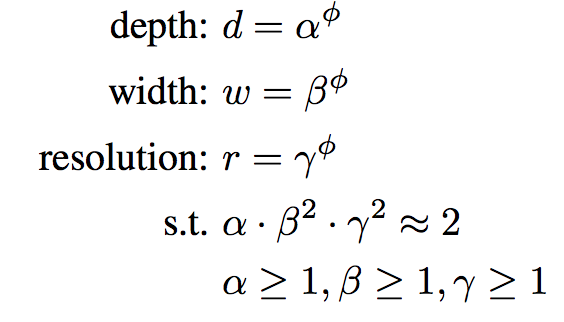点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

自 AlexNet 赢得 2012 年 ImageNet 的竞赛以来,CNN(卷积神经网络的缩写)已成为深度学习中各种任务(尤其是计算机视觉)的实用算法。从2012年至今,研究人员一直在试验并试图提出更好的架构,以提高模型对不同任务的准确性。今天,我们将深入探讨最新的研究论文"高效网络(EfficientNet,https://arxiv.org/pdf/1905.11946.pdf)",它不仅注重提高模型的准确性,而且注重提高模型的效率。
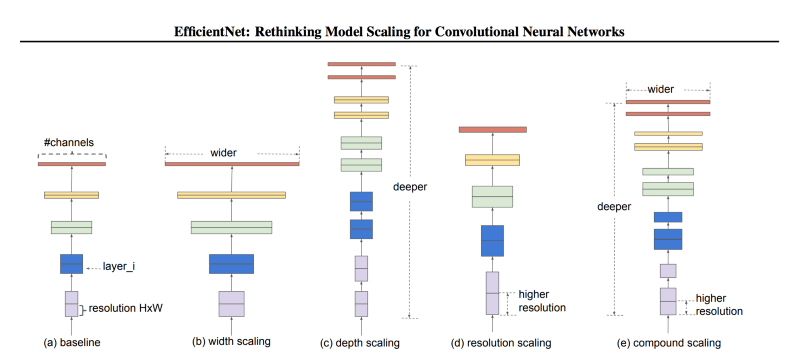
在讨论"尺度意味着什么" 之前,相关的问题是:为什么尺度至关重要?通常进行缩放是为了提高模型对特定任务(例如 ImageNet 分类)的准确性。尽管有时研究人员不太关心模型的高效性,因为打败对手是从精度方面来说的,但如果操作得当,缩放也有助于提高模型的效率。卷积神经网络里涉及到三种尺度:深度、宽度、分辨率。深度指的就是网络有多深,或者说有多少层。宽度指的是网络有多宽,比如卷积层的通道数。而分辨率就是输入卷积层的图像、特征图的空间分辨率。下图直观地显示出三种尺度的区别,我们后面也会详细地讨论。
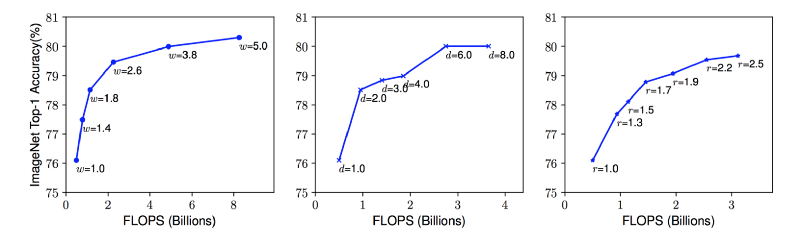
模型尺度。(a) 是一个基本的网络模型;(b)-(d) 分别单独在宽度、深度、分辨率的维度上增加尺度;(e) 是论文提出的混合尺度变换,用统一固定的比例放缩三个不同维度的尺度。改变网络深度是最常见的尺度变换方式,通过增加、减少层数可以使网络深度增减。比如 ResNet 可以从 50 层增加到 200 层,也可以缩小到 18 层。那么为什么要调整网络深度呢?从直觉上来看,越深的网络越能够捕捉丰富而复杂的特征,同时对于新任务的泛化性能更强。“听上去好有道理,那我们搞一个 1000 层的网络好了?只要效果好,计算资源都不是事儿。”话虽这么说,理论上讲越深的网络越厉害,但是实验发现并非总是如此。梯度消失是网络变深带来的最常见的问题。即使我们避免了梯度消失,又通过一顿操作使训练过程足够平滑,添加网络层也并不总是管用。比如 ResNet-1000 的准确率就和 ResNet-101 差不多。当我们想保持网络模型不要太大的时候,通常要限制深度而在宽度上做文章。更宽的网络可以捕捉到更多的细粒度特征,更小的网络也更容易训练。“这不是我们梦寐以求的吗?模型小,精度高?那就继续拓宽啊,又有什么问题吗?”问题在于,如果深度上不够而是一味增加宽度,网络的精度仍然会很快到达天花板。“好吧,你说的都对。你说我们既不能把网络设计得非常深,又不能设计得非常宽,那不能组合一下吗?这都想不到你还能干啥?搞机器学习吗?”这个问题提的非常好,我们的确可以这么做。不过在讨论这个问题之前,我们聊一下第三种尺度,这三种尺度也是可以组合的对吧。直觉上来说,高分辨率的图片包含更精细的特征,所以应该效果更好。这也是为什么对于例如目标检测的复杂任务,输入图片会用到 300x300,512x512 或者 600x600 这样的大分辨率。不过分辨率调大带来的指标提升并不是线性的,精度提升很快就趋于饱和了。比如输入图片的分辨率从 500x500 提高到 560x560 并没有带来明显提升。以上三点给我们的第一个现象:在任何一个维度上(宽度、深度、分辨率)提升网络的尺度,能够提高精度,但是当模型大到一定程度时,带来的精度提升就不明显了。左、中、右图在同一个网络的基础上,分别增加宽度 (w)、深度 (d)、分辨率 (r) 的系数。尺度大的网络可以达到更高的精度,但是到 80% 都基本达到了饱和,可见只改变单一维度的尺度带来的提升是有限的。
的确,我们可以对不同的尺度进行组合变换,但是论文作者提到了这样两点:
- 虽然可以凭经验对每个维度设置一个固定的尺度值,但是寻找这个值的过程是很枯燥的。
- 大多数时候,手动确定这个尺度得到的精度和性能都不一定是全局最优的。
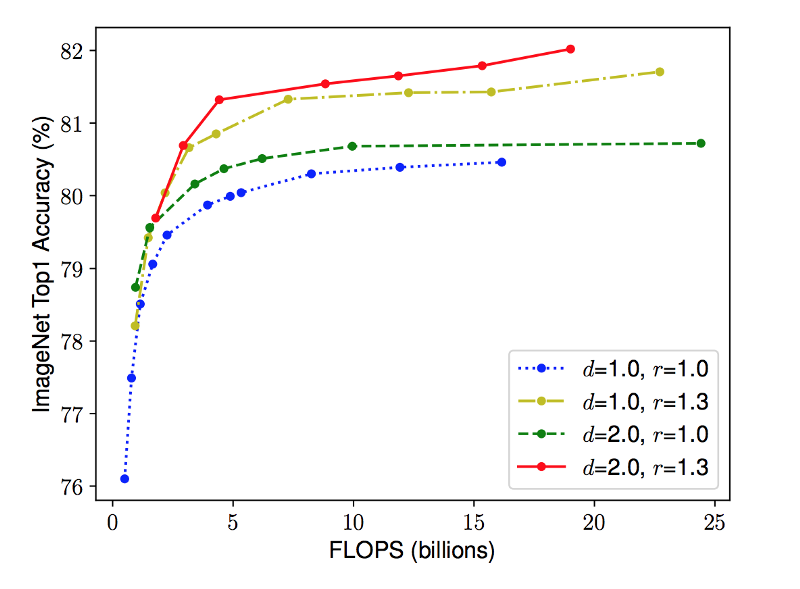
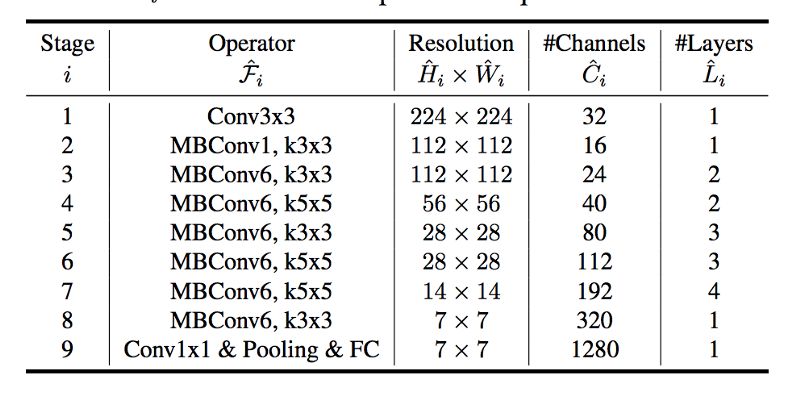
直觉上,随着输入图片分辨率的增加,网络深度和宽度应该随之增加。深度增加,特征图的感受野会增加。宽度增加,可以捕捉更多的细粒度特征。为了验证这个直觉,作者做了大量实验,在每一个维度上使用不同尺度。比如下面这幅论文中的插图所看到的,当使用较深的网络和较大的分辨率时,对宽度进行调整,相同运算量下可以达到更高的精度。基于不同基准模型改变网络宽度。每个点表示不同宽度的模型。所有的基线模型来自于表格 1。第一个基线模型 (d=1.0, r=1.0) 有 18 个卷积层,224x224 分辨率输入,最后一个 (d=2.0, r=1.3) 有 36 个卷积层,299x299 分辨率输入。这个结果给了我们第二个现象:平衡各个维度(宽度、深度、分辨率)的尺度,有助于提高精度与性能。作者提出了一种简单但有效的尺度变换方法,借助混合系数 ɸ 来对网络的宽度、深度和分辨率进行如下缩放:ɸ 是一个人为设定的系数,用来依据计算资源控制模型的规模。α, β 和 γ 用来表示如何把这些资源分配给深度、宽度和分辨率。“好吧,研究员!那么回答我两个问题:一,为什么 alpha 不用平方?二,为什么限制三个系数的乘积约等于 2 ?”这个问题问得非常好。在卷积神经网络中,卷积层是计算量最大的部分。而一个常规的卷积层的计算量,通常与 d, w², r² 近似成正比。也就是说,深度加倍会使得计算量加倍,而宽度或分辨率加倍会使得计算量增加近似四倍。所以,为了保证总的计算量不超过 2 的 ϕ 次方,我们限制 (α * β² * γ²) ≈ 2。尺度变换不会改变网络层的运算,所以最好先得到一个不错的基线网络,然后在此基础上对不同尺度进行混合放缩。作者先用神经网络架构搜索(NAS)同时优化精度和运算量得到一个基本的网络。这个网络结构与 M-NasNet 类似,因为使用了相似的搜索空间。网络模块如下表所示:
MBConv 模块是指的 Inverted Residual Block 模块(在 MobileNet V2 中用到的),部分还包含了Squeeze and Excite Block 模块。现在有了基线网络,我们可以搜索尺度变换的最优值。如果我们再看刚才的方程,会发现总共有四个参数要搜索:α, β, γ 和 ϕ。为了能让搜索空间更小,搜索计算量更低,都做可以通过两步完成:- 固定 ϕ=1,假设还有两倍的计算资源可用,对 α, β, γ 做一个小规模的网格搜索。基于 B0 网络,发现最优值是 α=1.2, β=1.1, γ=1.5,同时满足 (α * β² * γ²) ≈ 2
- 固定 α, β 和 γ 为上一步搜索的结果,用不同的 ϕ 做实验,得到 EfficientNet B1- B7。
这可能是 2019 年以来我读过的最好的一篇论文之一。这篇文章不仅为搜索更精确的网络,打开了新世界的大门,而且同时强调了搜索高效的网络。
虽然之前不乏这个方向的研究,例如 MobileNet,ShuffleNet,M-NasNet 等,通过降低参数量和计算量来压缩模型,从而应用在移动设备和边缘设备上,但这是我们第一次看到,在参数量和计算量显著降低的同时,模型精度获得了巨大提升。https://arxiv.org/abs/1905.11946
https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~