
带你探寻 Hive 背后的执行机制和原理
前言
我们都知道,Hive SQL 实际上是翻译为 MapReduce 执行的, 那么它具体过程如何呢?今天我们就来探寻一下 Hive SQL 背后的执行机制和原理。
要知道,进一步理解和掌握 Hive SQL 的执行原理对于平时离线任务的开发和优化非常重要,直接关系到 Hive SQL 的执行效率和时间。
一、Hive 基本架构
作为基于 Hadoop 主要数据仓库解决方案, Hive SQL 是主要的交互接口,实际的数据保存在 HDFS 文件中,真正的计算和执行则由 MapReduce 完成,它们之间的桥梁是 Hive 引擎。
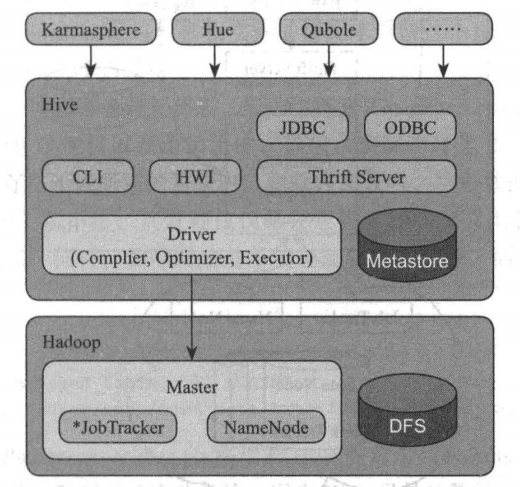 Hive 主要组件包括 UI 组件、 Driver 组件( Complier Optimizer Executor )、 Metastore组件、 CLI ( Command Line Interface ,命令行接口)、 JDBC/ODBC 、Thrift Server 和 Hive Web Interface (HWI )等。
Hive 主要组件包括 UI 组件、 Driver 组件( Complier Optimizer Executor )、 Metastore组件、 CLI ( Command Line Interface ,命令行接口)、 JDBC/ODBC 、Thrift Server 和 Hive Web Interface (HWI )等。

Hive 就是通过 CLI 、JDBC / ODBC 或者 HWI 接收相关的 Hive SQL 查询,并通过 Driver 组件进行编译,分析优化,最后变成可执行的 MapReduce。

二、Hive SQL
Hive SQL 是类似于 ANSI SQL 标准的SQL 语言,但两者又不完全相同。Hive SQL 和 MySQL 的 SQL 语言最为接近,但两者之间也存在显著差异,比如 Hive 不支持行级数据插人、更新和删除,也不支持事务等。
Hive 关键概念
1. Hive 数据库
Hive 中的数据库从本质上来说仅仅是一个目录或者命名空间,但是对于具有很多用户和组的集群来说,这个概念非常有用 。
首先,这样可以避免表命名冲突;其次,它等同于关系型数据库中的数据库概念,是一组表或者表的逻辑组,非常容易理解。
2. Hive 表
Hive 中的表( Table )和关系数据库中的 table 在概念上是类似的,每个 table 在 Hive 中都有一个相应的目录存储数据,如果没有指定表的数据库,那么 Hive 会通过{HIVE_HOME} /conf/hive-site.xml 配置文件中的 hive.metastore.warehouse.dir 属性来使用默认值(一般是 /user/hive/warehouse ,也可以根据实际的情况来修改这个配置),所有的 table 数据(不包括外部表) 都保存在这个目录中。
Hive 表分为两类,即内部表和外部表。所谓内部表(managed table) 即 Hive 管理的表,Hive 内部表的管理既包含逻辑以及语法上的,也包含实际物理意义上的,即创建 Hive 内部表时,数据将真实存在于表所在的目录内,删除内部表时,物理数据和文件也一并删除。
「那么到底是选择内部表还是外部表呢?」
大多数情况下,这两者的区别不是很明显。如果数据的所有处理都在 Hive 中进行,那么更倾向于选择内部表。但是如果 Hive 和其他工具针对相同的数据集做处理,那么外部表更合适。
一种常见的模式是使用外部表访问存储的 HDFS (通常由其他工具创建)中的初始数据,然后使用 Hive 转换数据并将其结果放在内部表中。相反,外部表也可以用于将 Hive 的处理结果导出供其他应用使用。
使用外部表的另一种场景是针对一个数据集,关联多个 Schema。
3. 分区和桶
Hive 将表划分为分区(partition),partition 根据分区字段进行。分区可以让数据的部分查询变得更快 。表或者分区可以进一步被划分为桶( bucket)。桶通常在原始数据中加入一些额外的结构,这些结构可以用于高效查询。
例如 ,基于用户 ID 的分桶可以使基于用户的查询非常快。
( 1 )分区
假设日志数据中,每条记录都带有时间戳 。如果根据时间来分区,那么同一天的数据将被划分到同一个分区中。
分区可以通过多个维度来进行。例如,通过日期划分之后,还可以根据国家进一步划分。
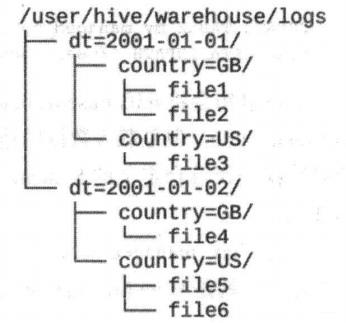
分区在创建表的时候使用 PARTITIONED BY 从句定义,该从句接收一个字段列表:
CREATE TABLE logs (ts BIGINT , line STRING)
PARTITIONED BY (dt STRING,country STRING);
当导入数据到分区表时,分区的值被显式指定:
LOAD DATA INPATH ’/user/root/path’
INTO TABLE logs
PARTITION (dt='2001-01-01',country='GB’);
实际 SQL 中,灵活指定分区将大大提高其效率,如下代码将仅会扫描 2001-01-01下的 GB 目录。
SELECT ts , dt , line FROM logs WHERE dt=‘2001-01-01' and country='GB'
( 2 )分桶
在表或者分区中使用桶通常有两个原因:
一是为了高效查询 。桶在表中加入了特殊的结果, Hive 在查询的时候可以利用这些结构提高效率。例如,如果两个表根据相同的字段进行分桶,则在对这两个表进行关联的时候,可以使用 map-side 关联高效实现,前提是关联的字段在分桶字段中出现。 二是可以高效地进行抽样。在分析大数据集时,经常需要对部分抽样数据进行观察和分析,分桶有利于高效实现抽样。
为了让 Hive 对表进行分桶,通过 CLUSTERED BY 从句在创建表的时候指定:
CREATE TABLE bucketed users(id INT, name STRING)
CLUSTERED BY (id) INTO 4 BUCKETS;
指定表根据 id 字段进行分桶,并且分为 4 个桶 。分桶时, Hive 根据字段哈希后取余数来决定数据应该放在哪个桶,因此每个桶都是整体数据的随机抽样。
在 map-side 的关联中,两个表根据相同的宇段进行分桶,因此处理左边表的 bucket 时,可以直接从外表对应的 bucket 中提取数据进行关联操作。map-side 关联的两个表不一定需要完全相同 bucket 数量,只要成倍数即可。
需要注意的是, Hive 并不会对数据是否满足表定义中的分桶进行校验,只有在查询时出现异常才会报错 。因此,一种更好的方式是将分桶的工作交给 Hive 来完成(设 hive.enforce.bucketing 属性为 true 即可)。
Hive DDL
1. 创建表
CREATE TABLE:用于创建一个指定名字的表 。如果相同名字的表已经存在,则抛出异常 用户可以用 IF NOT EXIST 选项来忽略这个异常。 EXTERNAL :该关键字可以让用户创建一个外部表,在创建表的同时指定一个指向实际数据的路径(LOCATION)。 COMMENT :可以为表与字段增加描述。 ROW FORMAT :用户在建表的时候可以自定义 SerDe 或者使用自带的 SerDe。 STORED AS :如果文件数据是纯文本,则使用 STORED AS TEXTFILE ;如果数据需要压缩, 则使用 STORED AS SEQUENCE 。 LIKE: 允许用户复制现有的表结构,但是不复制数据。
hive> CREATE TABLE empty key value store
LIKE key value store;
还可以通过 CREATE TABLE AS SELECT 的方式来创建表,示例如下:
Hive> CREATE TABLE new key value store
ROW FORMAT
SERDE "org.apache.Hadoop.hive.serde2.columnar.ColumnarSerDe"
STORED AS RCFile
AS
SELECT (key % 1024) new_key, concat(key, value) key_value_pair
FROM key_value_store
SORT BY new_key, key_value_pair;
2. 修改表
修改表名的语法如下:
hive> ALTER TABLE old_table_name RENAME TO new_table_name;
修改列名的语法如下:
ALTER TABLE table_name CHANGE (COLUMN) old_col_name new_col_name column_type
[COMMENT col_comment) (FIRST|AFTER column_name)
上述语法允许改变列名 数据类型 注释 列位 它们的任意组合 建表后如果要新增一列,则使用如下语法:
hive> ALTER TABLE pokes ADD COLUMNS (new_col INT COMMENT 'new col comment');
3. 删除表
DROP TABLE 语句用于删除表的数据和元数据 。对于外部表,只删除 Metastore 中的元数据,而外部数据保存不动,示例如下:
drop table my_table;
如果只想删除表数据,保留表结构,跟 MySQL 类似,使用 TRUNCATE 语句:
TRUNCATE TABLE my_table;
4. 插入表
( 1 )向表中加载数据
相对路径的示例如下:
hive> LOAD DATA LOCAL INPATH ’./exarnples/files/kvl.txt ’ OVERWRITE INTO
TABLE pokes;
( 2 )将查询结果插入 Hive
将查询结果写入 HDFS 文件系统。
INSERT OVERWRITE TABLE tablenamel [PARTITION (partcoll=val1, partcol2=val2 ... )]
select_statement1 FROM from_statement
这是基础模式,还有多插入模式和自动分区模式,这里就不再叙述。
Hive DML
1. 基本的 select 操作
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[ CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY | ORDER BY col_list]
]
[LIMIT number]
使用 ALL、 DISTINCT 选项区分对重复记录的处理 。默认是 ALL ,表示查询所有记录, DISTINCT 表示去掉重复的记录 WHERE 条件:类似于传统 SQL的 where 条件,支持 AND 、OR 、BETWEEN、 IN 、NOT IN 等 ORDER BY 与 SORT BY 的不同:ORDER BY 指全局排序,只有一个 Reduce 任务,而 SORT BY 只在本机做排序 LIMIT :可以限制查询的记录数,如 SELECT * FROM tl LJMIT5 ,也可以实现 Topk 查询,比如下面的查询语句可以查询销售记录最多的 5个销售代表
SET mapred.reduce.tasks = 1
SELECT * FROM test SORT BY amount DESC LIMIT 5
REGEX Column Specification : select 语句可以使用正则表达式做列选择,下面的语句查询除了 ds 和 hr 之外的所有列
SELECT `(ds|hr)?+.+` FROM test
2. join 表
join_table:
table_reference (INNER] JOIN table_factor (join_condition]
| table_reference {LEFTIRIGHTjFULL} (OUTER] JOIN table_reference join_ condition
| table_reference LEFT SEM JOIN table_reference join_condition
| table_reference CROSS JOIN table_reference (join_condition] (as of Hive 0.10)
table reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| (table_references)
join_condition:
on expression
Hive中只支持等值连接,外连接和左半连接(left semi join),(从2.2.0版本后支持非等值连接); 可以连接2个以上的表,如:
select a.val, b.val,c.val
from a
join b
on (a.key=b.key1)
join c
on(c.key = b.key2);
如果连接中多个表的join key是同一个,则连接会被转化为单个Map/Reduce任务
select a.val,b.val,c.val
from a
join b
on (a.key=b.key1)
join c
on(c.key=b.key1);
join时大表放在最后: Reduce会缓存join序列中除最后一个表之外的所有表的记录,再通过最后一个表将结果序列化到文件系统 如果想限制join的输出, 应该在where子句中写过滤条件,或是在join子句中写。 但是有表分区的情况,比如下面的第一个 SQL 语句所示,如果d表中找不到对应c表的记录, d表的所有列都会列出 NULL ,包括 ds列。也就是说, join 会过滤d表中不能找到匹配c表 join key 的所有记录。这样, LEFT OUTER 就使得查询结果与 WHERE 子句无关,解决办法是在join 时指定分区(如下面的第二个 SQL 语句所示)
--第一个 SQL 语句
SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key)
WHERE a.ds='2010-07-07' AND b.ds='2010-07-07'
-- 第二个 SQL 语句
SELECT c.val, d.val FROM c LEFT OUTER JOIN d
ON (c.key=d.key AND d.ds=’ 2009-07-07 ’ AND c.ds='2009-07-07')
left semi join是in/exists子查询的一种更高效的实现,join子句中右边的表只能在on子句中设置过滤条件,在where子句、select子句中或其他方式过滤都不行
SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key FROM B);
--可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
三、Hive SQL 执行原理图解
我们都知道,一个好的的 Hive SQL 和写得不好的 Hive SQL ,对底层计算和资源的使用可能相差百倍甚至千倍、万倍。
除了资源的浪费,不恰当地使用 Hive SQL 可能会运行几个小时甚至十几个小时都得不到运算结果。因此,我们深入的理解 Hive SQL 的执行过程和原理是非常有必要的。
以 group by 语句执行图解为例:
我们假定一个业务背景:分析购买iPhone7客户在各城市中的分布情况,即哪个城市购买得最多、哪个最少。
select city,count(order_id) as iphone7_count from orders_table where day='201901010' and cat_name='iphone7' group by city;
底层MapReduce执行过程:

Hive SQL 的 group by 语句涉及数据的重新分发和分布,因此其执行过程完整地包含了 MapReduce 任务的执行过程。
( 1 )输入分片
group by 语句的输入文件依然为 day=20170101 的分区文件,其输入分片过程和个数同 select 语句,也是被分为大小分别为:128MB 、128MB、44MB 三个分片文件。
( 2 ) Map 阶段
Hadoop 集群同样启动三个 Map 任务,处理对应的三个分片文件;每个 map 任务处理其对应分片文件中的每行,检查其商品类目是否为 iPhone7 ,如果是,则输出形如
( 3 ) Combiner 阶段
Combiner 阶段是可选的,如果指定了 Combiner 操作,那么 Hadoop 会在 Map 任务的地输出中执行 Combiner 操作,其好处是可以去除冗余输出,避免不必要的后续处理和网络传输开销等 此列中,Map Task1 的输出中< hz,1>出现了两次,那么 Combiner 操作就可以将其合并为 Combiner 操作是有风险的,使用它的原则是 Combiner 的输出不会影响到 Reduce 计算的最终输入。例如,如果计算只是求总数、最大值和最小值,可以使用 combiner ,但是如果做平均值计算使用了 Combiner ,最终的 Reduce 计算结果就会出错
( 4 ) Shuffle 阶段
完整的shuffle包括分区(partition),排序(sort)和分隔(spill)、复制(copy)、合并(merge)等过程。
对于理解group by语句,关键的过程实际就两个,即分区和合并;所谓分区,即 Hadoop 如何决定将每个 Map 任务的每个输出键值对分配到那个 Reduce Task 所谓合井,即在 一个Reduce Task 中,如何将来自于多个 Map Task 的同样一个键的值进行合并 Hadoop 中最为常用的分区方法是 Hash Partitioner ,即 Hadoop 会对每个键取 hash 值,然后再对此 hash 值按照 reduce 任务数目取模,从而得到对应的 reduce ,这样保证相同的键,肯定被分配到同一个 reduce 上,同时 hash 函数也能确保 Map 任务的输出被均匀地分配到所有的 Reduce务上
( 5 )Reduce 阶段
调用reduce函数,每个reduce任务的输出存到本地文件中
( 6 )输出文件
hadoop 合并 Reduce Task任务的输出文件到输出目录
四、小结
我们介绍了 Hive SQL 的执行原理。当然了,要知其然,并要知其所以然,理解 Hive 的执行原理是写高效 SQL 的前提和基础,也是掌握 Hive SQL 优化技巧的根本,接下来我们就要进入 Hive 优化实践的环节啦。