
从美团外卖的数据仓库建设中,我学到了什么?
点击上方“数据管道”,选择“置顶星标”公众号
干货福利,第一时间送达

前两天,转载了美团外卖的两篇数据仓库文章。第一篇讲他们的实时数据仓库建设,第二篇讲离线数据仓库。两篇文章都发人深思。于是,我花了点时间,拆解了各自的项目实现。
这是第二篇拆解,针对离线数据仓库,美团外卖讲述了他们的玩法。这篇感觉更接地气,和传统数据仓库项目,贴合得更紧。换句话说,这次的离线仓库,不仅对互联网行业具有借鉴意义,对非互联网行业,同样也具有参考价值。
传统数据仓库,数据基建包括了 ETL, 建模和可视化。从数仓范畴的概念上入手,美团外卖的离线数仓,也同样是这些。但形式、落地与逻辑,稍有些扩展。
比如,做传统行业的数仓工程师,都知道数据的组织与存储,以关系型结构化数据为基准,以维度模型为扩展。强烈的二维属性已经刻在我们脑子里。即使在二维中硬生生增加多维的扩展模型,本质上还是二维存储。
但在互联网业务中,比如美团外卖。很多业务数据开始有了离散的结构。就好比日志。一个用户的订单,来来回回有多种增删菜品的组合。这样的行为数据,需要入库,对于关系型数据库,极为不便处理。
再举一个例子,用户与商家,用户与用户之间的评论,又是离散的。这样一个主题帖,就像一棵树结构,最好的办法就是将整棵树都存起来。
综合美团外卖的业务,可以将数据分为两部分,一部分是事务性关系型业务数据;另一部分是离散结构,半结构化的业务数据,比如评论,用户行为日志等。
架构
与上篇实时数仓一样,这次的离线数仓,也是先从业务架构入手分析。
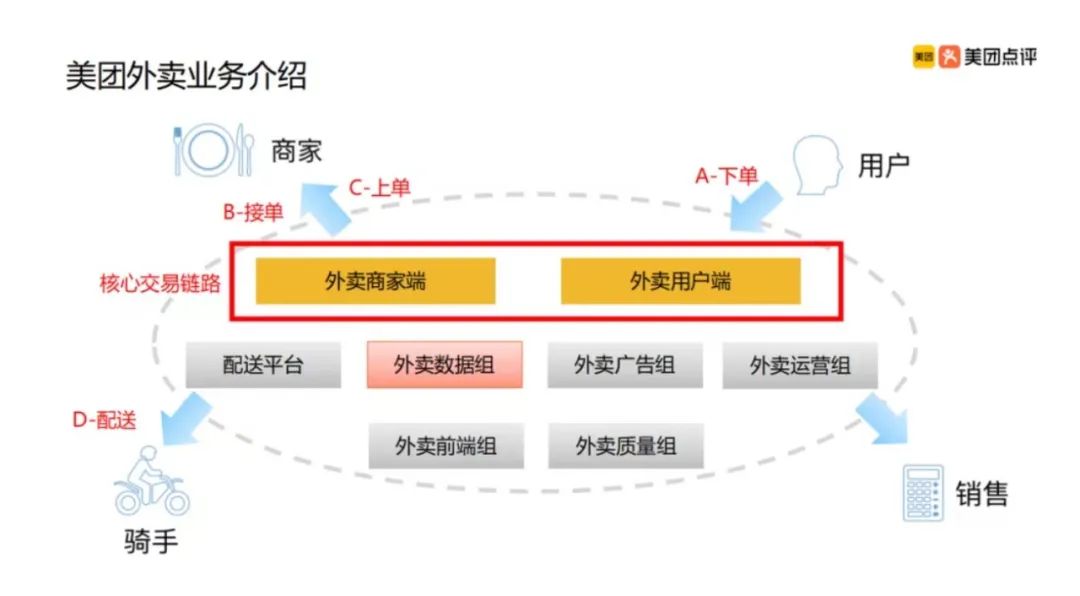
美团的业务图,做得十分清爽。每个业务链路,规划的都很明晰,一目了然。从用户下单,商户上单,骑手接单配送,销售运营,方方面面都考虑在了数据这条生态链上。
业务架构清晰了,数据架构自然也就跟上来了。

在四个数据层,层与层之间的数据交互,都有不同的工具实现。正因工具多变,监控这些工具的数据流是否正常,也是大事。所以,数据流及其流监控手段,还需要加在这幅全景图中。比如 Sqoop, Flume, 以及传统的 ETL 工具。
这里值得关注的是,美团将大量的 Hive ETL 工作都转移到了 Spark 上面。由此可见,将来的趋势,必将给与 Spark 更多机会。那么 Spark 与 Hive 相比,会有哪些明显的优势呢?文中指出,至少有 3 个:
算子丰富,如果是用 Spark 计算库来说,那是真的丰富。比如机器学习算法,HQL 毫无优势。
缓存中间集,不用像 Hive一样,每次都利用硬盘来缓存,是 Spark 最大的优势。
资源复用,申请的计算资源可以重复利用。这先按下不表,因为我也没理解,这优势的本质,在哪里。
转型
美团从传统的数据仓库过度到现代互联网主流数据仓库设计,经历了很长的路程。那么在这些历程中,哪些是关键点,为什么会做出如此的技术选型?看看美团怎么说。
刚开始,2016年以前,美团业务量不大,但竞争激烈。为了配合业务,堆人完成开发。造成的局面一度尴尬:整体开发效率低;统计口径不一;垂直切分技术资源,造成人力浪费。
来看下当时的美团技术架构:
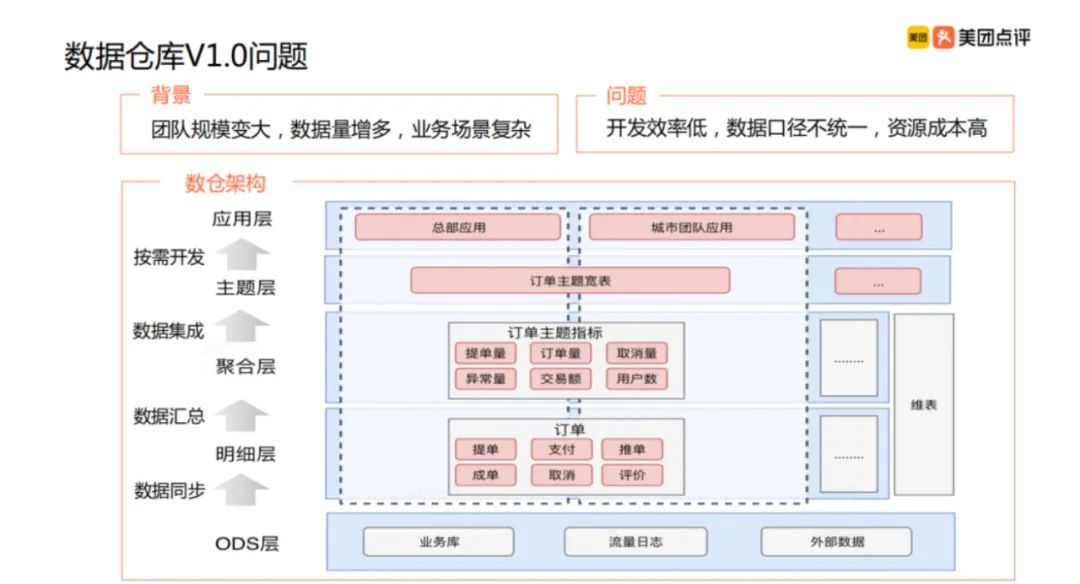
分层也很明晰:ODS\明细\聚合\主题\应用。
ODS层, 这里特别说明下。从各个数据源汇总过来的数据,都会先落在ODS层,有一定的清洗,意味着数据有筛选,更干净,更符合标准格式。
可以看到美团数仓1.0的分层,是以总部+城市来展开的。这种分层,造成的重复计算是毋庸置疑的。很多计算指标都是重合的,总部和城市本身就是地区维度的上下层级关系,完全没必要分开。所以这种分层必须按照业务重新划分。
于是美团 2.0 时代就改变了:
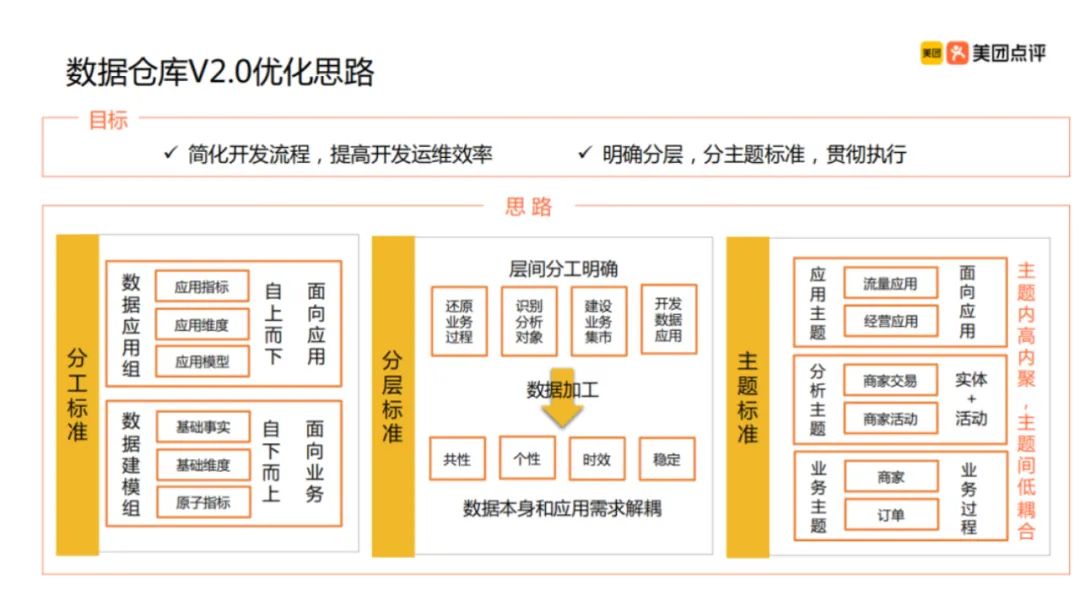
这回,就彻底把分层做足了。按照应用来划分层次,并且在每个层次上又再分层。
其实这里有个很重要的转型时间点。并不是一上来就要精细化开发,把每个主题都安排的妥妥当当。还要看业务发展的势态。
业务早期,稳定性和持久性,还没有突破,过早进入精细化数仓建设,是不合理的。此时要做的事情,完全是辅助业务的开展,在没有准确供给业务所需数据时,就要上一些高大上的数仓指标体系建设,那是浪费资源。
所以,数仓的建设还要围绕着业务去开展,强烈关注业务的开展状态。
一旦业务稳定,势态良好,那么应用就会越来越多,这个时候开展数仓的分层设计,就会顺理成章。
分层
一切围绕业务应用而生,而业务应用,也再一次的分层:业务引导(数据挖掘,推荐)主题;分析(运营分析,财务分析)主题;业务主题(以事实业务过程为基础的分析)。
总的来说,这一层指导和铺垫了底层数据的分层建设,该层也叫主题标准。
这些主题标准切分开来了,但实现这些主题切分的人,还没有定义出来。到底是业务架构,还是技术架构兼任?
不管是谁来做,这样的融合必定是不可少的。懂技术的,并不一定懂业务,懂业务的,不一定懂技术。所以必须有人来双向融合。这大概就是架构师要做的事情。
主题区分开来了,技术的定型也就确定了。以前大家都是拿一块业务,还有可能是同一块业务,垂直的在各自造烟囱。看上去大家都是全栈,实则浪费资源。
此时,将人力资源分层,做建模,做数据应用,团队的资源就不会浪费在同一块地方。比如之前,数据组的每个人都在做商家统计,不同的是一组在处理总部来的需求,二组则在处理每个城市来的需求。其实有些共性的部分,大家可以放在一个模块来完成,不必各自为政。之前的这种团队划分,称之为垂直划分。
而美团数仓2.0,则更多横向划分。从建模到应用,每个段切分,专人专做整个链路的某一段。
从主题到最终的物理层实现,需要两组人马不停的融合。一组人负责不停的处理业务需求建模,另一组人负责物理数据的建模。这两组人一定需要在某个点上达成一致。所以分工标准就出来了,数据应用组和数据建模组。
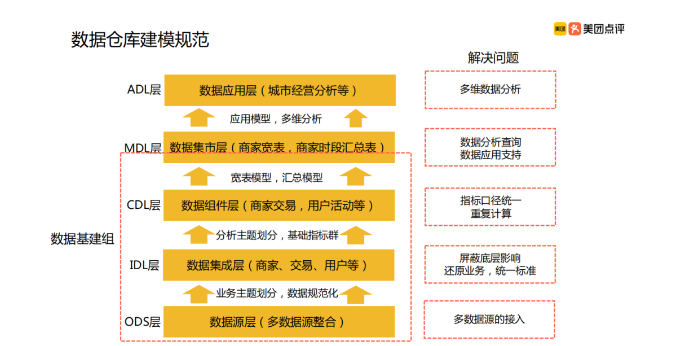
刚才美团数仓1.0,数据分成了四层:ODS/明细/聚合/应用。现在需要将数据分得更细,做更多的解耦。
其实也可以用接单的stage1,stage2,stage3来划分。但每一层做些什么,当然还是要了然于胸。
比如stage1,整合多数据源的一致性建模,完成数据维度,事实组合。stage2,用来完成聚合汇总,进一步按照粒度划分,完成年月日级的聚合。至此,一个中央数据仓库就完成了。stage3,按照业务单元,做数据集市。比如营运,销售。这样提供给数据应用层,就有了完整的数据源。
在数据整合层,要注重排查的两个概念,一是宽表,二是聚合表。宽表与 kimball 的 fact table 不一样,我们通常所说的fact table,实际上仅仅是明细表的统称,而宽表,则是把相关的事实表,都整合到一起,这样的好处,一是加快速度,二是一次查询更加全面。
举个例子说明下大宽表的定义:选定实体对象(比如订单),圈定分析对象(比如订单头,明细,状态,订单召回等),构建宽表模型(通过订单id,将这些表关联到一张表)。
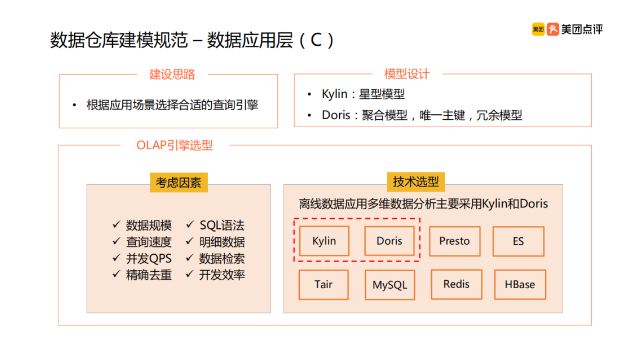
最终的应用层,会简单很多。主要是选型,也就是针对业务数据应用,会选择哪些数据库技术,分析引擎技术,还有报表计算。归纳起来,离不开存储,计算,可视化。
缺陷
美团数据仓库2.0,还是有很多缺点。如下图:
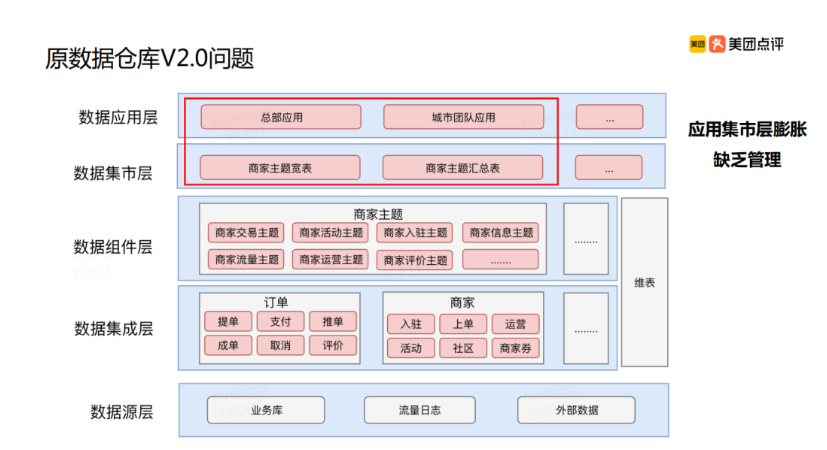
在数据集市层,会过度膨胀。因为层与层之间一旦分割,便会有不同的想法。今天她要这个指标,明天他又要那个指标,其实他俩指标都差不太多,但就是要设计两套,最终导致数据集市层膨胀。而数据仓库3.0就是来解决这样的问题。
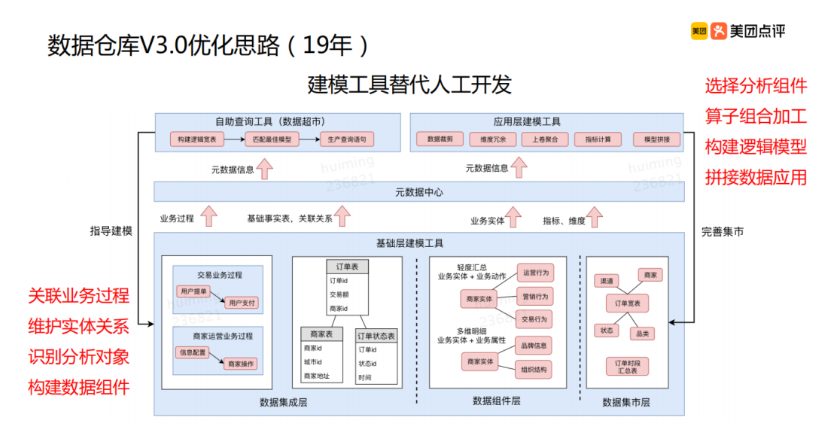
说实话,这是我从来没有想到过的一层。使用建模工具替代人工开发。因为这套玩法,我从来没用过啊。这大概就是美团外卖的先进之处。
文章还提到另一个数据仓库方向是数据治理。它分享了三个小点:数据开发流程,数据安全管理,资源优化。这一块也是我的弱项,下回,我就来盘它!

推荐阅读
欢迎长按扫码关注「数据管道」