
10分钟教你Python爬虫(下)--爬虫的基本模块与简单的实战
新年快乐
各位看客老爷们,新年好。小玮又来啦。这次给大家带来的是爬虫系列的第二课---爬虫的基本模块与简单的实战。
说到爬虫的基本模块,不知道大家之前有没有了解过呢。如果你之前没有了解过,给小玮一个机会带您慢慢了解它,如果你之前了解过,也请给小玮一个机会帮助您再次巩固。
下面让我来慢慢细说。

在这节课上,我们会主要了解两个模块,requests和BeautifulSoup。
在最开始呢,肯定是大家要下载安装一下这两个模块。当然如果你按照很久以前的一篇推文里面安装的是anaconda的话,你就不需要下载,因为早就已经安装好了。
下面我介绍一下直接安装python的人的安装方法。打开cmd控制台,输入pip install requests,mac用户呢,输入pip3 install requests等待下载结束就可以了。Beautifulsoup的安装会在后面给出。
下面分别来介绍一下这两个模块。requests是干什么用的呢。它是用作进行网络请求的模块。在这里给大家举一个例子,大家可以试着去输出一下下面的代码,看看到底是什么。
import requestsreq=requests.get('http://docs.python-requests.org/en/master')print(type(req))print(req.status_code)print(req.encoding)print(req.cookies)
这里的status是状态码,encoding是编码方式。在这里简单的介绍一下常见的状态码。
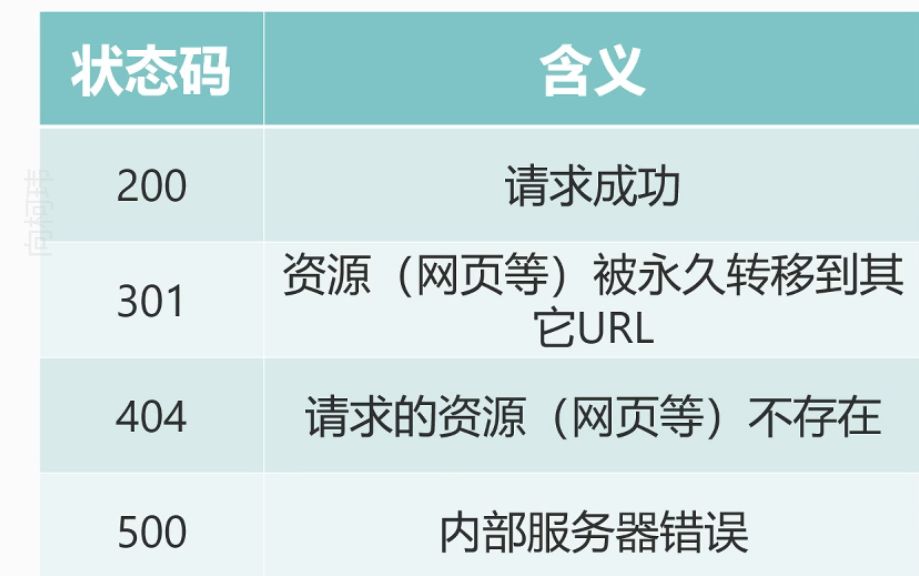
那么最后的cookies是啥呢?
其实就是一个记录你在这个网页中的活动的东西,可能这么说并不是很形象,可以这样理解,在抖音等APP上,你有没有发现经常看的一些种类的视频总是不断的推送给你,而其他的内容很少推送给你,这是为什么呢?原因很简单,就是因为有这个cookies记录了你的爱好。
就我个人而言,并不是很喜欢cookies,因为有可能你无意中点到了某个东西,她就不断地给你推送。考虑到有些人会和小编一样不太习惯一些莫名其妙的推送,一些网站会询问用户是否同意网站有cookies。
对于requests其实介绍到这里就差不多了,因为还有其他的内容在我们的课上不会用到很多。如果大家还有别的需求的话,可以去网上搜一搜。那么下面我们介绍一下BeautifulSoup。
对于这个模块,我想说她确实是一个爬虫利器,出色的解析工具。因为我们直接用requests获取这个网页代码的时候,我们的程序是不知道究竟这个代码中有些什么东西的,只有通过解析html代码我们才知道这个网页中究竟有一些什么。
BeautifulSoup 的安装比requests的安装会复杂一点,她需要安装两个东西。一个是lxml,一个是beautifulsoup4,打开cmd命令行,输入pip install lxml,输入pip install beautifulsoup4就可以了。
在导入这个模块的时候,我们通常是这样进行导入的。
from bs4 import BeautifulSoup这个模块怎么使用呢?在这里举一个例子,大家可以去尝试一下。
import requestsfrom bs4 import beautifulsoupr=requests.get(网址)html=r.textsoup=Beautifulsoup(html,’lxml’)print(soup.prettify())
把这个程序的网址位置填上相应的网址就可以进行输出了。最后的prettify函数是做什么的呢?他是用来把我们输出的内容进行一定的格式化,相当于美化一样的作用。
不知道大家在上一节课的时候是否还记得标签Tag这个属性。
现在这个属性就起作用啦。因为现在我们的soup已经把整个网页源代码进行了解析,那么接下来我们就可以通过soup.tag来输出我们需要的内容。比方说我想要输出我们当前网页的title,我们就可以print(soup.title)就可以输出了,十分简单。
当然这个输出并不是把所有这个标签的量都返回,她只会返回第一个带有这个标签的量。如果想要获得所有的这类标签的内容,就可以使用soup.find_all(‘xxx’),就可以找到所有这个标签的内容。
差不多把基础内容说了一下之后呢,现在让我们进入实战的环节。今天我们爬取的内容是一个叫做笑话大全zol的网站。
首先,在最开始,我们应该要做的是引用模块
import requestsfrom bs4 import beautifulsoup
然后找到咱们浏览器的header,header怎么找我就不再多说了啊,在之前的推文已经说过了,这里就不重复说了。写上
header={'User-Agent':xxxxxx}然后让我们进入http://xiaohua.zol.com.cn/这个网址。如果你有电脑在身边的话,可以现在就打开这个网址进入。

进入了以后,随便点击一个分类,在本次教学中我们点击的是冷笑话这个分类。好的,点进来以后,我们先尝试着对这个网页进行一些爬取操作。
存放咱们的
url=http://xiaohua.zol.com.cn/lengxiaohua/,
然后用requests工具对这个网站进行请求。
html=requests.get(url,headers=heades)然后对这个网页进行解析,
soup=BeautifulSoup(html,'lxml')其实这个步骤在之前也已经仔细的说过了,在这里没有重复的必要,如果你仍然感到一些困惑,可以回到之前的推文再回顾一下。
这一次爬取的网页比上一次爬取时间和距离的网页更复杂,所以相关的操作也会更加麻烦。
让我们继续往下面看。我们现在已经完成了获取网站源代码并进行解析的过程了,接下来我们就要确定我们所需要爬取的内容。
观察这个页面,找出我们所需要内容所在的最小单元。仔细观察了以后,我们可以知道,我们需要的最小单元是这样一块内容。
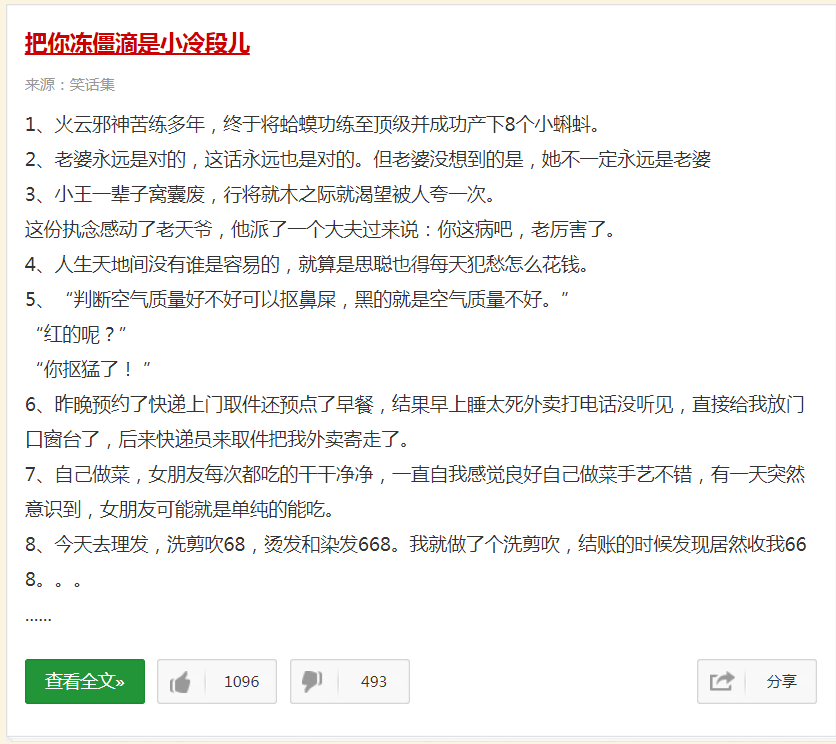
现在已经明确了我们需要爬取每一个这样的方块里面的相应内容以后,我们要做的就是找到这一块东西的位置的源代码。右键点击空白处,选择检查。出现如图所示的界面。
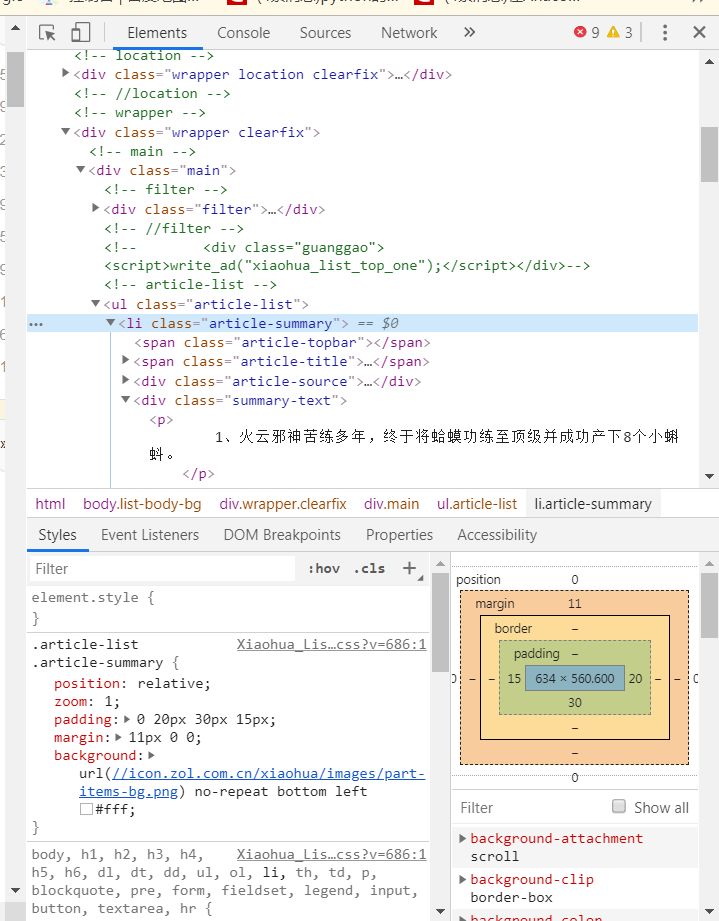
大家肯定会问,打开这个做什么呢?
这个是帮助我们确定我们到时候需要爬取的内容的标签是什么。点击左上角的箭头符号,放在我们选取的最小单元上面,我们可以看到如图所示的东西。
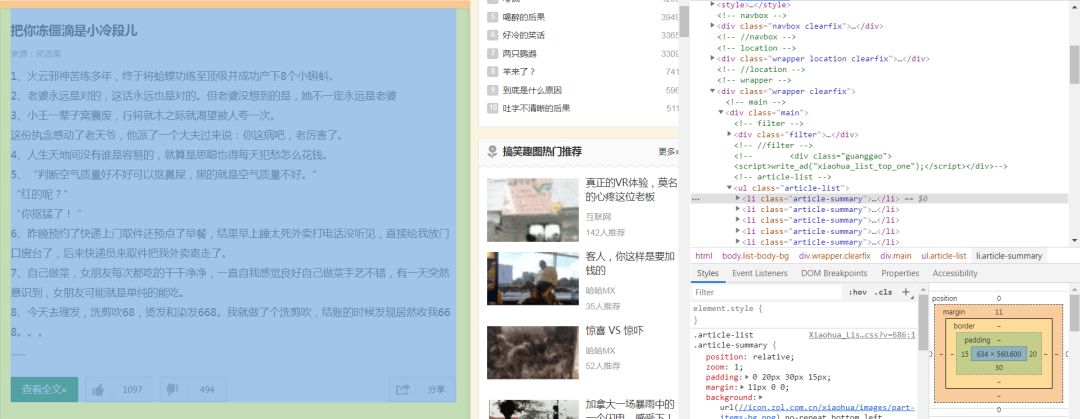
这个时候我们就可以发现,其实每一个这样的最小单元对应一个article-summary这个标签。
这样就很明确了,我们所需要的内容就在每一个article-summary里面。我们利用beautifulsoup的特有函数select选择器函数选定这个内容,lis=soup.select(.article-summary),记住一定要在article-summary前面加上‘.’,这是因为虽然select选择器中可以不写class,但是你必须指明我们需要的内容是一个class,怎么指明呢?就是通过这样一个‘.’符号。
现在为止,我们已经获取了所有的article-summary,并且存到了lis里面.
当然还不够,我们需要的东西并不是lis里面所有的东西,就打个比方说,这次爬取我的主要目的是笑话标题,笑话内容和笑话来源。那么我就需要再回到检查页面,找到我们所需要内容的标签。
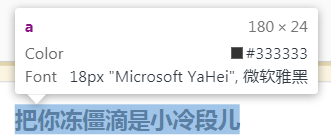
下面是标题的标签。
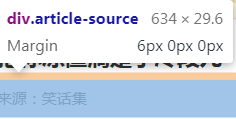
下面是来源的标签。
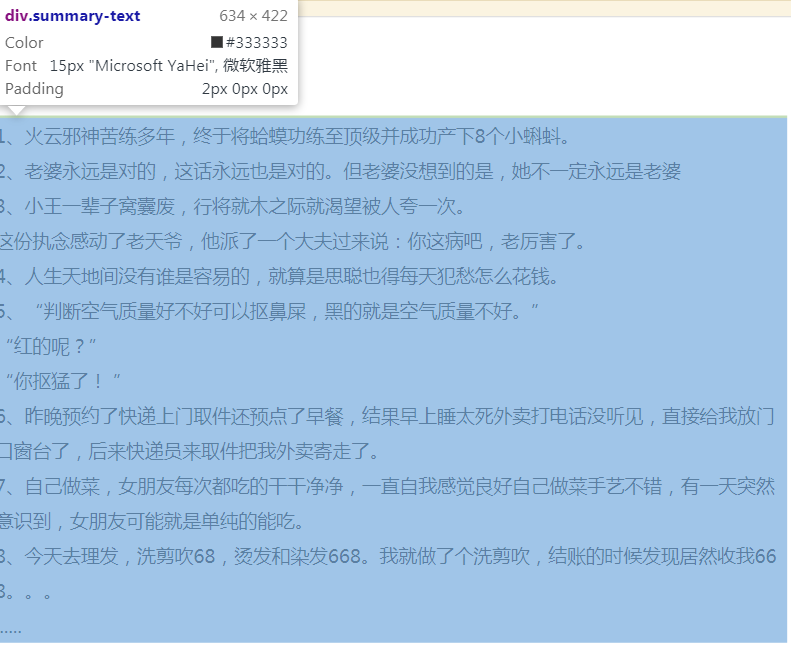
下面是内容的标签。
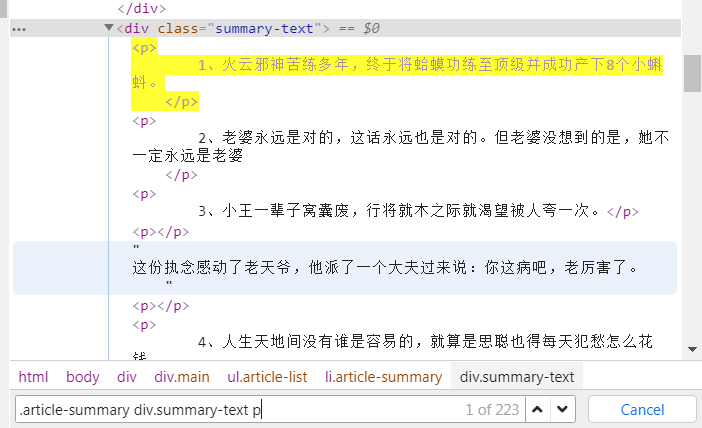
在很多时候,可能你不知道自己标签选择正确没有,我们可以在检查栏,按下ctrl+f,出现搜索栏,输入我们当前的标签。
如图所示,既可以帮助我们检查标签查找是否正确,同时有利于我们估计网页中符合条件的项目数量。
现在已经把目标的标签找到了以后,我们就可以把内容赋给相应的变量。如下
title=li.select_one('.article-title a').textsource=li.select('.article-source')[1].textcontent=li.select('.summary-text p')laugh=''for c in content:laugh=laugh+c.text
在这里我们讲解一下代码,为什么第一行我们要使用select_one呢?这是一个li标签中只有一个title,我们只需要选择这一个就可以了,即选择第一个。
.text的作用重新再说一下,因为我们在获取这个标签下的东西的时候,其实是有很多东西的,还有各种各样的标签,当然标签我们是不要的,怎么办呢?使用.text就可以了。
第二行的代码,我们在后面加了一个[1],这是为什么呢?因为我们看上面的搜索结果,其实这个标签里面的内容有两个,第一个是‘来源:’,第二个才是我们要的内容,因为index是从0开始的,所以我们选择的是[1]。
但是我们还需要进行一些别的操作,我们这样做只是把一个最小单元里面的内容存进去了,并不是所有的。那如果我们想要把所有的单元都存进去呢?这个也很简单,利用for函数就可以轻松实现。
for li in lis:这个函数的意思就是依次把lis里面的内容取出来赋给li。
其实到这个位置,我们已经完成了当前页面的爬取,各位看客老爷们可以试着输出一下我们这几个变量,看看是不是爬取成功。那么请在保证上面内容已经完成的前提下,我们继续下面的内容。
因为是爬取内容嘛,我们当然不会只爬这一个页面,这肯定是远远不够的。那么怎么办呢?我们怎么才能爬取多个页面呢?
对,没错,就是不断的进行换页操作就可以了。那么怎么进行换页呢?这就需要我们观察页面的规律了,下面我们一起来探究一下我们正在爬取的网址的规律。
http://xiaohua.zol.com.cn/lengxiaohua/2.htmlhttp://xiaohua.zol.com.cn/lengxiaohua/3.html……
其实这个网页是相当有规律的,我们可以很轻松发现他这个网址其实就是
http://xiaohua.zol.com.cn/lengxiaohua/{}.html这样子,对吧?这样我们是不是就可以用到for函数和format()函数来进行我们的翻页操作了?是的!让我们看一看代码。
for i in range(1,10)#这里的意思是生成1-9的整数,在这里我们假设爬取1-9面的内容for i in range(1,5):url='http://xiaohua.zol.com.cn/lengxiaohua/{}.html'.format(str(i))
在这里一定要注意,要用强制转换str(),为什么呢?这是因为我们网址里面的数字类型其实是字符串型的。
现在我们已经完成了翻页功能,也完成了相应页面的爬取功能,但是还是不够完美。主要还有以下几个问题.
是不是最终输出的结果有很多空白?有很多其他字符?是不是来源那个位置有的时候会出错?
别急,我们一个一个来解决。为了使我们的输出结果更加精简和规范。我们可以使用strip函数和replace函数。
strip() 方法用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。replace()函数用于去除其他位置的空白。让我们在代码里面看看具体怎么写。
laugh=laugh.strip().replace(' ','')#strip()删除开头和结尾的字符replace函数的使用方式是replace(a,b),意思是把文本中的a用b代替。解决了这个问题之后,我们来解决来源出错的问题。
我们来分析一下为什么有的时候来源这个位置会出错,我们回到原来的页面观察来源那个位置,我们可以看到有很多笑话都是没有来源的,那么这个时候我们其实啥都没有爬取到,所有就会出错。
那么这个时候怎么办呢?我们只需要进行一个简单的判断。
try:source=li.select('.article-source')[1].textexcept:source='暂无来源'
这是什么意思呢?意思就是如果try里面的内容没有出错,我们就执行try里面的内容,如果出错了,我们就执行except里面的内容。
但是到目前为止,我们还是有问题的,虽然我们已经完成了整个的爬取,但是我们还没有把他们存进来呀。如果我们要存进来怎么办呢?这就涉及到python的文件操作了。在这里呢,小玮就不多说文件的操作了。大家看看代码应该可以明白的!
下面给出所有的代码。
import requestsfrom bs4 import BeautifulSoupheaders={"User-Agent":"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.116 Safari/537.36"}for i in range(1,5):fw = open('./record{}.txt'.format(i),'w',encoding='UTF-8')fw.write('page{}\n'.format(i))print('page{}'.format(i))url='http://xiaohua.zol.com.cn/lengxiaohua/{}.html'.format(str(i))html=requests.get(url,headers=headers)soup=BeautifulSoup(html.text,"lxml")lis=soup.select('.article-summary')for li in lis:title=li.select_one('.article-title a').texttry:source=li.select('.article-source')[1].textexcept:source='暂无来源'content=li.select('.summary-text p')laugh=''for c in content:laugh=laugh+c.textlaugh=laugh.strip().replace(' ','')#strip()删除开头和结尾的字符print(title,source)print(laugh)print('-'*30)fw.write('title:{}\nsource:{}\nlaugh:{}\n'.format(title,source,laugh))fw.write('-'*30+'\n')fw.close()
其实到目前位置,做一个比较简单的爬虫项目已经足够了,但是我们会在后面介绍更加专业适用于大项目的爬虫方法,让我们一起期待下一期推文吧!
