
浅谈基于深度学习的缩放算法
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
1.基于深度学习的缩放算法基础
考虑到图像纹理和变化的多样性,基于插值的缩放算法多采用基于欧氏距离生成的权重,其模板仍有提升的空间。在DL模块化之后,Dong等人通过建模发现深度学习的算子通过组合,可以形成对经典方法的近似[1]。通过通道扩展实现对浅层特征的提取,利用卷积与非线性算子(relu,leaky relu等)实现对特征的重映射,最后叠加上采样层实现对特征的融合重构,如下图所示。
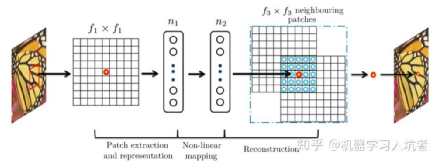
图1
这其中前两者正是DL擅长的领域,DL的通道数可以简单扩展到256通道,在压缩feature size的情况下,部分可以达到1024。特征重映射在DL模块化的之后通过重复实现,并且在前期DL任务中已经展现了正相关的能力。经过前两步的充分“膨胀”与“扭曲”,重构过程在DL-SR中通过特征折叠或者反卷积等操作即可实现。
构造DL-SR网络结构完成了DL-SR算法的第一步,下一步是确定训练数据集。前期基于SRCNN/FSRCNN/VDSR等算法都是基于通用数据集的实现方案,比如采用BSD10。如何确定DL-SR的目标,DL是一种基于学习的模式识别方法。最直接的方法是引入有监督学习,通过构建低分辨率与高分辨率对DL-SR网络进行训练,通过不同目标函数使得网络具备不同的重建特性。例如公式1基于范数的重建目标函数,意在构建和目标高分辨率一致的输出。目标在于获取映射网络结构f,使得f处理低分辨率输入x得到的结果与高分辨率源具有最小的误差。
同时,也出现了基于重建主观质量的网络结构[2],例如公式2。公式2包含两个模块。第一部分为内容损失,详细描述如公式3,类似于公式1为了实现像素级的对齐(区别在于公式3采用了MSE损失)。

第二部分采用特征对齐,即对抗损失,通过要求重构图像与源高分辨率图像通过同一深度网络映射之后,获取的特征仍具有一致性,一方面这种映射可以强化处理图像的高层语义特征,例如图像的纹理丰富程度而非单点的纹理高低,另一方面弱化单点对应关系,因为这种对应在多数据集的情况下网络训练通常会收敛到各类失真的均值处,这点在弱纹理情况下尤为明显。如下图所示,可以看出相比SRResNet(第一列,采用基于公式1的目标函数训练结果)与基于对抗训练的网络(第2-4列)在纹理清晰程度上有显著提升。
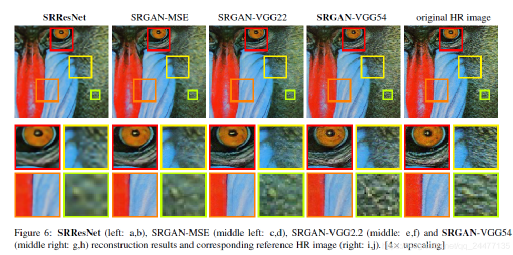
通过不同训练目标的引导,通常DL-SR会产生不同的效果,如上图所示,展示了几种不同算法的测试效果,可以看出在采用了更深层语义特征之后,图像的细腻程度得到提升,尤其在弱纹理区域的主观质量更好。额外需要注意的是,此类纹理性能提升并非基于点对点的逼近。实际上,在采用基于逐点匹配的指标中,添加特征一致性通常会导致PSNR的下降。这个结论在下表中也可以得到证实。

DL-SR在性能上的提升是有代价的,主要体现在两个方面。一方面是模型训练和数据获取对应的隐形资源,另一方面是部署资源需求,包括计算资源和存储资源。经典插值算法易经确定抽头系数m*n和插值范围,m*n的乘加资源与m行的存储资源即可实现流水处理,但是DL-SR通常需要GFlops的算力,同时考虑带宽需求,还需要匹配MB级别的存储资源。
2.DL-SR的性能提升
虽然DL-SR有着对经典方法在主客观性能上的优势,但这些优势还未能满足用户需求,目前尚存相当的提升空间,尤其是面对超高清视频处理和实际应用的情况。
首先是关于如何分析数据集与网络结构是否有偏的问题。自然图像,尤其是超高分辨率图片,通常包含大面积的平滑区域,导致纹理信息的分布不均匀,此外,考虑深层图像在提升感知野的同时会压缩相邻像素空间的关联性,这些均会导致图像恢复效果的退化。(**)提出了均衡网络,尝试从训练数据提取、网络结构设计等方面提升DL-SR性能,在降低算力需求的同时提升了主客观质量。但是关于DL-SR的训练Patch获取与网络结构的设计,在学界仍不断有新思路迸发。
在处理实际应用过程中,通常无法要求确定放大倍率的情况,尤其涉及当前短视频和异形屏的处理显示需求中,需要完成非整数倍率的方法。另外考虑目前的强交互趋势,也出现了连续放大的场景,例如在拍摄图像预览过程中,需要实现对局部信息的放大。如下图所示,目前常用的上采样算法有两种,一种是采用空间深度转换,另一种是用反卷积。这两种方法都使用相同卷积核处理全部图像,通常只能实现整数倍率方法。
(**)提出采用基于输出的像素卷积核生成方法以处理无极放大问题,这种方法虽然解决了高倍率像素生成问题,但是面临感知野和算力需求,有着与输出分辨率强相关的缺陷。有效地实现基于无极放大的DL-SR是充分释放其性能的重要课题。
另外,对特征融合方法的改进也是众多学者关注的核心要素,从最初的级联型卷积叠加到后续引入残差块,以及近期的多重残差块和多尺度残差模型,都为寄希望于提出可以满足所有场景的特征映射模型。但是在优化提升过程中,部署过程需要关注的信息必须包括算力因素,超过100个卷积层的深度网络,几乎难以在移动端实现实时2.5K视频的SR处理。
最后,提升DL-SR的性能还涉及对评估方式的改进。比较明显的是对主客观质量的差异分析,通常以PSNR或MSE为导向的主观指标,在处理弱纹理区域难以获得理想的效果。而引入主观质量的方式包括引入GAN网络或者主观指标,例如LPIPS等算子。另外,近期引DL进行无参考图像质量评价也为重建目标提供了思路,但是考虑其通用性,在本书就不再过度引申了。
3.DL-SR与High-level CV的区别
另外,随着如何实现像素级的精确,而非使用FC层对信息进行融合也是一种典型差异,这体现为对SR任务而言,整体相似性并不能满足用户需求,而对大部分分类任务,保证分类概率超出同类,并达到一定置信度即可实现目标。所以,并非low-level任务可以等价为易实现。
4.DL-SR的几点思考与未来
首先是,如何获取实际关联的有监督训练数据。目前基于DL-SR的有监督数据集基本来自于NTIRE,该数据集的低分辨率来自于Bicubic下采样,虽然Bicubic类似于点扩散函数(PSF)可以模拟部分低分辨率数据生成方式,但是实际低分辨率数据的质量退化,通常包含更多退化因素,例如CCD响应缺陷,电子噪声和图像前后处理等。后期也提出了real-SR采用变焦获取实拍数据集,但是此类数据集一方面仅限于室内,难以处理室外运动场景,另外考虑SR任务需要像素级对齐,所以LR与HR的对齐问题仍限制了其推广。
其次是,效率与效果的平衡,如前面三节多次提到的算力问题一致困扰了DL-SR算法的落地,目前已有的高效算法通常伴随了性能的明显退化,使得当前在终端仅能部署有限的处理能力。
另外,还需要指出的是,随着DL-SR的性能提升,其对多媒体处理也起到了明显的正面效果。此处举两个例子,第一是将SR引入codec,在相同码率下,低分辨率视频质量明显优于直接编码高分辨率源。采用基于SR+codec的处理思路,可以在数据供给端编码低分辨率视频,在解码端或者使用端叠加DL-SR 以提供更好的视觉体验。这种基于SR-Codec的变化,带来编解码思路的优化。第二是基于视觉SR的提升,优化了SoC的负载。Nvidia通过采用DLSS实现了基于DL的SR算法,使得高分辨率需求迁移至CuDa侧,降低Shader的负载,实现更高帧率。
本书主要介绍了传统CV的图像加速算法实现,本节针对传统插值放大算法,扩展进行了基于深度学习的缩放算法介绍。至于进一步的DL-SR算法的研究与落地,还请读者自行研究,这里主要是对缩放算法,进行一个画龙点睛之笔。
本文仅做学术分享,如有侵权,请联系删文。