharts.charts import WordCloud
from pyecharts.globals import SymbolType
words = [(i,j) for i,j in zip(words_stat['segment'].values.tolist(),words_stat['count'].values.tolist())]
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="{}".format('粉丝弹幕')))
)
c.render_notebook()

这评价,真是杠杠的!
看来票房高也不是白来的,既有笑点又有泪点,说明小宝的处女座很成功!欠他一张电影票。
评论