
空中悬停、翻滚转身、成功着陆,我用强化学习「回收」了SpaceX的火箭
我自己造了个「火箭」,还把它回收了。

项目主页:https://jiupinjia.github.io/rocket-recycling/
GitHub 地址:https://github.com/jiupinjia/rocket-recycling
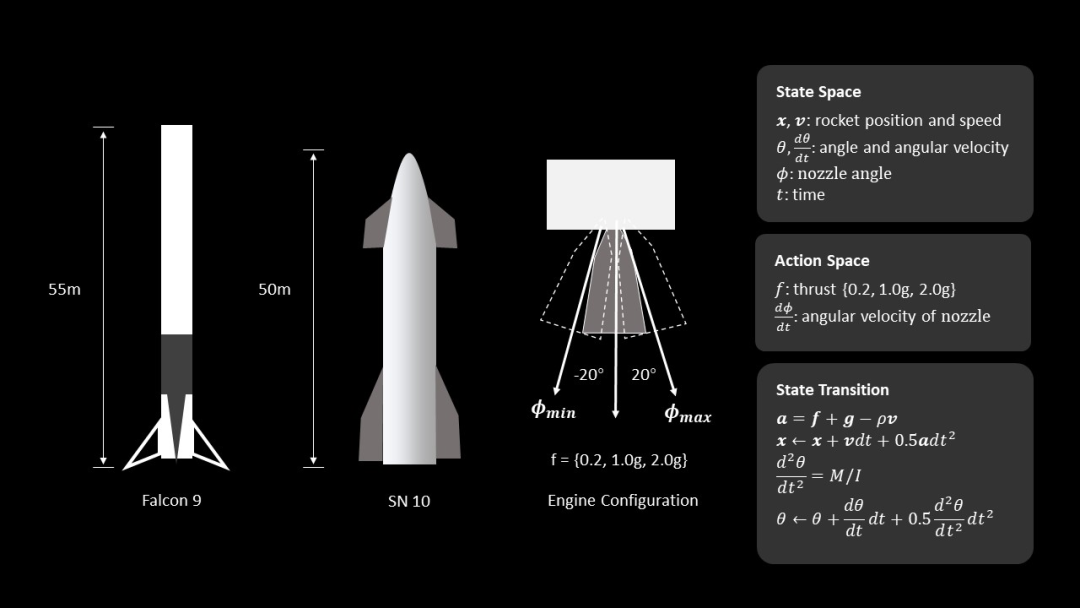

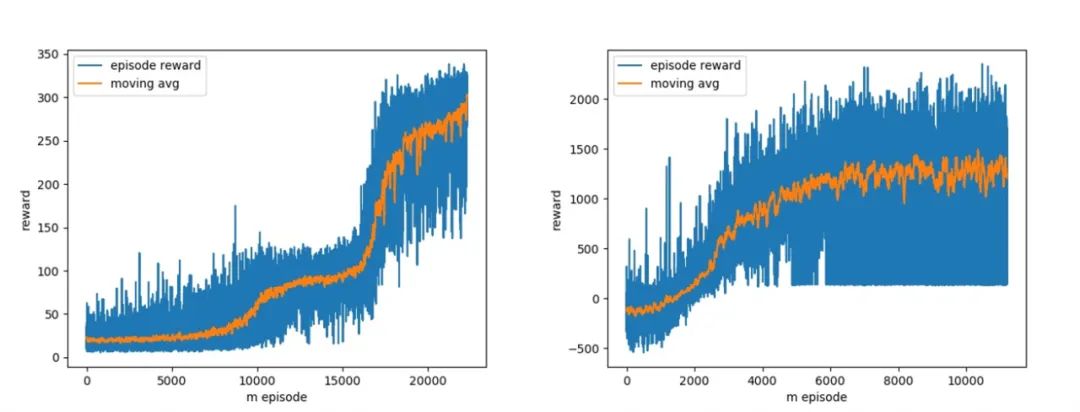



import torchfrom rocket import Rocketfrom policy import ActorCriticimport osimport glob# Decide which device we want to run ondevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")if __name__ == '__main__':task = 'hover' # 'hover' or 'landing'max_steps = 800ckpt_dir = glob.glob(os.path.join(task+'_ckpt', '*.pt'))[-1] # last ckptenv = Rocket(task=task, max_steps=max_steps)net = ActorCritic(input_dim=env.state_dims, output_dim=env.action_dims).to(device)if os.path.exists(ckpt_dir):checkpoint = torch.load(ckpt_dir)net.load_state_dict(checkpoint['model_G_state_dict'])state = env.reset()for step_id in range(max_steps):action, log_prob, value = net.get_action(state)state, reward, done, _ = env.step(action)env.render(window_name='test')if env.already_crash:break
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论