
Pandas知识点-合并操作merge
merge()方法是Pandas中的合并操作,在数据处理过程中很常用,本文介绍merge()方法的具体用法。
一基础合并操作

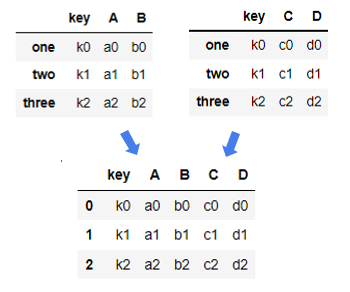

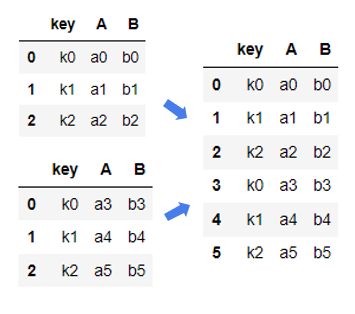
二连接方式
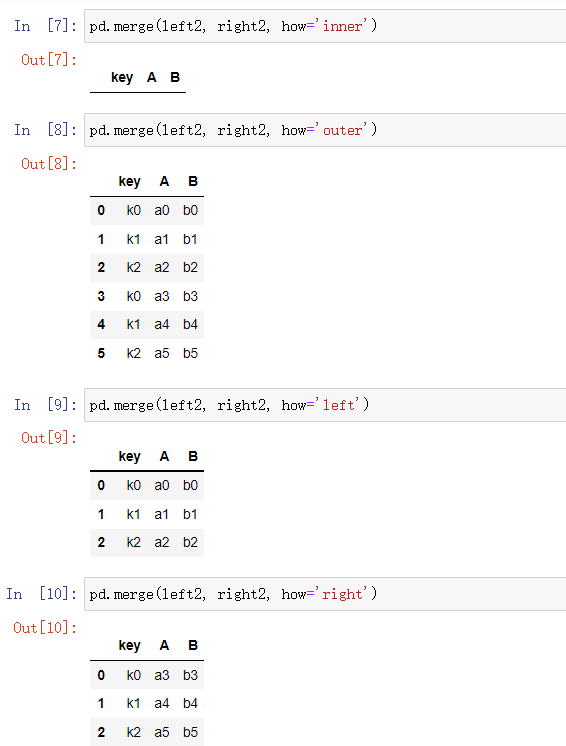
| inner | 内连 | 取key列的交集 |
| outer | 外连 | 取key列的并集 |
| left | 左连 | 使用左边df的key列 |
| right | 右连 | 使用右边df的key列 |
三指定连接的列

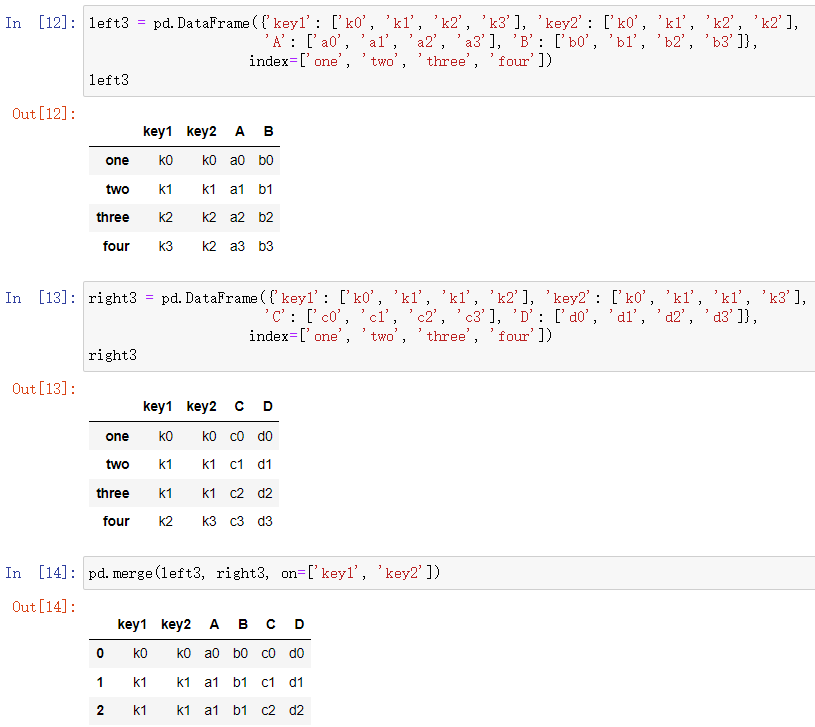
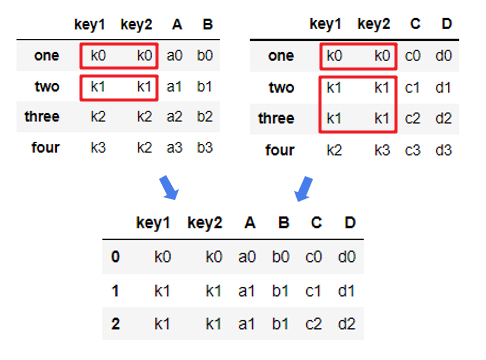
四两个DataFrame分别指定连接列
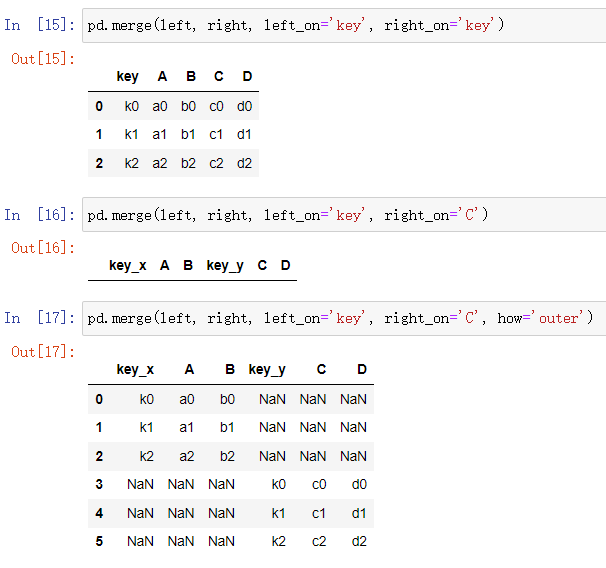

| DataFrame | left | right |
四种指定连接列的组合 | left_on | right_on |
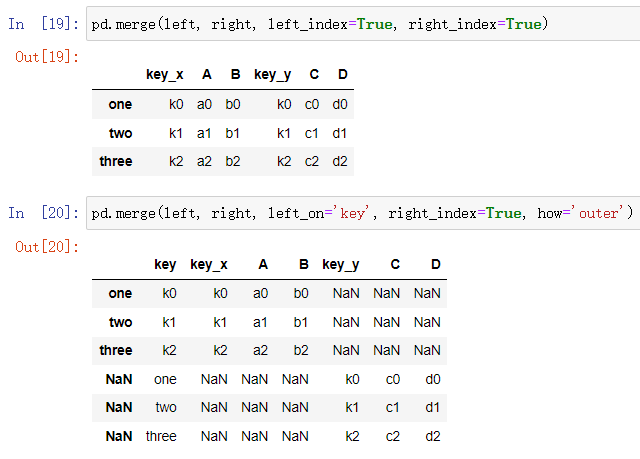
| left_index | right_index | |
| left_on | right_index | |
| left_index | right_on |
五自定义相同列名的后缀
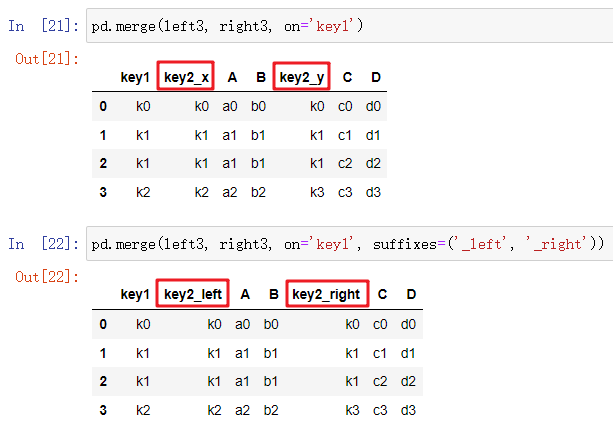
六连接列是否存在DataFrame中
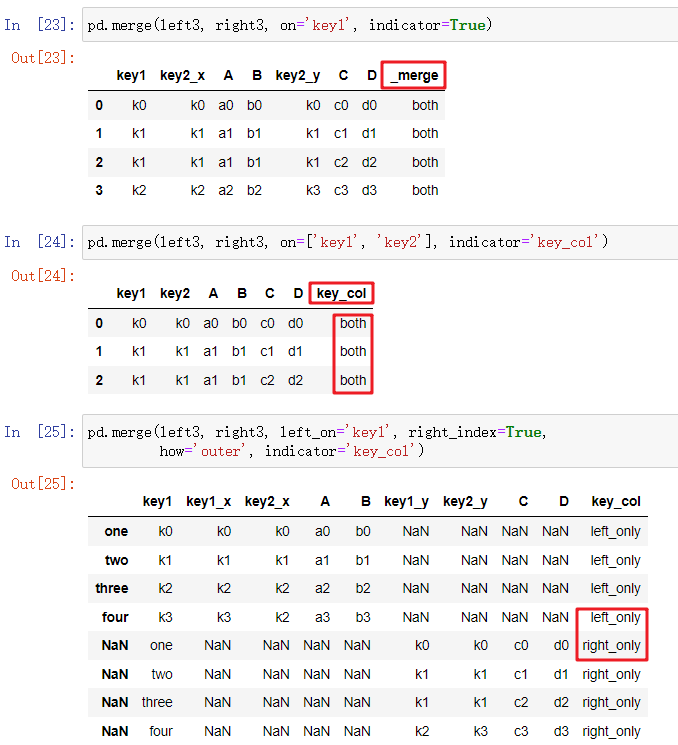
七连接列的对应关系


评论