
Pandas 数据类型操作
本文总结了 Pandas 中进行数据类型转换的三种基本方法,同时介绍了基于数据类型取数的方法:
使用 astype() 函数进行强制类型转换 通过自定义函数来进行数据类型转换 使用 Pandas 提供的函数如 to_numeric()、to_datetime() 等进行转化 select_dtypes 函数的使用
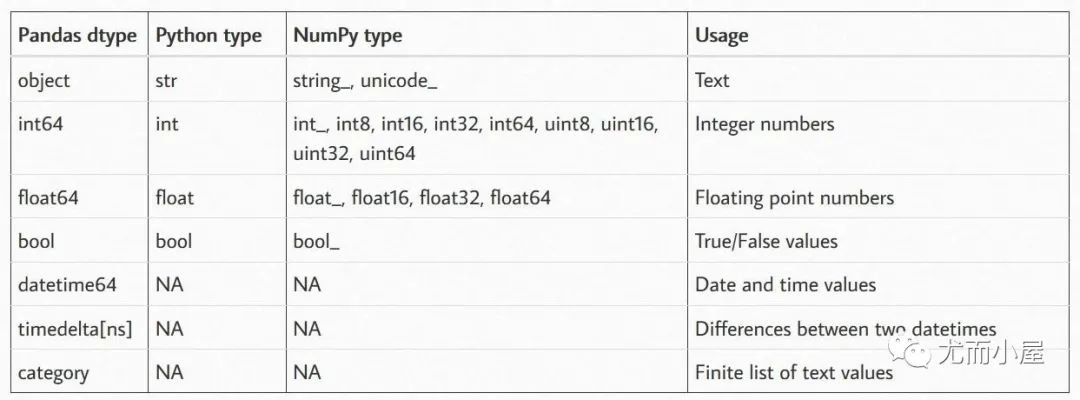
一、Pandas、Python、Numpy 各自支持的数据类型
下表中展示的是 Pandas、Python 和 Numpy 中支持的数据类型,可以看到 pandas中支持的类型是最丰富的。
二、模拟数据
2.1 导入数据
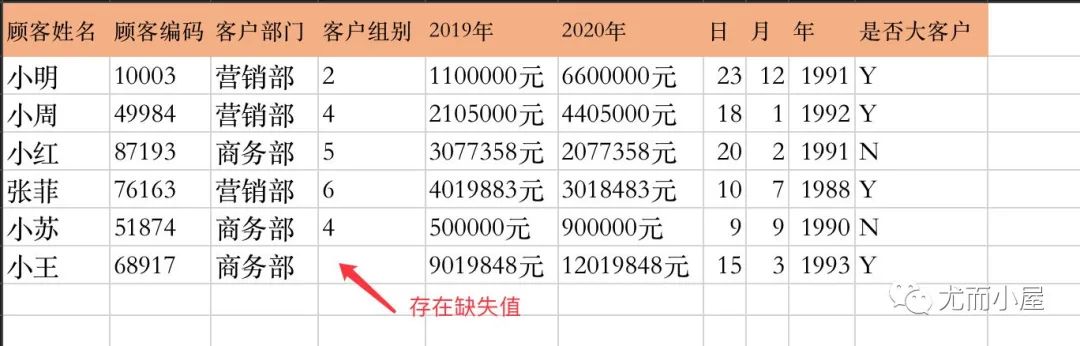
下面是模拟的一份数据,包含多个字段名称
import pandas as pd
import numpy as np
# 读取数据
df = pd.read_csv("数据类型操作.csv")
df

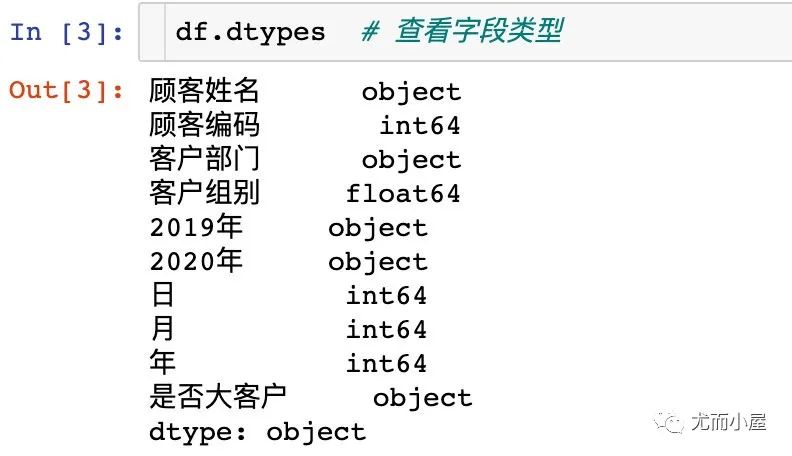
2.2 数据类型查看
查看数据的字段类型:
df.dtypes # 各字段的数据类型
df.team.dtype # 某个字段的类型
s.dtype # Series 的类型
df.dtypes.value_counts() # 各类型有多少个字段
三、实际案例
3.1 字符型转成数值型
比如我们想在数据上进行一些操作,比如将"2019年"、和"2020年"的数据相加:很明显数据不是我们想要的结果。
根本原因:这两个字段是字符类型,进行+操作,是直接将里面的内容拼接在一起,而不是里面数值的相加。

正确的操作:
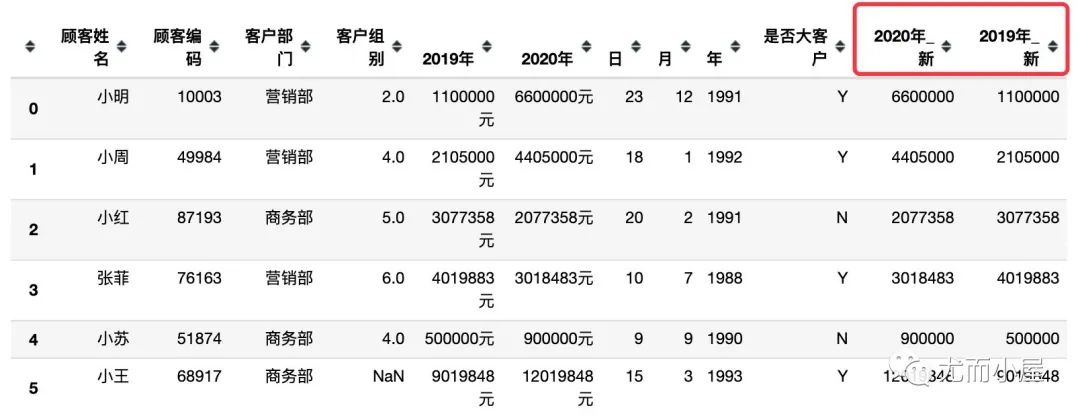
1、先把这两个字段中的数字单独提取出来
# 分割之后取出第1个元素
df["2020年_新"] = df["2020年"].apply(lambda x:x.split("元")[0])
df["2019年_新"] = df["2019年"].apply(lambda x:x.split("元")[0])
df
2、查看数据类型
生成的两个新字段仍然是字符类型,不能直接相加

3、将数字表现型的字符型数据转成数值型
有两种方法实现这种需求:
pd.astype("float") :指定类型 to_numeric():直接转化
## 字符类型的数值转成纯数值型
# 等价写法:df["2020年_新"] = df.astype({"2020年_新":"int") 字典形式传入
df["2020年_新"] = df["2020年_新"].astype("int")
df['2019年_新'] = pd.to_numeric(df['2019年_新'], errors='coerce')
df

3、将两个新的字段相加
df["前两年之和"] = df["2020年_新"] + df["2019年_新"]
df
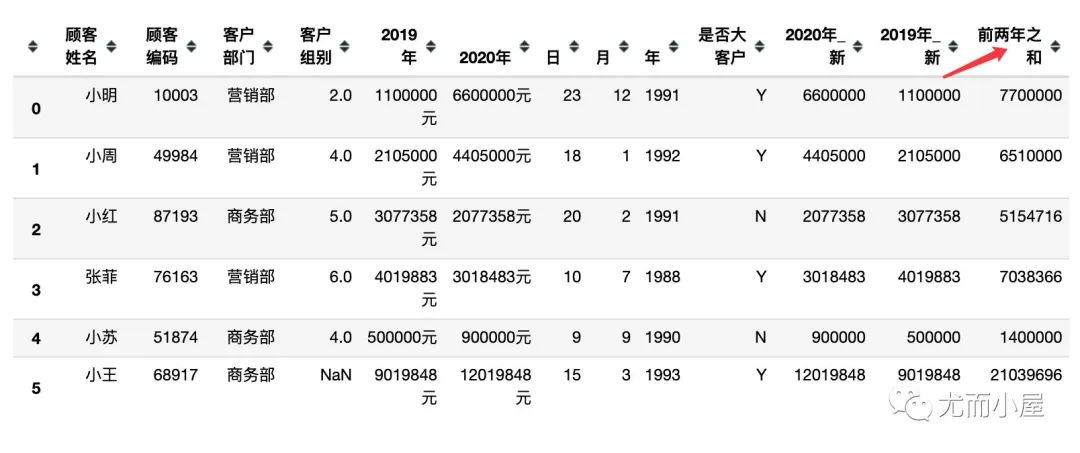
求两个年份之间的差值:

3.2 数值型转成字符型
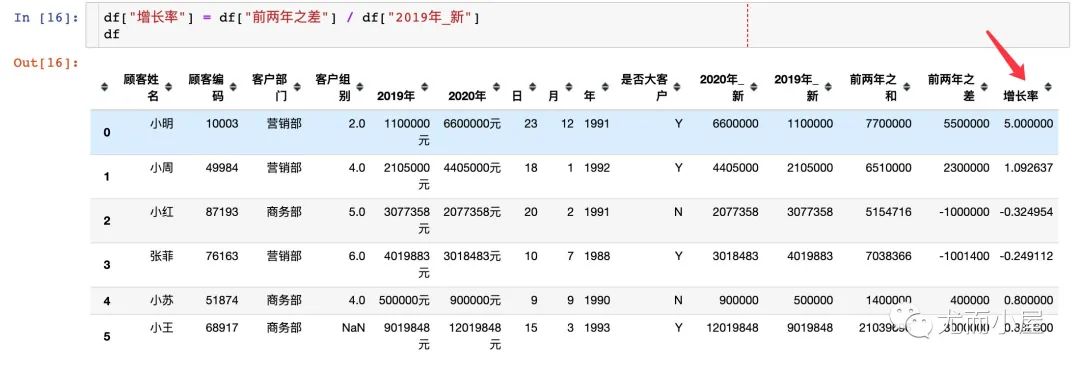
求出 2020 年的增长率:
df["增长率"] = df["前两年之差"] / df["2019年_新"]
df
现在整个增长率是 float 的数值型,我们想把它转成 % 的形式,也就是字符类型的数据:
顾客姓名 object
顾客编码 int64
客户部门 object
客户组别 float64
2019年 object
2020年 object
日 int64
月 int64
年 int64
是否大客户 object
2020年_新 int64
2019年_新 int64
前两年之和 int64
前两年之差 int64
增长率 float64 # 数值型数据
dtype: object
在这里也是两种方法满足上面的需求:
方法1:通过 str 函数的转化 方法2:通过 format 函数的格式化输出
df["增长率1"] = df["增长率"].apply(lambda x: str(round(100*x,2)) + "%")
df["增长率2"] = df["增长率"].apply(lambda x: format(x,'.2%'))
df
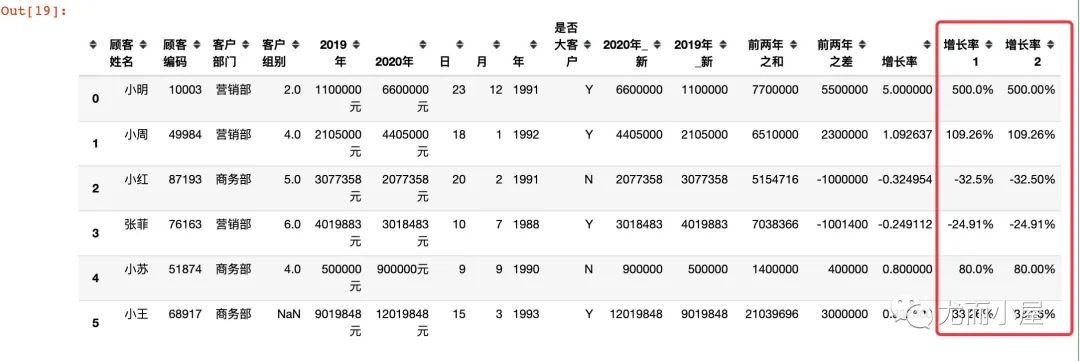
顾客姓名 object
顾客编码 int64
客户部门 object
客户组别 float64
2019年 object
2020年 object
日 int64
月 int64
年 int64
是否大客户 object
2020年_新 int64
2019年_新 int64
前两年之和 int64
前两年之差 int64
增长率 float64
增长率1 object # 两个字符类型的数据
增长率2 object
dtype: object
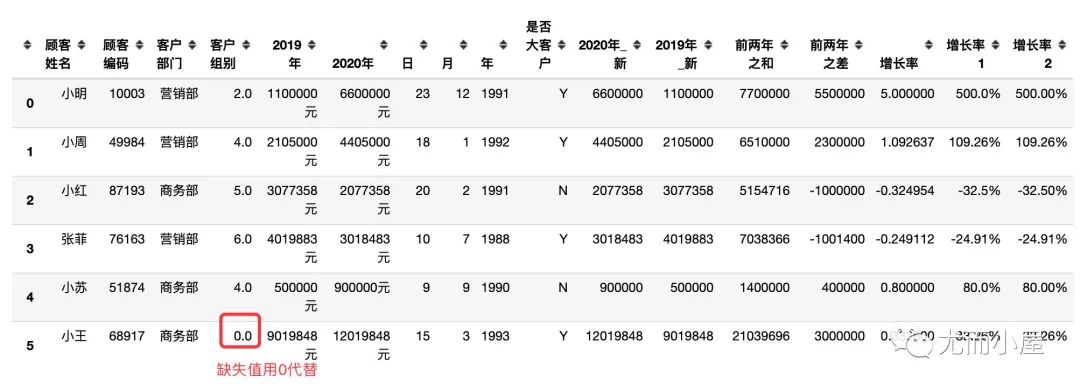
3.3 数值型数据存在缺失值
如果某个字段中大部分的数据都是数值型,但是存在少量的缺失值的情况,可以使用下面的方法进行转化:
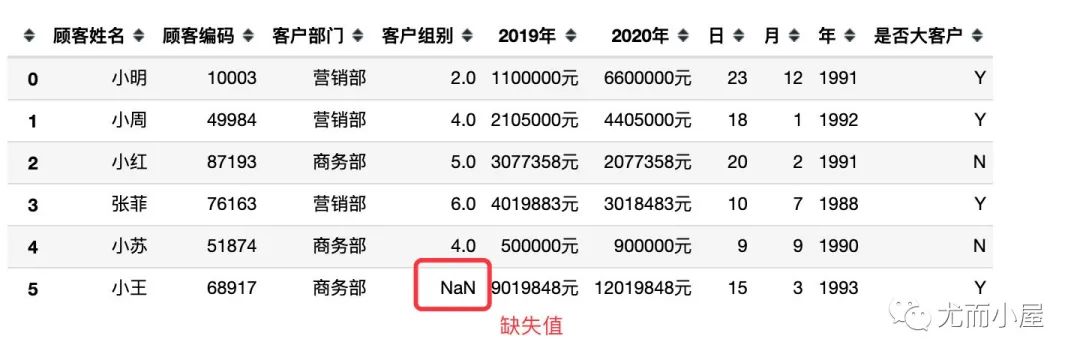
df["客户组别"] = pd.to_numeric(df['客户组别'], errors='coerce').fillna(0) # 未知的组用0代替;0可以换成其他数值
df
3.4 数值型类型转成时间类型
如果在实际数据中,我们遇到类似年、月、日等时间的数据,可以进行转化:比如我们想根据数据中的年月日生成一个生日的字段
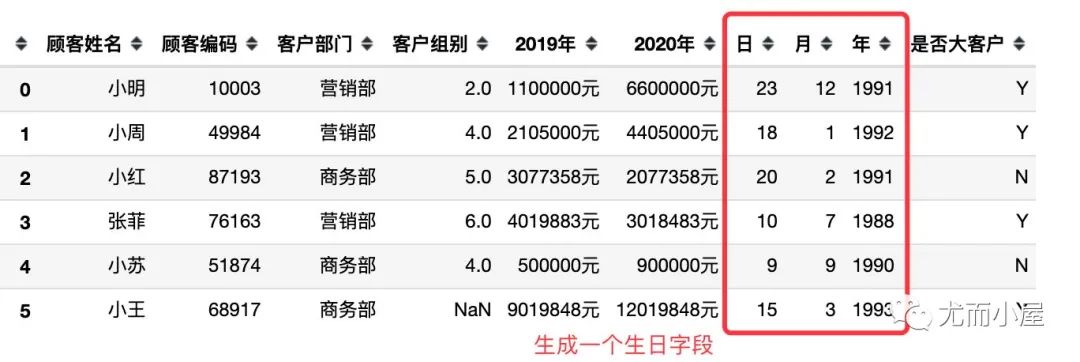
1、上面的日、月、年现在是数值类型的数据,不能直接相加,先进行转化:
df["月"] = df["月"].astype(str)
df["年"] = df["年"].astype(str)
2、转成字符型数据之后,再进行相加:
df["生日"] = df["年"] + "-" + df["月"] + "-" + df["日"]
df
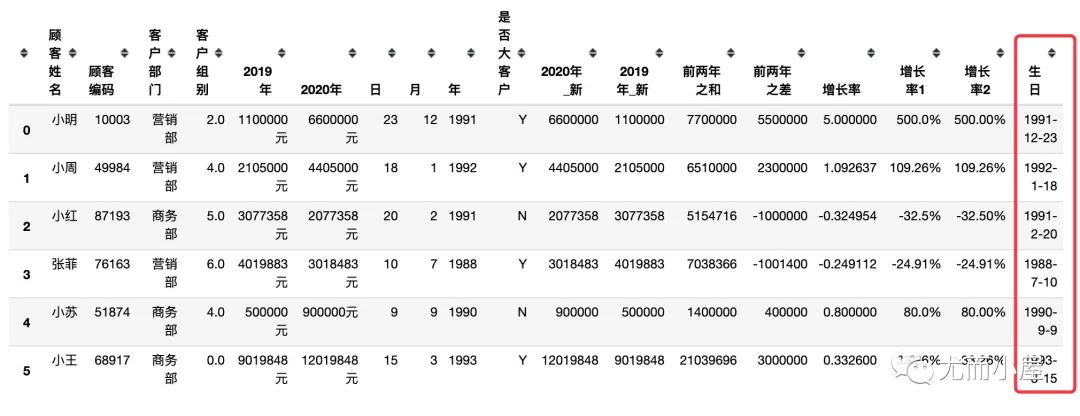
3、通过 pd.to_datetime 转成 pandas 中的时间类型数据
df["生日"] = df["生日"].apply(lambda x: pd.to_datetime(x,format="%Y-%m-%d"))
df.dtypes
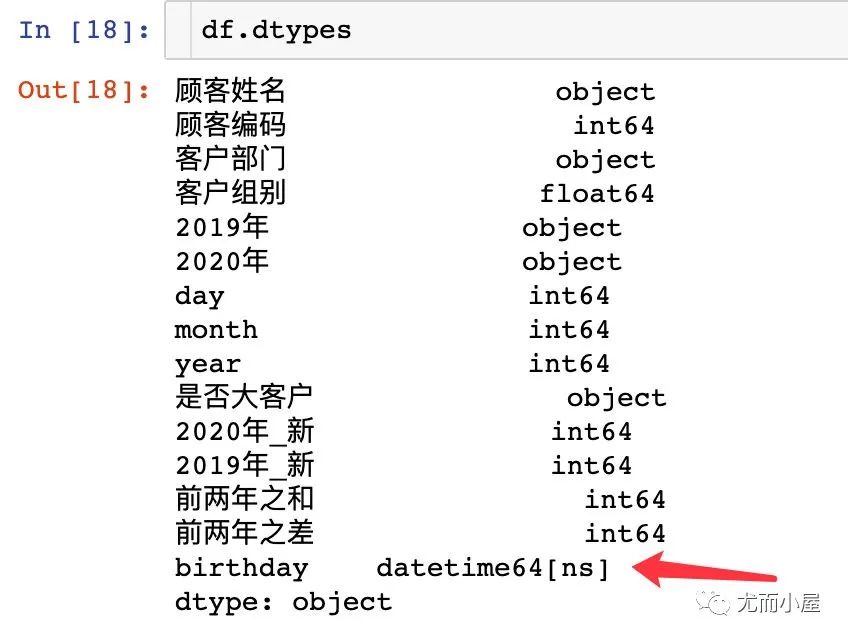
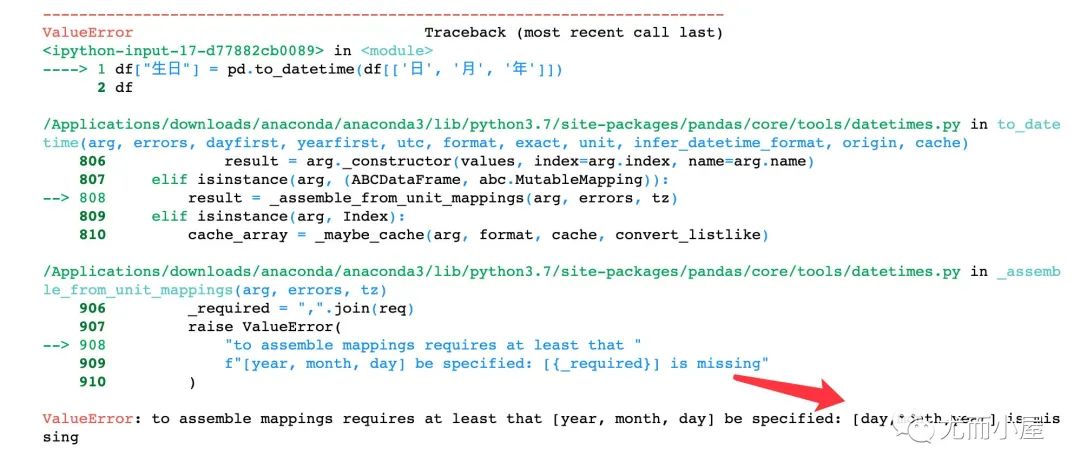
经过检验:如果字段是用英文表示的,下面的方法可以直接转成datetime64[ns]类型,使用中文汉字当做属性名的时候,该方法不适用。
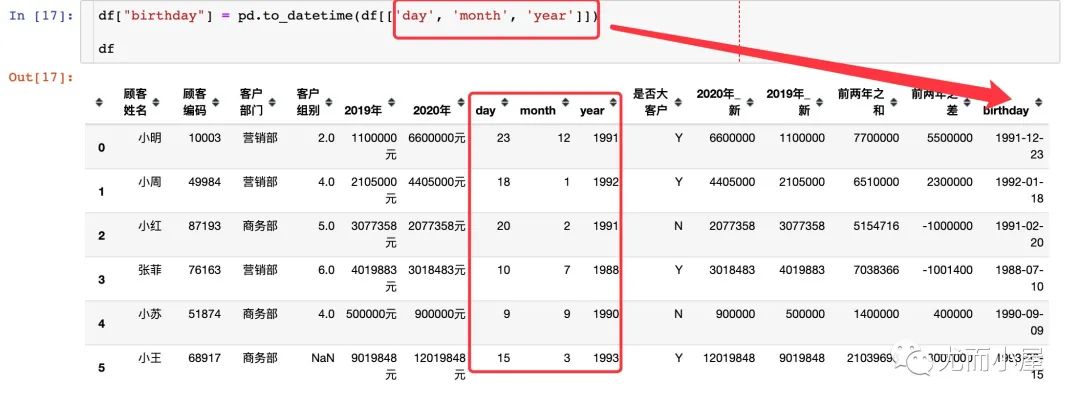
Pandas 中的 to_datetime() 函数可以把单独的 year、month、day 三列合并成一个单独的时间戳:
pd.to_datetime(df[['year', 'month', 'day']]) # 组合成日期
3.5 布尔值判断使用
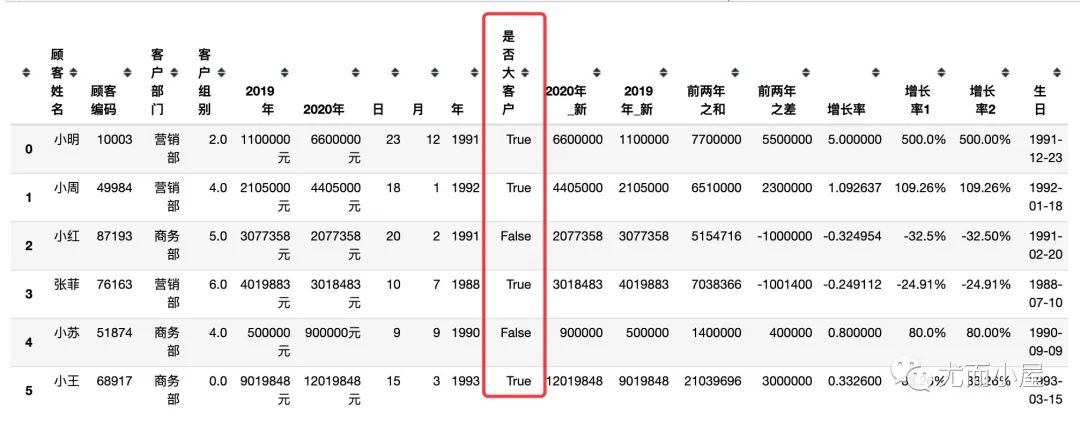
比如在是否为大客户中,我们想将 Y 换成 True,N 换成 False,可以通过 np.where 来是实现:
df["是否大客户"] = np.where(df["是否大客户"] == "Y", True, False)
df
3.6 读取文件直接转换
在使用 pandas 读取文件的时候,可以直接改变数据类型,使用参数是 converters:
df0 = pd.read_csv("数据类型操作.csv",
converters={
"顾客编码":str, # 指定改变的函数
"2019年":lambda x:float(x.split("元")[0]), # 切割函数
"2020年":lambda x:float(x.replace("元","")), # 替换函数
"客户组别":lambda x: pd.to_numeric(x, errors='coerce'),
"是否大客户":lambda x:np.where(x == "Y",True,False)
}
)
df0

四、根据数据类型取数
df 中的数据类型为:object、int64、float64、bool、datetime64[ns]
df.dtypes
# 结果
顾客姓名 object
顾客编码 int64
客户部门 object
客户组别 float64
2019年 object
2020年 object
日 object
月 object
年 object
是否大客户 bool
2020年_新 int64
2019年_新 int64
前两年之和 int64
前两年之差 int64
增长率 float64
增长率1 object
增长率2 object
生日 datetime64[ns]
dtype: object
4.1 包含数据类型
df.select_dtypes(include=["object"]) # 包含object类型的数据

也可以同时筛选包含多个数据类型:
df.select_dtypes(include=["object","bool"])

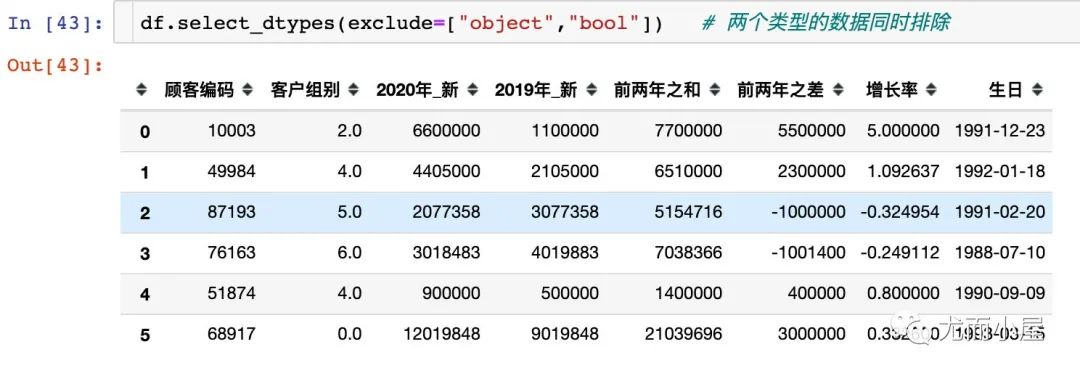
4.2 不包含数据类型
df.select_dtypes(exclude=["object"]) # 不包含object类型的数据
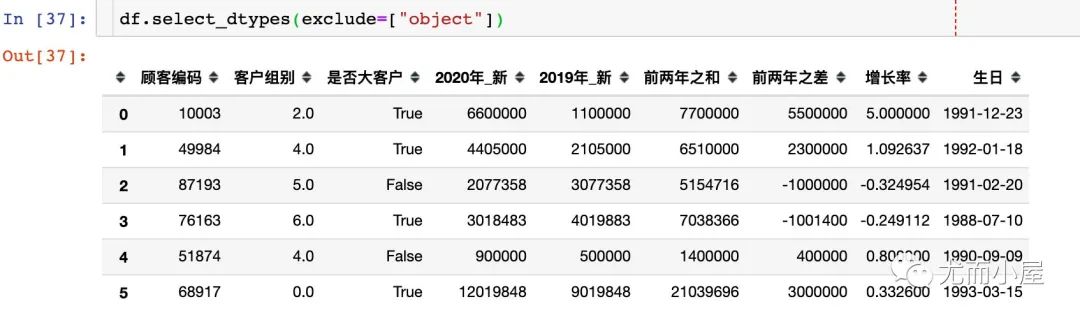
同时排除多个字段数据类型:
df.select_dtypes(exclude=["object","bool"]) # 两个类型的数据同时排除
五、总结
对数据进行操作的第一步就是保证我们设置了正确的数据类型,然后才能进行后续的数据处理、数据分析、可视化等一系列的操作。不用的数据类型可以用不同的处理方法。
注意,一个列只能有一个总数据类型。本文中介绍了 Pandas 中常见的数据类型转化和基于数据类型取数的方法,希望对读者有所帮助。