
假设检验在数据分析中的应用
前言
Z检验
T检验
独立样本t检验
配对样本t检验
单样本t检验
前言
在这篇文章中,我不会具体去推导检验统计量和相应拒绝域的得出,这对于大部分非统计学专业的人士来说是晦涩的,我只想通过一个案例告诉大部分初学者假设检验怎么在数据挖掘中使用。
%matplotlib inline
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import seaborn as sns
from scipy import stats
from statsmodels.stats import weightstats as mstats
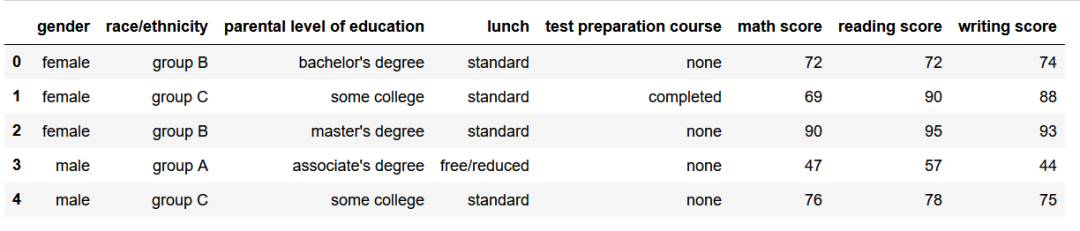
df_exams = pd.read_csv('./StudentsPerformance.csv')
df_exams.head()
df_exams.rename(columns={'race/ethnicity':'ethnicity'},inplace=True)
df_exams.rename(columns={'parental level of education':'parents_education'},inplace=True)
df_exams.rename(columns={'test preparation course':'test_prep_course'},inplace=True)
df_exams.rename(columns={'math score':'math_score'},inplace=True)
df_exams.rename(columns={'reading score':'reading_score'},inplace=True)
df_exams.rename(columns={'writing score':'writing_score'},inplace=True)
查看前5行的信息
df_exams.head()

接下来查看类别型数据是否均匀,数值型数据是否服从正态分布。
df_exams['ethnicity'].value_counts()
group C 319
group D 262
group B 190
group E 140
group A 89
Name: ethnicity, dtype: int64
以宗族信息这一列为例,可以看出C的占比较重,group A 只有89例。这也就说明当选择从每个group抽取80个样本是不合适的,因为这对A来说每次抽取,样本信息几乎没有发生什么变化。
exams = ['math_score','reading_score','writing_score']
for exam in exams:
y = df_exams[exam]
plt.figure(1); plt.title('Normal')
sns.distplot(y, kde=False, fit=stats.norm)
plt.figure(2); plt.title('Johnson SU')
sns.distplot(y, kde=False, fit=stats.johnsonsu)
fig = plt.figure()
res = stats.probplot(df_exams[exam], plot=plt)
plt.show()

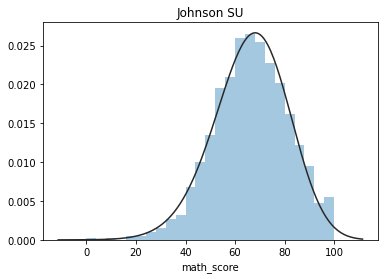
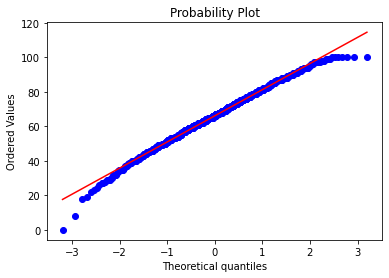




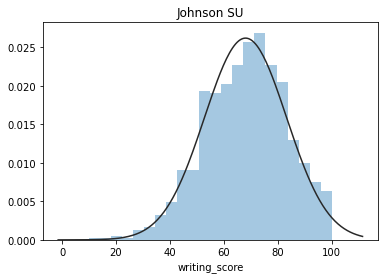
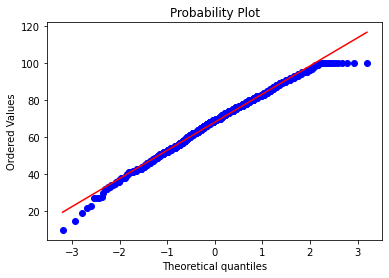
这些图片说明数据并不是完全服从正态分布,密度函数的尾部与正态分布有些偏离,但大体还是可以认为近似服从正态分布的,如果数据不服从正态分布,Z检验和T检验将是无法使用的。到目前为止请注意,我们用的都是全部的数据哟,而假设检验的思想是用样本的信息来推断总体的信息,所以接下来我们要从总体中取出样本。
# 从总体中随机抽取一定比例的样本
df_exams = df_exams.sample(frac=1)
假设检验被用来以科学严谨的方式检验一个关于数据的理论,这样我们就不会仅仅依赖于偶然性或主观假设。接下来我们要进行的是两个正态总体均值的检验,以学生分数为例,就是去检验两个不同的group的分数是否有明显的不同
。当建立一个假设检验时,有一个原假设和一个备择假设。还必须设置显著性水平,通常为5%(Scipy,statsmodel)。假设检验可以分为单尾或双尾。单尾的情况,例如,“A组得分>B组”。双尾的情况例如“A组的得分与B组不同”。简单介绍了这些
接下来,我们从a组和B组各抽取50名学生作为样本,然后计算该数据样本的Z分数。
❝z分数可以回答这样一个问题:“一个给定数距离平均数多少个标准差?”,在平均数之上的分数会得到一个正的标准分数,在平均数之下的分数会得到一个负的标准分数。z分数是一种可以看出某分数在分布中相对位置的方法。
❞
group_a_sample = df_exams[df_exams['ethnicity'] == 'group A']
group_a_sample = group_a_sample[:50]
# 绘制QQ图,检验正态性
fig = plt.figure()
res = stats.probplot(group_a_sample['math_score'], plot=plt)
plt.show()
group_b_sample = df_exams[df_exams['ethnicity'] == 'group B']
group_b_sample = group_b_sample[:50]
fig = plt.figure()
res = stats.probplot(group_b_sample['math_score'], plot=plt)
plt.show()
print(stats.zscore(group_a_sample['math_score']))
print(stats.zscore(group_b_sample['math_score']))


[ 0.47126865 0.05544337 2.06526555 0.26335601 0.33266022 -0.01386084
0.26335601 -0.77620719 0.05544337 0.54057286 -1.67716196 -0.01386084
-0.91481561 2.68900347 -1.19203247 1.37222342 -0.70690297 -0.56829455
0.7484855 -0.56829455 -0.70690297 -0.49899034 0.26335601 1.09500657
0.67918129 -1.60785775 0.33266022 0.47126865 -0.2910777 -0.36038191
0.67918129 -0.8455114 -1.8850746 -0.42968612 0.7484855 -1.46924932
-0.98411983 1.09500657 -0.98411983 0.47126865 -0.15246927 1.7880487
-0.2910777 0.1940518 -0.15246927 -0.56829455 0.12474758 2.48109083
-0.22177348 -1.39994511]
[-0.68278212 -2.57240054 -0.05290932 -1.69057861 0.26202709 -0.17888388
-0.24187116 0.57696349 -0.7457694 -0.17888388 0.70293805 0.82891261
0.45098893 -0.36784572 0.82891261 0.07306525 -0.93473124 -0.430833
0.26202709 -0.99771852 1.33281086 -0.87174396 1.5217727 1.89969638
1.08086173 -0.80875668 0.57696349 0.13605253 -0.99771852 0.63995077
0.51397621 -1.43862949 2.08865822 -0.36784572 1.64774726 -2.50941326
-0.55680756 -0.36784572 -0.05290932 1.14384902 -1.50161677 0.32501437
0.07306525 0.13605253 0.13605253 0.95488717 1.08086173 -0.61979484
0.19903981 -0.30485844]
Z检验
下面的代码是z测试的一个示例。测试是看A组样本的“数学平均得分”是否小于总体平均值。
A组学生的平均“数学成绩”与总体平均值相同。
A组学生的平均“数学成绩”小于总体平均值。
首先介绍一下statsmodels 包中的 ztest 函数的一般用法如下:

# 计算总体均值和样本均值
population_mean = df_exams['math_score'].mean()
sample_group_a_mean = group_a_sample['math_score'].mean()
print(population_mean,sample_group_a_mean)
# 这是单样本检验
zstats, pvalue = mstats.ztest(group_a_sample['math_score'],x2=None,value=population_mean,alternative='smaller')
print(pvalue)
66.089 61.2
0.008850880637695917
可以看出P值非常的小,小于5%,则在显著性水平为5%的条件下,我们要拒绝原假设
T检验
在T检验中,假设样本为正态分布,且总体参数未知。有3种情况:
独立样本t检验,比较两个样本所代表的两个总体均值是否存在显著差异。除了要求样本来自正态分布,还要求两个样本的总体方差相等(ttest_ind)
配对样本t检验,配对样本主要是同一实验前后效果的比较,或者同一样品用两种方法检验结果的比较。可以把配对样本的差作为变量(ttest_rel)
单样本t检验,单样本t检验是样本均值与总体均值的比较问题。其中总体服从正态分布,总体的方差未知,从正态总体中抽样得到n个个体组成抽样样本,计算抽样样本均值和标准差,判断总体均值与抽样样本均值是否相同。(ttest_1samp)
下面是这3个假设检验的例子。注意:样本的随机性导致他们可能通过也可能不通过假设,所以可能你得到的结论和我不同。
独立样本t检验
让我们来看看A组和B组在“数学成绩”功能上的得分是否不同。
=样本组A的平均“数学成绩”与样本组B相同。
=样本组A的平均“数学成绩”与样本组B不同。
在5%显著性水平下测试。这是一个双尾检验。
# 当不确定两总体方差是否相等时,应先利用levene检验,检验两总体是否具有方差齐性。
print(stats.levene(group_a_sample['math_score'],group_b_sample['math_score']))
print(group_a_sample['math_score'].var(),group_b_sample['math_score'].var())
tscore,pvalue = stats.ttest_ind(group_a_sample['math_score'],group_b_sample['math_score'],equal_var=False)
print(pvalue)
print(group_a_sample['math_score'].mean(),group_b_sample['math_score'].mean())
LeveneResult(statistic=0.3789408560110682, pvalue=0.5395976230546553)
212.44897959183675 257.1983673469388
0.39114162148079246
61.2 63.84
P值小于5%,则在显著性水平为5%的条件下,我们应拒绝原假设,认为两组成绩不相同。
配对样本t检验
接下来看看A组在“数学成绩”和“阅读成绩”上的得分是否不同。
=样本组A的平均“数学成绩”与“阅读成绩”相同。
=样本组A的平均“数学成绩”与“阅读成绩”不同。
在5%显著性水平下测试。使用ttest_rel,这是一个双尾检验。
tscore,pvalue = stats.ttest_rel(group_a_sample['math_score'],group_a_sample['reading_score'])
print(pvalue)
print(group_a_sample['math_score'].mean(),group_a_sample['reading_score'].mean())
0.025329567098176128
61.2 64.26
P值小于5%,则在显著性水平为5%的条件下,我们应拒绝原假设,认为两个科目的成绩不相同。
单样本t检验
让我们看看A组样本的平均“数学分数”是否与总体平均值相同。
=样本组A的平均“数学成绩”与总体“数学成绩”平均值相同。
=样本组A的平均“数学成绩”与总体“数学成绩”平均数不同。
在5%显著性水平下测试。这是一个双尾测试。
tscore,pvalue = stats.ttest_1samp(group_a_sample['math_score'],df_exams['math_score'].mean())
print(pvalue)
print(group_a_sample['math_score'].mean(),df_exams['math_score'].mean())
0.02167469754070706
61.2 66.089
P值小于5%,则在显著性水平为5%的条件下,我们应拒绝原假设。
后期文章将会涉及其他类型的检验,方差分析,一元回归分析等,我将尽量减少不必要的数学推导公式,把最通俗易懂的内容呈现给大家。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“小詹学Python”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心。
