
数据仓库系统建设中的工作流及优化
文章作者:翟东波、邢汝峰 搜狐
编辑整理:Hoh
内容来源:作者授权
出品平台:DataFunTalk
注:欢迎转载,转载请留言。
01
数据仓库建设
1. 数据仓库基本概念
数据仓库的概念在 1991 年被美国著名的信息工程专家 William Inmon 博士首次提出,它是数据库技术发展到一定阶段的产物。数据仓库是面向主题的、集成的、稳定的和随时间变化的数据集合,是一个数据分析处理过程,而不仅仅是一个数据存储软件或产品。
OLAP ( On-line Analytical Processing,联机分析处理 ) 是数据仓库中最经常使用的数据处理和分析技术,最早由关系数据库之父 E.F.Codd 于 1993 年提出。OLAP 委员会对联机分析处理的定义为:使分析人员、管理人员或执行人员能够从多种角度对从原始数据中转化出来的、能够真正为用户所理解的、并真实反映企业特性的信息进行快速、一致、交互的存取,从而获得对数据更深入了解的一类软件技术。简单来说,OLAP 就是帮助用户更好的从多个角度去理解现有的数据。
多维模型 ( Multidimensional Model ) 是 OLAP 的数据存储和组织范型,是 OLAP 操作的核心技术。OLAP 基于多维模型定义了一些常见的数据操作,包括下钻 ( Drill-down )、 上卷 ( Roll-up )、切片 ( Slice )、切块 ( Dice ) 以及旋转 ( Pivot ) 使决策者、分析者对数据进行各种分析操作。
维度建模 ( Dimensional Modeling ) 是数据仓库建设中的一种数据建模方法,将数据结构化的逻辑设计方法,它将客观世界划分为度量和上下文,由 Kimball 最先提出这一概念。维度建模属于一种关系建模方法,即将多维模型映射到关系模型,将关系模型中的表分为维度表 ( dimension table ) 和事实表 ( fact table ) 两种,其中维度表表示对分析主题所属类型的描述,而事实表表示对分析主题的度量。
2. 数据仓库建设主要工作
数据仓库体系架构的核心组件有三个:原始数据层,数据仓库,前端应用。如下图所示:
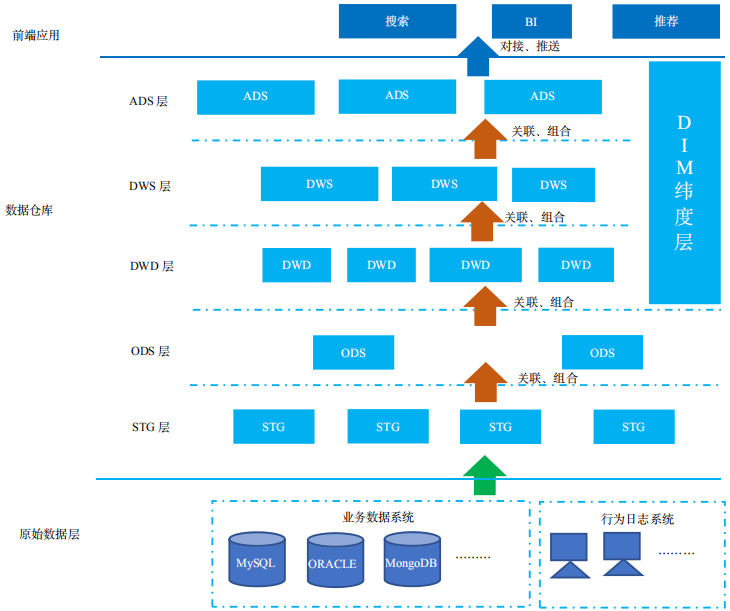
整体来看,数据仓库系统对业务数据和 server 日志等原始数据进行汇聚,数据分析处理后,提供给前端应用系统进行使用,包括 BI ( Business Intelligence )、搜索、推荐等各类应用场景。
在数据仓库系统内部,需要对数据进行分层,主要有如下好处:
防止烟囱式开发,减少重复开发,开发通用中间层数据,减少重复计算;
将复杂问题简单化,将复杂任务的多个步骤分解到各个层次中,每一层只处理较少的步骤,使单个任务更容易理解;
可进行数据血缘追踪,便于快速定位问题;
整个数据层次清晰,每个层次的数据都有职责定位,便于使用和理解。
数据仓库主要分为 STG、ODS、DWD、DWS、ADS 和 DIM 共 6 个层次,数据从底层开始,向上层进行传递、转换、重组等操作,可以理解为,根据数据分析业务的需要,对原有的 OLAP 多维数据,进行维度和指标的重新组合。层次的具体描述如下:
STG原始数据层:用来表示原始数据在数据仓库的落地,数据结构和原始系统发送上来的保持一致。
ODS数据操作层:用于原始数据在数据平台的落地。数据从数据结构、数据之间的逻辑关系上都与原始数据层基本保持一致。在源数据装入这一层时,要进行诸如业务字段提取或去掉不用字段、脏数据处理等等。
DWD数据明细层:用于源系统数据在数据平台中的永久存储。它用以支撑 DWS 层和 ADS 层无法覆盖的需求,比如像用户购买详单类业务需求。这一层主要解决一些数据质量问题和数据的完整度问题。
DWS数据服务层:数据汇总层,该层会在 DWD 层的数据基础上。对数据做轻度的聚合操作,生成一系列的中间表,提升公共指标的复用性,减少重复加工。按照业务划分,如流量、产品、用户等,生成字段比较多的宽表,用于提供后续的业务查询,OLAP 分析,数据分发等。
ADS应用数据层:该层存放数据产品个性化的统计指标数据,一般以某个业务应用为出发点进行建设, ADS 层只关心自己需要的数据,不会全盘考虑企业整体的数据架构和应用。面向实际的业务数据需求,以 DWD 或者 DWS 层的数据为基础,组成各种统计报表。
DIM维度层:主要存储公共的属性数据,比如产品类别、地理位置、时间详情等信息。综上所述,数据仓库建设的主要工作,就是对原始业务数据进行汇聚,进行分层次的数据处理,生成业务需要的数据,提供给前端业务使用。
根据数据层次和数据分析维度,工作流节点通过数据流向依赖在一起;
对于规模稍大的数据仓库,可涉及到多位数开发人员的工作协调;
可以根据数据处理或数据分析工作需要,随时增加工作流节点。
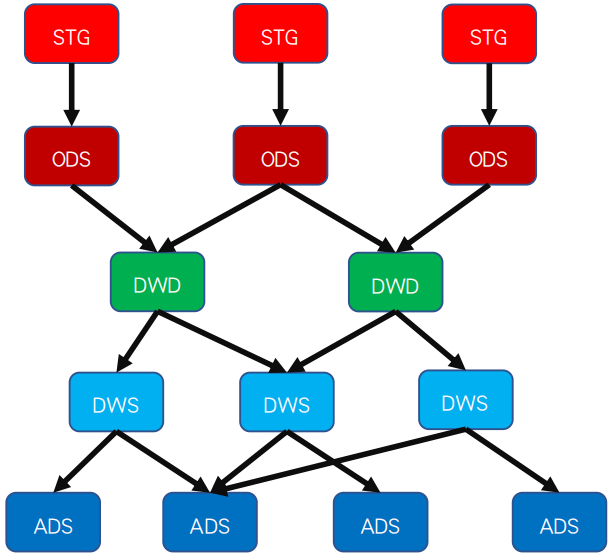
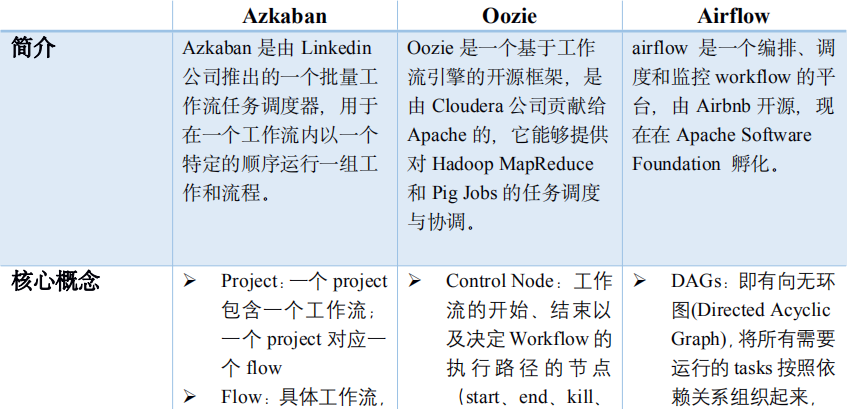



综合来看,目前应用于数据仓库建设场景的工作流管理系统,主要存在以下几个问 题:
都是以工作流为单位进行编辑、管理和发布部署,但是在实际的数据仓库建设过程中,经常是多个数据开发工程师协同完成整个工作流的开发部署工作,每个人只负责部分工作流任务节点,不同开发者的任务相互依赖,现有的工作流管理系统不能很好满足多人的开发协同工作。
针对一些复杂的任务依赖,比如两个任务都是小时调度,小时调度之间存在某种对应关系,现有工作流管理系统都是按任务进行依赖配置,不能做到每个任务不同调度时间之间的依赖配置,或者要写大量的辅助代码实现,给用户带来极大的使用不便。
对于新增或修改 ( 如发现某个统计指标计算有错 ) 的任务节点,经常需要针对这样的任务节点及其子任务节点进行历史数据修补,以工作流为单位进行调度的系统,不太适合这种场景的处理。
计算机系统中软件体系结构采用一种分层的结构,有句名言:"计算机科学领域的 任何问题都可以通过增加一个间接的中间层来解决"。结合数据仓库建设工作的特点,本文所优化的工作流管理系统,将数据仓库建设工作流中的节点,抽象成任务和实例两个层次:数据开发人员专注于单个任务的设计,配置任务的依赖和周期等调度属性,构建任务的工作流;根据任务的依赖和周期属性,工作流管理系统自动生成任务对应的实例,构建实例的工作流。这样可以解决上节中提到的现有开源工作流管理系统的问题,提升开发协同、减少重复性工作。
1. 工作流层次
工作流管理系统将数据仓库建设中的数据处理工作流分成任务和实例两个层次,任务是对实例的抽象,实例是对任务的具化,任务是数据处理的本体,负责创建实例,而实例是具体的执行单元。这样系统就包含两个相互独立又相互关联的工作流,即任务工作流和实例工作流。
① 任务工作流
任务工作流层面,用户根据数据分析的需要,手动增加或修改单个任务。任务除了包括数据处理内容 ( 如 Shell、HIVE SQL、Spark 等代码 ),还要包括依赖和周期等任务属性。通过依赖属性,所有任务可以形成任务工作流 DAG,用户只需定义本任务依赖的父任务 ( 也可依赖自身 ),工作流管理系统会进行相关校验,保证 DAG 属性 ( 如无环等 ) 不被破坏等;通过周期属性,确定任务一天中被调度的次数和时间。
只需要配置依赖和周期属性,便能满足任务依赖自身上一次运行结果或一天中多个时间点要被调度等复杂配置场景,极大简化了任务配置难度。
② 实例工作流
实例工作流层面,工作流管理系统根据任务工作流的任务属性等信息,按照预定的生成规则 ( 规则具体说明参见后面章节 ),创建出任务对应的实例,形成实例工作流。
工作流管理系统根据实例工作流,按照 DAG 方式进行调度,当实例满足如下两个条件时,才能被调度执行:
该实例所有的父实例节点都已完成调度执行;
到达本实例的调度时间。
③ 两者关联
任务工作流是一个静态的工作流,不会被系统调度;实例工作流是任务工作流在某 一时刻的镜像,会被系统调度执行,完成数据处理工作。
工作流管理系统一般按天为单位,在固定时间点生成所有任务一天的所有实例信息, 即依据任务工作流构建实例工作流;也可以按照其他时间间隔单位生成实例,比如以小时为单位,在每个小时的某个时间点,生成所有任务在对应小时时间段的实例信息。
下面两张图为具体的任务工作流和实例工作流,其中左图为任务工作流,右图为实例工作流。
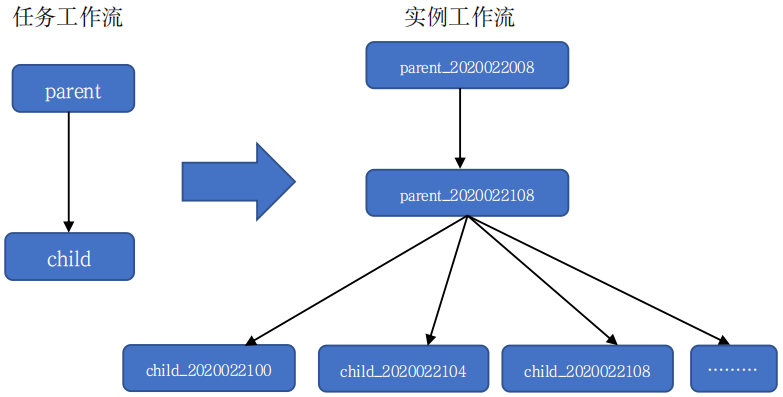
图中 parent 的任务节点,周期属性为天,每天 8 点被调度;依赖属性为自身依赖,即依赖上一天的执行结果。
图中 child 的任务节点,周期属性为小时,从 0 点开始,每隔 4 小时调度一次;依赖属性,parent 为其依赖的父任务节点,即父任务 parent 执行完后,child 任务节点才可以被调度执行。
2. 任务属性
任务属性,主要包括周期属性和依赖属性,工作流管理系统根据这两个属性,将任务工作流转换成实例工作流。
① 周期属性
周期属性用于指定任务的调度周期及具体的调度时间。
调度周期,可以设置为月、周、日、小时等 ( 一般不考虑分钟级别,分钟级别的数据处理任务可以使用 Storm、Flink 或 Spark Streaming 等实时数据处理系统 )。一般设置为日级别周期,即每天都被调度一次;对于月、周级别,需要制定每个月或周的哪几天进行调度,即不是每天都被调度;对于小时级别,需要设定一天当中哪几个小时进行调度,即每天被调度多次。
调度时间,设置任务具体的执行时间。对于月、周、日级别任务,设置一个调度时间即可;对于小时级别任务,需要设置对应的多个调度时间。
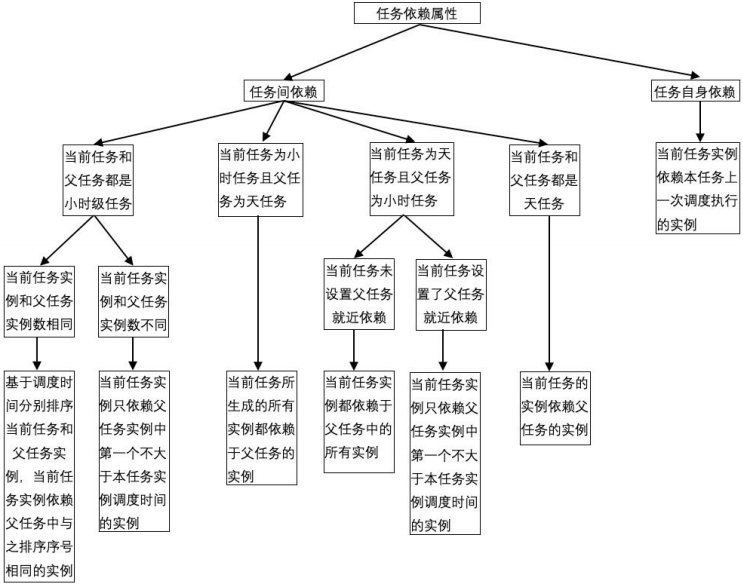
② 依赖属性
依赖属性分为任务间依赖和任务自身依赖:
任务间依赖,用于指定任务的父任务,即上游任务。例如 DWD 层的任务 A,需要用到 ODS 层的任务 B 和 C 产出的数据,在配置任务 A 的任务间依赖属性时,就要设置依赖任务 B 和 C。针对天级别任务依赖小时级别任务的场景,还可以设置就近依赖属性,则子任务调度执行依赖父任务中第一个不小于子任务调度执行时间的调度执行。
任务自身依赖,用于指定任务各周期之间的依赖,当前的调度执行,依赖上一次的调度执行结果。例如某个天级别任务,当天的调度执行就依赖昨天的调度执行结果;某个小时级别任务,每天 8 点和 16 点执行,当天 8 点的调度执行就依赖昨天 16 点的调度执行,当天 16 点的调度执行就依赖当天 8 点的调度执行。
3. 实例生成
工作流管理系统,在设定的时间,根据各个任务的周期和依赖属性,结合预定义的生成规则,生成任务对应的实例,形成实例工作流,用于实际的数据处理任务执行。
① 生成规则
生成规则受到任务的周期和依赖属性影响:
首先根据周期属性生成实例,比如天级任务,根据调度时间每天生成一个实例;小时级任务,根据调度时间,每天生成一个或多个实例;月和周任务,根据调度时间,在对应日期生成一个实例。
然后就是根据依赖属性,构建实例间的依赖关系,具体如下图所示。
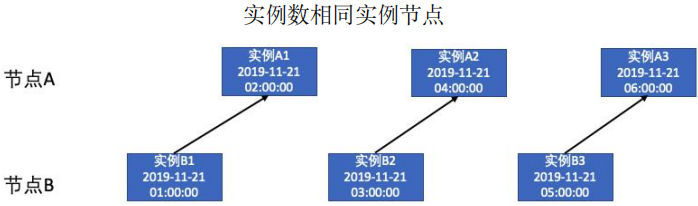
实例数相同:基于调度时间分别排序当前任务和父任务实例,当前任务实例依赖父任务中与之排序序号相同的实例。例如下图,节点 A 中实例 A1 是第一个实例节点,则节点 B 中第一个实例节点实例 B1 就依赖于实例 A1。
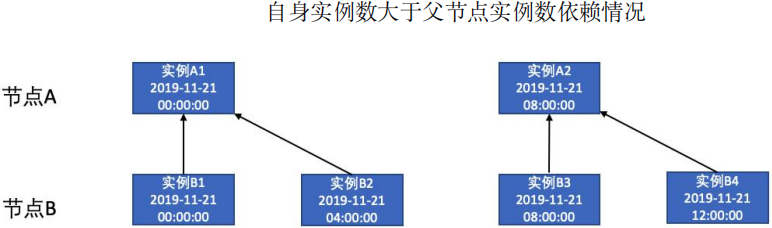
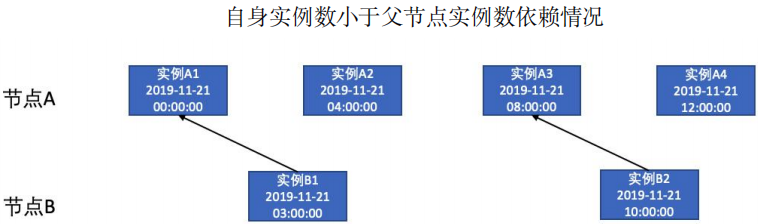
实例数不同:当前任务实例只依赖父任务实例中第一个不大于本任务实例调度时间的实例。例如下图中,在自身实例数大于父节点实例数时,节点 B 中的实例 B1 和实例 B2 都依赖于节点 A 中的 A1,在自身实例数小于父节点实例数时,节点 B 中的实例 B1 会依赖于节点 A 中的实例 A1。
小时任务依赖天任务:
小时任务依赖于天任务即所有小时实例的都依赖于当天执行的天实例。
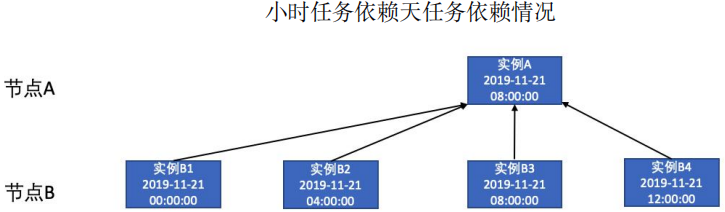
天任务依赖小时任务:
天任务依赖小时任务也可以分为两种,一是天实例依赖父任务生成的全部小时实例,二是天实例就近依赖其自身执行时间节点前父任务执行的最近的一个小时实例。
依赖全部小时实例:
天实例依赖全部小时实例的依赖情况
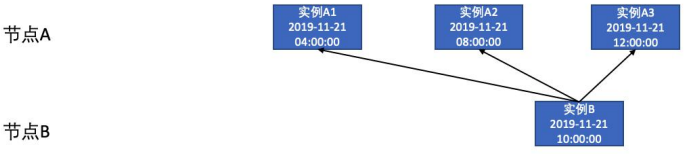
就近依赖小时实例

任务自身依赖:
任务自身依赖可以与任务间依赖一起作用构建实例间依赖关系,任务实例依赖本任务上一次调度执行的实例。例如下图节点 A 为小时任务,且配置自身依赖属性,则 2019-11-21 的实例 1 依赖于 2019-11-20 的实例 24,21 号的实例 2 依赖于 21 号的实例 1。

4. 优化效果
通过上述的方案,将数据仓库建设中的工作流节点,抽象成任务和实例两个层次,可达到以下的优化效果:
配置工作流任务节点时,无需变更整个工作流配置信息,只需配置当前任务节点的周期和依赖属性等内容,提升工作流配置灵活性;
通过任务的周期和依赖属性,可以生成复杂的实例依赖关系,降低工作流节点依赖配置的复杂度;
能够以某个任务节点为根节点,构造子工作流 ( 包含此任务节点,及其子任务节点、孙子任务节点等 ),覆盖历史数据修复等场景。
本文主要根据数据仓库建设过程中的 workflow 相关特点,将 workflow 中的节点抽象成任务和实例两个层次,用户只需要定义任务的周期属性和依赖属性,workflow 管理系统根据任务的这些属性自动转换成实例间的依赖,提升数据仓库工作流管理系统的易用性。当然,数据仓库工作流管理系统不仅仅包含本文描述的任务依赖和调度管理,还包括数据质量监控、数据处理任务追踪、数据处理流程优化等等,需要深入融合 workflow 和数据仓库两个技术领域,提升数据仓库建设工作的效率。