
10分钟教你Python爬虫(上)-- HTML和爬虫基础
新年快乐
各位看客老爷们,新年好。小玮又来啦。这次给大家带来的是爬虫系列的第一课---HTML和爬虫基础。
在最开始的时候,我们需要先了解一下什么是爬虫。简单地来说呢,爬虫就是一个可以自动登陆网页获取网页信息的程序。
举个例子来说,比如你想每天看到自己喜欢的新闻内容,而不是各类新闻平台给你推送的各种各样的信息,你就可以写一个爬虫去爬取这些关键词的内容,使自己能够按时获得自己感兴趣的内容,等等。
总的来说,爬虫能用来进行数据监控,数据收集,信息整合,资源采集。
然后,我们一起来总结一下我们浏览网页的过程。
1.输入网址
2.浏览器向DNS服务商发送请求
3.找对相应服务器
4.服务器解析请求
5.服务器处理请求得到最终结果发出去
6.浏览器解析返回的数据
7.展示给用户。
这些过程我们并不需要每个过程都十分了解,但是你需要知道在浏览服务器的过程之中,我们需要一个这样的过程。下面给大家解释一下每个步骤到底是干啥的。
第一步很容易,就不多说了。我们从第二步开始,因为我们是通过这个浏览器访问这个网址,我们就需要向DNS服务商发送一个请求,简单来说,当我们输入一个域名的时候,我们需要一个中间的人帮我们去分析这个网址对应的是哪一个IP地址下的服务器,然后找到相应的服务器,当服务器接收到我们的请求时,服务器就会解析一下我们的请求,在解析了之后,会将最终的结果反馈给我们。
比如当我们点击支付,服务器会解析我们这个过程,然后把最终支付成功的结果反馈我们的浏览器,浏览器把这个数据进行渲染之后,再展示给我们。
下面我们再来分析一下域名的问题。让我们来看看这个域名
http://movie.douban.com/subject/4920389/?From=showing。这是我们打开豆瓣电影的某个电影以后,出现的网址。在这个网址里面,我们可以看到一级域名。怎么找到一级域名呢?很简单,.com,.cn……之前的第一串单词或者第一个单词,就是我们的一级域名,在这个网址中,一级域名就是douban,那么douban的左边是什么呢?没错,就是二级域名。
只要你拥有了一个一级域名,那么二级域名是随便你设置的,这里很多小伙伴就会提问了,怎么才能有一个一级域名呢?其实也很简单,只需要前往阿里云等网站就可以购买一个域名了。
所以,在这个位置,你要尤为注意,一级域名是独一无二的,但是二级域名是可以任意的,所以骗子通常会在二级域名上动手脚,大家一定要关注这一点,小心上当受骗。
那么后面的内容是什么呢。/subject/4920389/?,其实类似文件夹一样的东西,就是在我们二级域名以下的一些网址,那么问号以后是什么呢?就是一个网址参数,如果我们前面的参数一样,但是如果最后这个参数不一样,有可能我们看到的网页也不一样。
介绍完了这个,我们来研究研究爬虫的策略,主要分为两个:
1. 从某个页面开始不断爬取页面上的链接,主要分为深度优先搜索和广度优先搜索两种方法,这个不理解没关系,在之后的数据结构篇中我会给大家一一介绍
2. 观察网址的规律,这个很简单,而且也是我们最常用的方法。我们在这里举一个例子。
http://xiaohua.zol.com.cn/lengxiaohua/2.htmlhttp://xiaohua.zol.com.cn/lengxiaohua/3.html
看到上面这两个网址的差别了吗?对,就只是lengxiaohua/后面的数字不一样,那么如果我要实现一面一面的搜索网站内容,怎么办?是不是直接更改/后面的数字就可以了?没错,就是这么简单。
然后,给大家介绍一下什么是前端什么是后端。简单来说前端就是展示给我们看的,后端就是我们看不到的。
举个例子来说,你在论坛想发一个帖子,首先是把数据传给后端,后端进行一些相应的判断和处理,然后展示在前端给大家看,这就是前端和后端。
因为本篇推文我们的关注点是爬虫,所以我们更多的是关注前端。
前端开发的工具,目前主流的是Chrome浏览器,当然不是说别的浏览器不行这样,因为现在大部分浏览器基本上都是从Chrome改造过来的,把Chrome的一些东西去掉,加上一些自己的东西这样子,所以尽量用Chrome浏览器。
然后前端主要有三个重要方面,HTML,CSS,Javascript,下面我们来分别了解一下这三个方面。

HTML的全称是HyperText Markup Language,它是一个网页的最基本要素,没有HTML,整个网页根本就没有办法展示,通过标记语言的方式来组织内容(文字,图片,视频)等等。
比方说我们要在某个位置插入一段文字,某个位置插入一段视频这样子,下面就是一个网页的HTML,想要看一个网页的HTML也很简单,右键点击页面,选择检查或者检查源代码就可以看到了。
它一般分为head和body两个部分,怎么分辨呢?也很简单,,这些可以直接在网页源代码中看的见。一般来说head里面包括的内容是我这个网页的一些声明,适合用什么方式浏览等等。
当然了HTML里面最基本的段落, 这是一个段落 中还可以加一些属性的东西,比如说 这样子,这个位置就是我们在爬虫中特别需要关注的地方,属性可以有多种多样的,这里列出来的是 类属性。
这里列举一些常用的HTML标签让大家了解。
标题:<h1>一级标题h1>,<hn>n级标签hn>段落:<p>这是一个段落p>无序列表:<ul><li>Pythonli><li>C/C++li>ul>有序列表:把ul改为ol即可链接:<a href=“网址”>名称a>
既然介绍了这么多,大家其实可以自己尝试着去写一个网页。下面给出一个例子。
<html><head><meta charset=’utf-8’><meta http-equiv=’X-UA-Compatible’ content=’IE=edge,chrome=1’><title>小玮的课堂title><meta name=’description’content=’’><meta name=’keywords’content=’’><link href=’’rel=’stylesheet’>head><body><h1>小玮的课堂h1><p>欢迎来到小玮的课堂p><a href=’xxxxxx’>小玮课堂的官网a><img src=’html.png’>body>html>
先保存为index.html文件,然后再去写即可。
然后就是下一个方面CSS,CSS就是指层叠样式表(Cascading Style Sheets),它定义了一个网页该如何显示里面的元素,比如这个段落该靠在浏览器的左边还是右边,这段文字的字体,颜色,大小该是什么,这些方面都是由CSS定义。
那么如何建立一个CSS文件呢?新建一个文件,写入以下内容
p{color:blue;}
保存为index-style.css,和index.html保存在同一个目录之下。当然并不是说放在一起他们就一块儿运行了,我们还需要进行一些别的处理。
我们回到html文件,在link href的位置进行一些修改。
<link href='index-style.css' rel='stylesheet'>大家可以把加入CSS和没有加入CSS的html文件进行对比就知道区别在哪里了。CSS内容里面的p其实是选择器的意思,表示我们选择了p标签,我们在后面的操作是针对所有p标签的,里面color是属性,blue是属性值。
当然你还可以加入font-family:KaiTi,把字体进行修改,还有很多很多方面,大家可以多看看别的网页的源代码进行研究一下,特别推荐大家看一看苹果的网页源代码,可以学到相当多的东西。
然后我们再来看看id和class,这些都是属性,id在每一个html文件中只能有一个,和身份证一样,但是class可以有很多个。
那么基于这个我们就可以利用css进行各种各样的个性操作啦。比如说#welcome-line{},在选择器前加上#表示这个选择了一个id,.link{},表示选择了一个class。
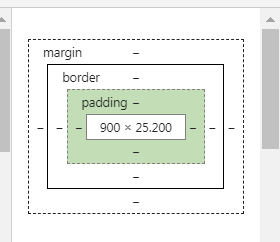
然后就是这个盒子模型,这个其实很容易理解,大家把鼠标放在上面就可以知道这个是什么意思了,它表示的是边界的意思。内容和盒子边框中间是padding,即内边距,边框和边框外其他元素之间是margin,即外边距。
终于来到了最后的JavaScript,这个和Java可是没有一点关系的啊,朋友们,这个是一款主要用于前端的一种编程语言,为网站提供动态,交互的效果。
给大家举一个例子。把鼠标放在上面他会自动弹出一些东西,或者变颜色之类的都是JSP做的东西。
他和之前两个方面的主要区别就是,他是一种严格意义上的编程语言。当然,随着技术的发展,JSP现在也慢慢用于后端的编写了。
那么我们怎么写一个JSP文件呢?新建一个文件,写入以下内容
var alertText='hello xiao wei'alert(alertText)
保存为index.js,和index.html放在同一个目录下面,这两句话是什么意思呢?第一行,我们用var定义了一个字符串,后面的alert(alertText)是可以在网页弹出一个提示框,大家经常进入一个网页会弹出一个对话框,就是这个原理。
在JSP中大家可以使用if判断语句,也可以定义函数等等,这里就不多介绍了。
到这里为止,差不多已经把前端的知识给大家都介绍了一下,如果大家自己对这部分内容感兴趣,可以去深入的了解一下。
因为小玮是个新手,这方面可能了解的不是很透彻,更加深入的就要看各位看客老爷自己了。那么了解完了这些知识,下一期我们就会正式进入爬虫的实战环节啦。期待下一次推文~
祝各位看客老爷新年快乐!
