
Pandas知识点-索引和切片操作
点击上方Python知识圈,设为星标
回复100获取100题PDF
阅读文本大概需要 5 分钟
索引和切片操作是最基本最常用的数据处理操作,Pandas中的索引和切片操作基于Python的语言特性,支持类似于numpy中的操作,也可以使用行标签、列标签以及行标签与列标签的组合来进行索引和切片操作。
本文使用的数据来源于网易财经,具体下载方式可以参考:Pandas知识点-DataFrame数据结构介绍
前面介绍DataFrame和Series的文章中,代码是在Pycharm中编写的,本文和后面介绍Pandas的文章,代码会优先在Jupyter Notebook中编写。Jupyter Notebook的安装可以参考:Jupyter Notebook的安装和使用
一、数据读取
数据文件是600519.csv,将此文件放到代码同级目录下,从文件中读取出数据。
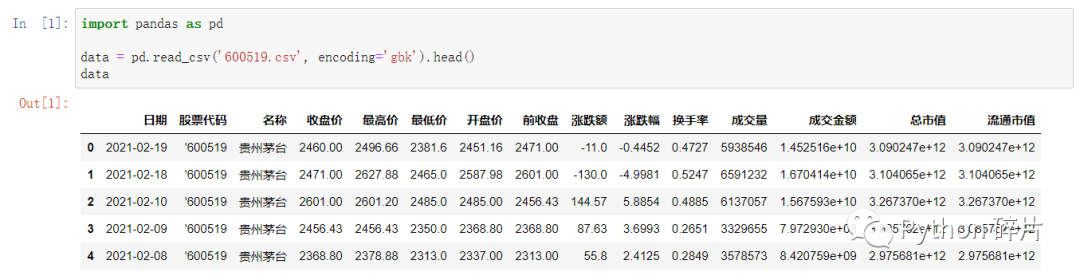
为了避免数据量太大,只取了前5行数据。查看读取的数据,列还是很多,为了让数据再精简一点,接下来将后面几列删除。默认的行索引是数值索引,为了方便后面演示索引操作,设置日期为索引。
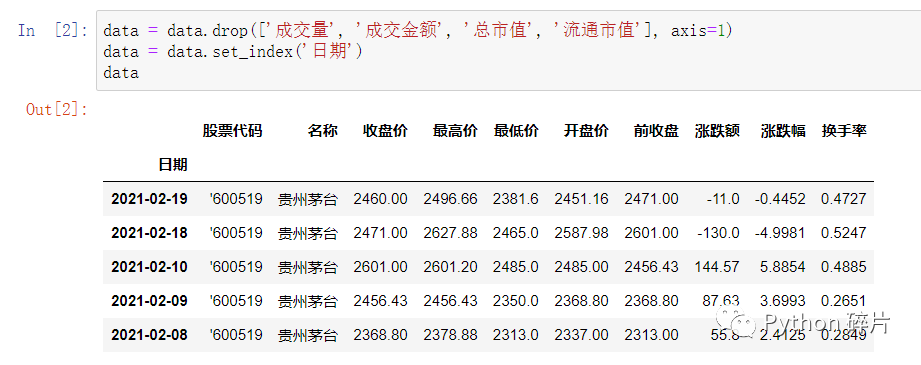
处理后的数据如上图,这样看起来简洁了很多。
二、读取一列数据或一行数据
1. 读取一列数据
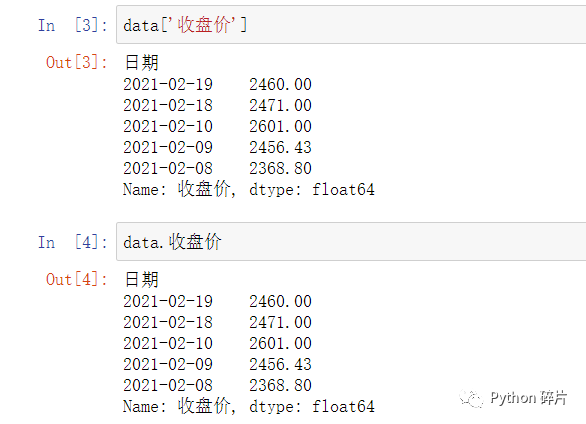
获取DataFrame中的一列数据有两种方式,第一种是用 data['列索引'] ,如 data['收盘价'] 可以获取收盘价这一列的数据。第二种是 data.列索引 的方式,如 data.收盘价 与 data['收盘价'] 的结果相同。
第一种方式是通用的方式,对于任意DataFrame都适用。第二种方式除了支持英文的索引名,也支持中文的索引名,但是如果英文的索引名与Python关键字(如class,list)同名,会报错,只能用第一种方式来取数据。
2. 读取一行数据
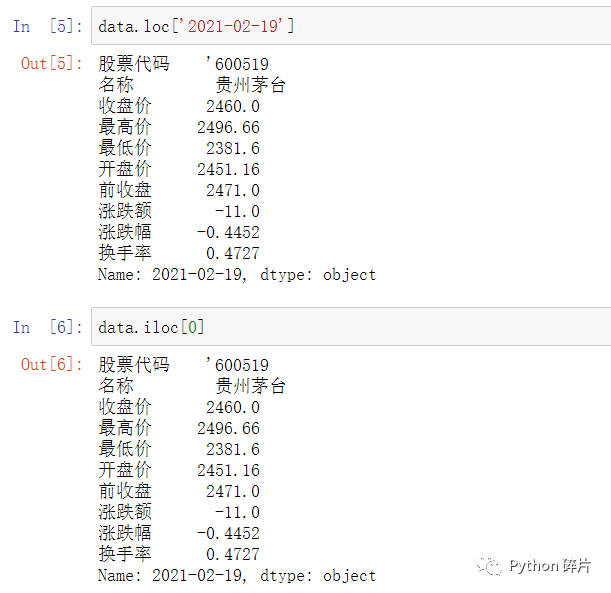
获取DataFrame中的一行数据时,不能直接用 data['行索引'] 或 data.行索引 的方式。
获取行数据也有两种方式,需要借助loc属性或iloc属性。loc属性基于行索引名获取数据,用法为 data.loc['行索引'] ,如 data.loc['2021-02-19'] 可以获取2021年2月19日的交易数据。iloc属性基于数值索引获取数据,用法为 data.iloc[数值] ,如 data.iloc[0] 是获取DataFrame中的第一行数据,与 data.loc['2021-02-19'] 结果相同。
三、读取指定位置的数据

Pandas中获取指定位置数据的索引方式默认是“先列后行”,这与numpy中ndarray的索引方式“先行后列”是相反的。在Pandas中,取数据的逻辑通常是先获取某一列数据,然后再取这列数据中的某个数据,所以默认采用了“先列后行”的方式,如果顺序反了会报错。
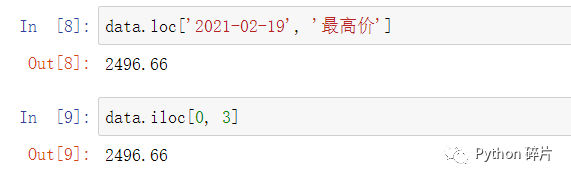
除了用“先列后行”的方式获取数据,如果想用“先行后列”的方式获取数据,可以借助loc属性或iloc属性来实现。loc属性是基于索引名来获取数据的,在loc中的行索引和列索引都要使用索引名,iloc属性是基于数值索引来获取数据的,在iloc中的行索引和列索引都要使用数值索引。同时,loc属性和iloc属性都只支持“先行后列”,顺序不能反。
四、DataFrame的索引转换
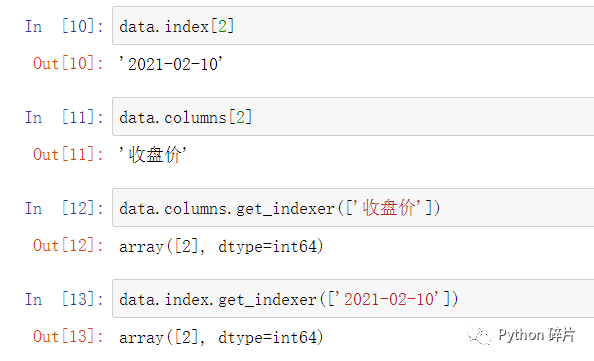
在使用loc属性和iloc属性时,行索引和列索引必须同时为索引名或同时为数值索引,所以,经常需要对索引名和数值索引互相转换。
使用DataFrame的index属性和columns属性可以得到行索引和列索引,在后面传入对应的数值就可以将数值索引转换成索引名。链式调用index属性和columns属性的get_indexer()方法,就可以将索引名转换成数值索引,get_indexer()中传入需要转换的索引名列表,即使只转换一个索引名,也要用列表的方式传入。

如果需要同时转换多个索引名,可以在列表中添加,列表中的顺序可以不遵守index和columns的先后顺序,返回结果是一一对应的数值索引数组。
五、切片
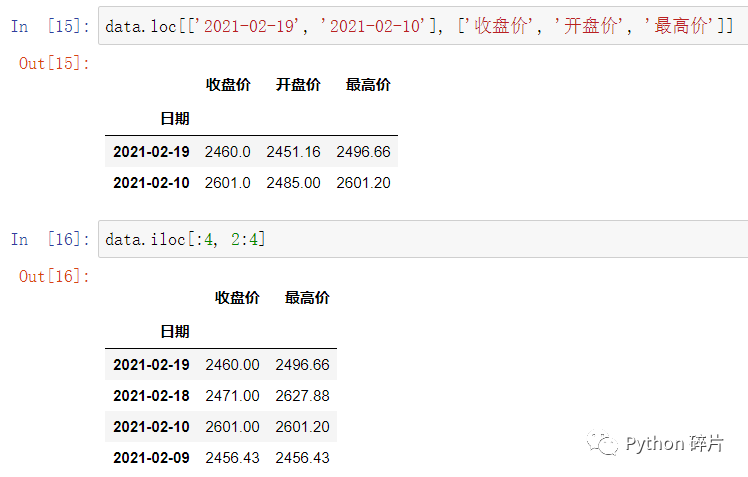
DataFrame的切片操作也要使用loc属性和iloc属性,不能直接用 data[:][:] 或 data[:, :] 的方式。loc中传入需要切片的行索引和列索引的索引名,iloc中传入需要切片的行索引和列索引的数值索引范围。
使用iloc进行切片操作时,切片规则与Python基本的切片规则相同,传入的切片索引是左闭右开的(包含起始值,不包含结束值)。
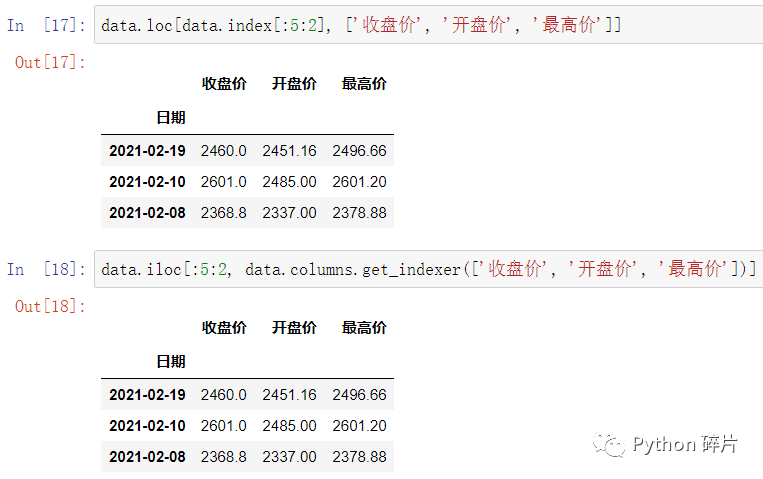
上面的索引互相转换方法,可以灵活地在切片中使用,在使用loc时将数值索引转换成索引名,在使用iloc时将索引名转换成数值索引。
加微信送《Python知识点100题PDF》
往期推荐
01
02
03
↓点击阅读原文查看pk哥原创视频
我就知道你“在看”

我就知道你“在看”
评论